Robots.txt là một tệp quan trọng giúp kiểm tra robots.txt bằng Screaming Frog và các công cụ tìm kiếm hiểu được những URL nào được phép thu thập dữ liệu trên website. Tất cả các bot từ những công cụ tìm kiếm lớn đều tuân thủ tiêu chuẩn robots exclusion (robots exclusion standard) và sẽ đọc cũng như tuân theo các chỉ dẫn trong tệp robots.txt trước khi thu thập dữ liệu các URL khác trên trang.
Các chỉ thị trong robots.txt có thể được thiết lập dành cho từng robot cụ thể dựa trên User-agent của chúng (ví dụ như Googlebot). Trong đó, lệnh phổ biến nhất là “Disallow”, có tác dụng thông báo cho robot không được phép truy cập vào một đường dẫn URL nhất định.
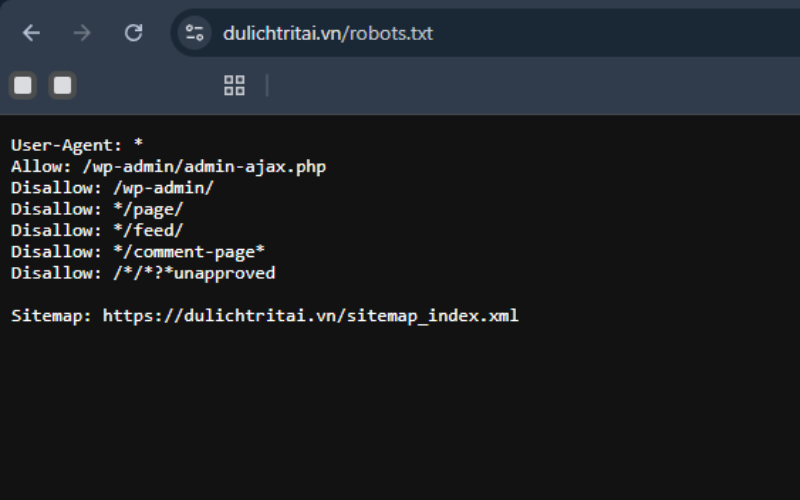
Bạn có thể xem tệp robots.txt của bất kỳ trang web nào bằng cách thêm “/robots.txt” vào sau tên miền (ví dụ: https://dulichtritai.vn/robots.txt ).
Mặc dù tệp robots.txt thường khá dễ hiểu, khi có nhiều dòng lệnh, nhiều User-agent và nhiều chỉ thị, đặc biệt với hàng nghìn trang, việc xác định chính xác những URL bị chặn hay được phép thu thập dữ liệu sẽ trở nên phức tạp. Việc vô tình chặn nhầm các URL quan trọng có thể ảnh hưởng nghiêm trọng đến khả năng hiển thị của website trên công cụ tìm kiếm.
Lúc này, công cụ kiểm tra robots.txt như phần mềm Screaming Frog SEO Spider, kèm tính năng Custom Robots.txt, trở nên rất hữu ích. Công cụ này giúp bạn kiểm tra và xác thực tệp robots.txt của website một cách toàn diện và trên quy mô lớn.
Trước tiên, bạn cần tải công cụ SEO Spider. Phiên bản miễn phí của Screaming Frog cho phép thu thập tối đa 500 URL. Để sử dụng các tính năng nâng cao hơn, như Custom Robots.txt, bạn sẽ cần bản trả phí.
Bạn có thể làm theo các bước trong hướng dẫn của Lenart để kiểm tra file robots.txt của một website đang hoạt động. Nếu muốn kiểm tra các chỉ thị robots.txt chưa áp dụng hoặc thử nghiệm cú pháp lệnh riêng cho robot, hãy tham khảo thêm mục 3 trong hướng dẫn, về tính năng Custom Robots.txt.
Hướng dẫn kiểm tra robots.txt bằng Screaming Frog SEO Spider
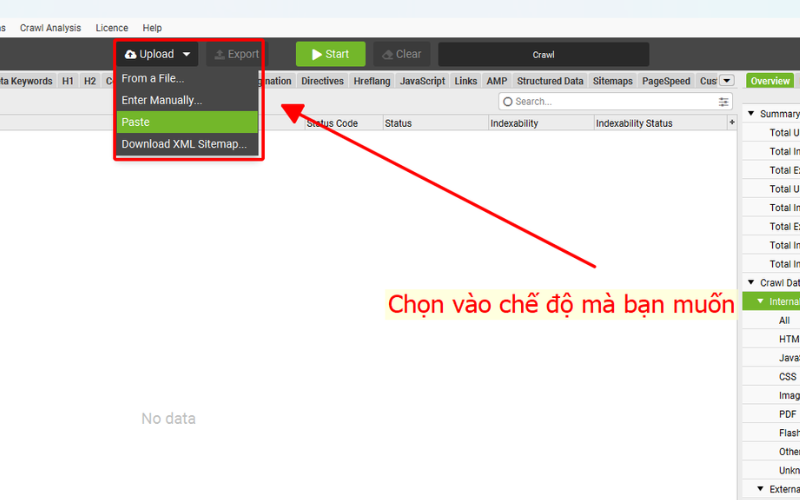
Khi kiểm tra robots.txt bằng Screaming Frog bằng cách chọn Mode > List > Upload > Start. Tại đây, phần mềm cung cấp nhiều chế độ để phù hợp với việc kiểm tra robots.txt của bạn, bao gồm:
- Form the file: Tải lên trực tiếp file danh sách URL (ví dụ file .txt hoặc .csv) đã chuẩn bị sẵn để kiểm tra.
- Enter Manually: Nhập thủ công danh sách URL từng dòng vào ô nhập liệu trên phần mềm.
- Paste: Dán danh sách URL sao chép từ tài liệu hoặc nguồn khác thẳng vào phần mềm.
- Download XML sitemap: Tải trực tiếp sitemap XML của website để công cụ thu thập và kiểm tra trên các URL có trong sitemap đó.
Phương pháp này rất phù hợp khi bạn muốn test nhóm trang cụ thể, ví dụ như trang sản phẩm mới hoặc bài viết blog, trước khi tiến hành thu thập dữ liệu toàn diện.
Kiểm tra tab “Response Codes” và bộ lọc “Blocked by Robots.txt”
Trong quá trình thu thập dữ liệu (crawl), các URL bị chặn bởi robots.txt sẽ được gắn trạng thái “Blocked by Robots.txt” trong cột Status.
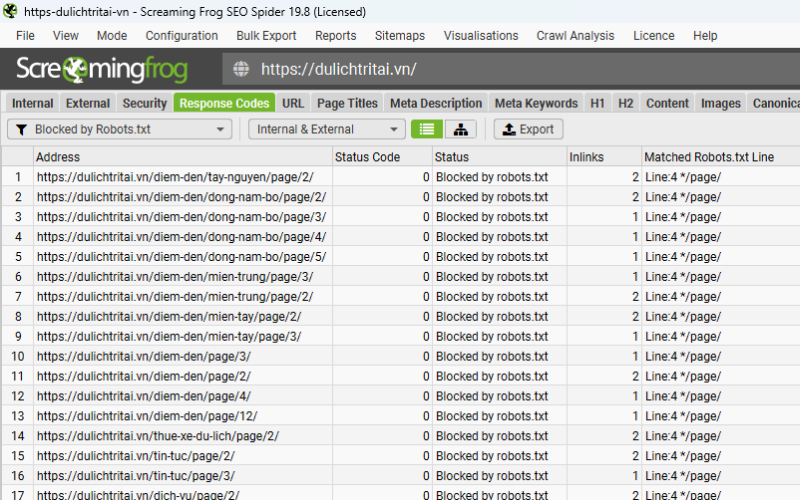
Tại bộ lọc này, cột “Matched Robots.txt Line” sẽ hiển thị chính xác số dòng và quy tắc Disallow đang ngăn chặn từng URL.

Để kiểm tra những trang có liên kết trỏ đến URL bị chặn, bạn chỉ cần chuyển sang tab “Inlinks” — dữ liệu chi tiết sẽ xuất hiện ngay trong khung hiển thị phía dưới giao diện.
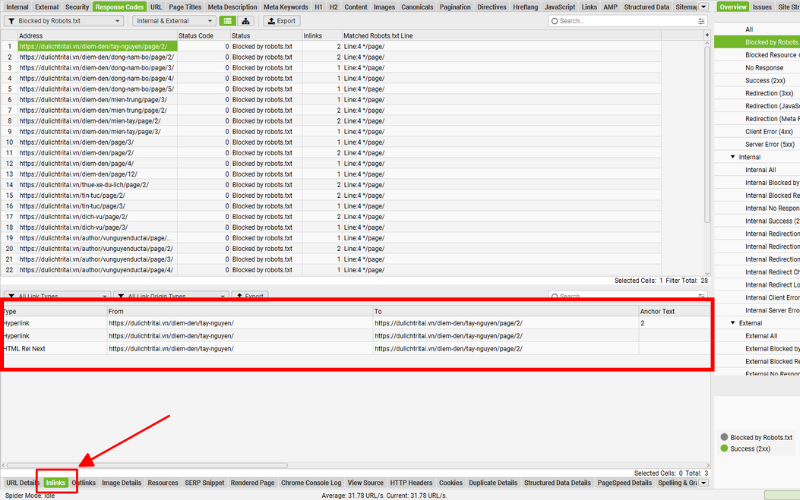
Toàn bộ thông tin về liên kết nội bộ này có thể được xuất ra thành file chỉ với một thao tác thông qua báo cáo:
Chọn Bulk Export > Response Codes > Blocked by Robots.txt Inlinks
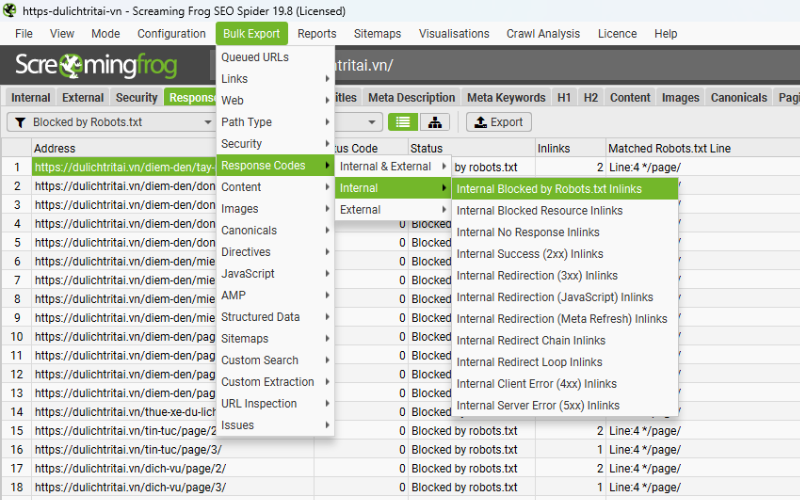
Test quy tắc với Custom Robots.txt
Với phiên bản trả phí, bạn có thể tải về, chỉnh sửa và thử nghiệm tệp robots.txt ngay trong Screaming Frog, hỗ trợ việc kiểm tra robots.txt bằng Screaming Frog tiện lợi qua menu ‘Configuration > Robots.txt > Custom’.
Tính năng này hỗ trợ:
- Thêm nhiều tệp robots.txt riêng cho từng subdomain.
- Kiểm tra ngay lập tức các quy tắc chặn/mở trong giao diện SEO Spider.
- Xem danh sách URL bị cấm hoặc được phép theo tệp mới.
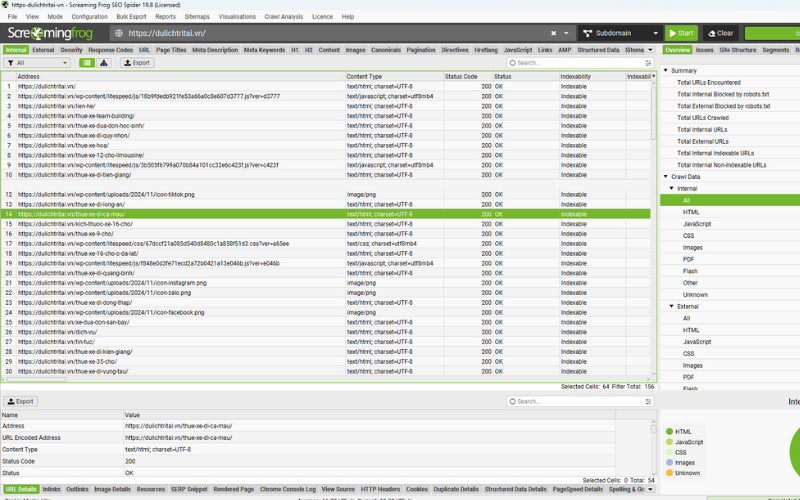
Sau khi crawl, bạn lọc URL bị chặn bằng bộ lọc ‘Response Codes > Blocked by robots.txt’ và kiểm tra dòng quy tắc đang áp dụng theo bộ lọc.

Tệp Custom sẽ dùng User-agent bạn chọn trong phần cấu hình, dễ dàng chuyển đổi để test cho bất kỳ bot nào. Nhưng lưu ý các thay đổi quan trọng trong SEO Spider không ảnh hưởng đến tệp robots.txt đang chạy trên server. Khi đã chọn những cột đúng ý, bạn chỉ cần copy nội dung để cập nhật lên môi trường thực tế.
Cách Screaming Frog SEO Spider tuân thủ robots.txt
Screaming Frog SEO Spider tuân thủ robots.txt tương tự như Google. Công cụ sẽ kiểm tra tệp robots.txt của từng subdomain và lần lượt áp dụng các chỉ thị (cho phép hoặc chặn) dành riêng cho User-agent ‘Screaming Frog SEO Spider’, nếu không có thì đến Googlebot, rồi đến tất cả các robot (ALL robots).
Các URL bị chặn trong robots.txt vẫn sẽ xuất hiện và được “đánh dấu” trong giao diện với trạng thái ‘Blocked by Robots.txt’, nhưng sẽ không được thu thập dữ liệu, nên nội dung và liên kết đi (outlinks) của trang đó sẽ không hiển thị. Bạn có thể tắt hiển thị các liên kết nội bộ hoặc liên kết ngoài bị chặn bởi robots.txt trong phần cài đặt robots.txt của công cụ.
Cần lưu ý rằng URL bị chặn bởi robots.txt vẫn có thể được lập chỉ mục trên công cụ tìm kiếm nếu chúng được liên kết từ bên trong hoặc bên ngoài website. Robots.txt chỉ chặn công cụ tìm kiếm truy cập nội dung trang, nhưng không ngăn trang được lập chỉ mục. Để loại bỏ hoàn toàn nội dung khỏi chỉ mục, bạn nên dùng thẻ noindex hoặc X-Robots-Tag.
Công cụ này cũng hỗ trợ khớp URL với các ký tự đại diện như * và $, hoạt động tương tự Googlebot.
Ví dụ phổ biến về Robots.txt
Dấu sao (*) đi kèm với lệnh ‘User-agent’ (User-agent: *) chỉ ra rằng các chỉ thị áp dụng cho TẤT CẢ các robot, trong khi các User-agent cụ thể cũng có thể được dùng cho những lệnh riêng biệt (chẳng hạn User-agent: Googlebot).
Nếu các lệnh được áp dụng cho cả nhóm tất cả và từng User-agent cụ thể, thì các lệnh chung cho tất cả sẽ bị bỏ qua bởi User-agent cụ thể và chỉ những chỉ thị riêng của nó được tuân theo. Nếu bạn muốn các chỉ thị chung được tuân thủ, bạn phải đưa các dòng đó vào phần dành cho User-agent cụ thể đó.
Dưới đây là một số ví dụ phổ biến về các chỉ thị thường dùng trong robots.txt.
Chặn tất cả robots khỏi tất cả các URL
User-agent: *
Disallow: /
Chặn tất cả robots khỏi một thư mục cụ thể
User-agent: *
Disallow: /folder/
Chặn tất cả robots khỏi một URL cụ thể
User-agent: *
Disallow: /a-specific-url.html
Chặn Googlebot khỏi tất cả các URL
User-agent: Googlebot
Disallow: /
Kết hợp lệnh Block (Disallow) và Allow cùng nhau
User-agent: Googlebot
Disallow: /
Allow: /crawl-this/
Nếu bạn có các chỉ thị mâu thuẫn (ví dụ: Allow và Disallow cùng áp dụng cho một đường dẫn tệp giống nhau), thì chỉ thị Allow sẽ được ưu tiên hơn chỉ thị Disallow nếu nó chứa cùng số lượng hoặc nhiều ký tự khớp hơn trong lệnh.
Sử dụng ký tự đại diện (wildcards) trong robots.txt
Cả Google và Bing đều cho phép dùng ký tự đại diện (wildcards) trong tệp robots.txt.
Ví dụ 1 – Chặn mọi URL chứa dấu ?:
User-agent: *
Disallow: /*?
Ví dụ 2 – Chặn các tệp kết thúc bằng .html:
User-agent: *
Disallow: /*.html$
Ký tự $ đảm bảo khớp chính xác phần cuối của URL.
Chi tiết về cách dùng giá trị đường dẫn và các quy tắc khớp, bạn có thể tham khảo trong hướng dẫn chính thức về robots.txt của Google.
Tổng kết
Tệp robots.txt tuy nhỏ nhưng lại giữ vai trò rất quan trọng trong việc quản lý và tối ưu SEO cho website. Đây là nơi giúp các công cụ tìm kiếm hiểu được khu vực nào của website được phép thu thập dữ liệu và khu vực nào cần hạn chế truy cập, giúp website của bạn hoạt động hiệu quả, bảo mật và thân thiện hơn với Google.
Đó là lý do tại sao SEOLENART luôn khuyến khích các quản trị viên và người làm SEO thường xuyên kiểm tra robots.txt bằng Screaming Frog. Công cụ này giúp bạn xác định chính xác các lệnh Disallow hoặc Allow, phát hiện lỗi cú pháp và đảm bảo rằng các bot tìm kiếm có thể truy cập đúng vào những phần quan trọng nhất của website.









