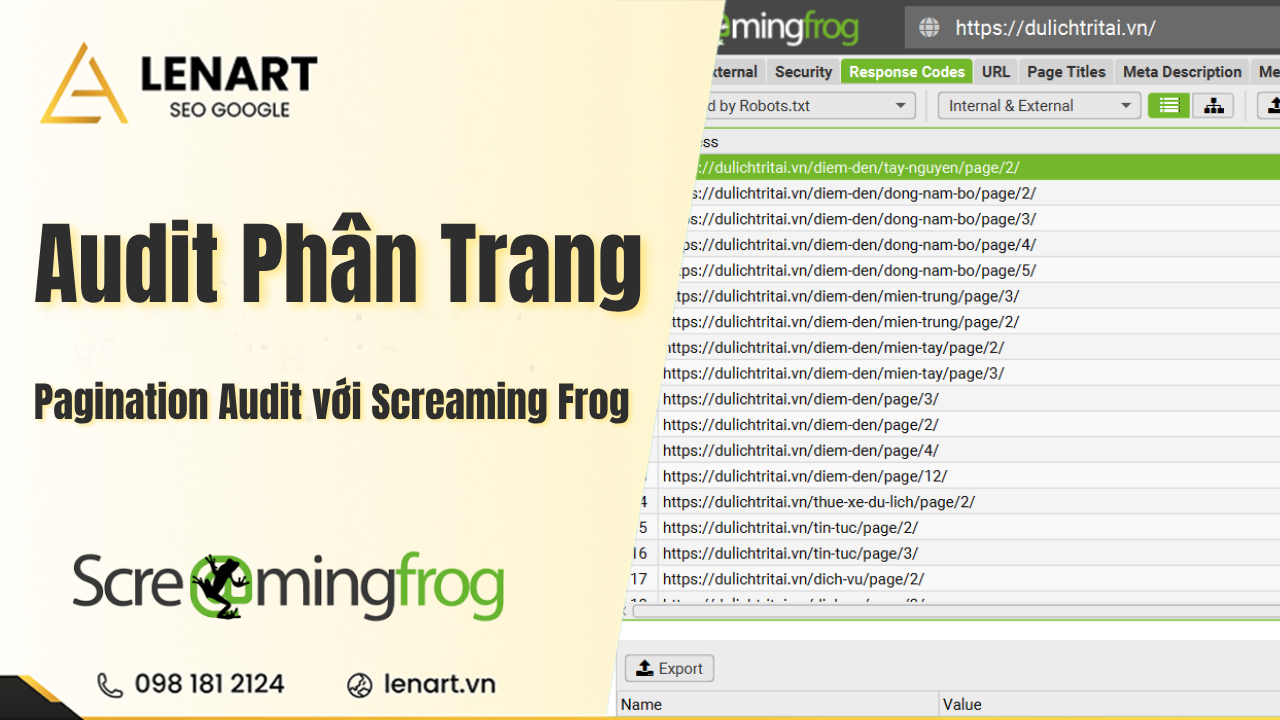
robots.txt là xong. Đơn giản, dễ làm. Nhưng hóa ra, đó là một hiểu lầm tai hại!robots.txt không phải là một công cụ bảo mật, càng không phải là lệnh cấm tuyệt đối. Nó là một tệp văn bản nhỏ nhưng lại nắm giữ vai trò quan trọng trong việc quản lý tài nguyên của Google trên website của bạn – hay giới chuyên môn gọi là Tối ưu Crawl Budget (Ngân sách thu thập dữ liệu).Trong bài viết này, tôi sẽ chia sẻ kinh nghiệm thực chiến và kiến thức chuẩn xác từ các nguồn uy tín như Google Search Central, để giúp bạn – một người mới – hiểu rõ bản chất của robots.txt và cách sử dụng nó để thực sự tối ưu SEO cho website.Robots.txt Là Gì? Bản Chất Quan Trọng Hơn Cả Định Nghĩa
Robots.txt là gì? diễn giải đơn giản nhất
Bạn cứ hình dung website của bạn là một tòa nhà lớn, và các bot tìm kiếm (Googlebot, Bingbot…) là những nhân viên giao hàng.
File robots.txt chính là “Bảng Nội Quy” hoặc “Người Gác Cổng” nằm ngay trước cửa chính của tòa nhà.
- Vị trí và Tên File: Nó luôn nằm ở thư mục gốc (Root Directory) của website và phải có tên chính xác là
robots.txt(Lưu ý: Google xác nhận tên file là Case-Sensitive). Ví dụ: https://lenart.vn/robots.txt. - Chức năng: Nó chứa các quy tắc (directives) chỉ dẫn cho các bot: “Bạn được phép đi vào khu vực nào” và “Bạn không được phép lãng phí thời gian vào khu vực nào”.
- Nguyên tắc:
robots.txttuân theo một tiêu chuẩn gọi là Robots Exclusion Protocol (REP) – Giao thức Loại trừ Robot.
Robots.txt chỉ chặn Crawl, KHÔNG chặn Index tuyệt đối (Cần dùng noindex)
Đây chính là điều tôi đã hiểu sai, và tôi muốn bạn tránh sai lầm này. Sự thật được Google xác nhận là:
- Chặn Crawl (Thu thập dữ liệu): Khi bạn dùng lệnh
Disallowtrongrobots.txt, bạn đang yêu cầu bot KHÔNG truy cập vào URL đó để đọc nội dung. - Index (Lập chỉ mục): Tuy nhiên, Google có thể vẫn Index (lập chỉ mục) URL đó nếu có các trang khác trỏ link (backlink hoặc internal link) đến nó. Google gọi đây là “Index mà không có nội dung (No Content)”. URL vẫn hiện trên kết quả tìm kiếm, nhưng không có mô tả (snippet) vì Google chưa từng đọc nội dung bên trong.
Trích dẫn kinh nghiệm từ Google: Google khuyến cáo không nên dùng
robots.txtđể chặn các trang nhạy cảm hoặc nội dung cần ẩn. Nếu bạn muốn chắc chắn một trang không bao giờ xuất hiện trên Google SERP, hãy sử dụng Meta Robots Tag với lệnhnoindexbên trong thẻ<head>của trang đó.
Cú Pháp Cơ Bản – Giải Mã Ngôn Ngữ Của robot.txt
File robots.txt chỉ bao gồm các dòng lệnh đơn giản. Dưới đây là các thành phần chính mà bạn cần nắm rõ:
Hai thành phần cốt lõi: User-agent và Directive (Disallow/Allow)
User-agent(Đối tượng Robot): Chỉ định robot nào áp dụng các quy tắc ngay sau nó.User-agent: *→ Áp dụng cho Tất cả các Bot.User-agent: Googlebot→ Chỉ áp dụng cho Bot chính của Google.
Directive(Chỉ thị): Lệnh yêu cầu bot thực hiện.Disallow:→ Yêu cầu KHÔNG truy cập vào URL/Thư mục sau dấu hai chấm.Allow:→ (Chủ yếu áp dụng cho Googlebot) Cho phép truy cập vào URL/File cụ thể, thường dùng để tạo ngoại lệ trong một thư mục đã bịDisallowlớn hơn.
Sitemap:(Khai báo Sitemap): Dòng này được dùng để thông báo vị trí file Sitemap cho Bot, giúp bot tìm thấy và Crawl các trang quan trọng nhanh hơn.
Các cú pháp phổ biến
| Mục đích | Cú pháp trong robots.txt | Ý nghĩa |
|---|---|---|
| Chặn toàn bộ website | User-agent: *Disallow: / | Yêu cầu tất cả bot không truy cập bất kỳ đường dẫn nào. |
| Chặn một thư mục cụ thể | User-agent: *Disallow: /wp-admin/ | Chặn tất cả bot truy cập vào thư mục quản trị /wp-admin/. |
| Chặn các file có cùng định dạng | User-agent: *aDisallow: /*.pdf$ | Chặn các file có đuôi .pdf (ký tự $ đại diện cho điểm kết thúc). |
| Khai báo Sitemap | Sitemap: https://lenart.vn/sitemap_index.xml | Khai báo vị trí file Sitemap cho bot. |
Lưu ý : Các URL trong
robots.txtlà Case-Sensitive (phân biệt chữ hoa/thường).Disallow: /Page/khác vớiDisallow: /page/. Hãy kiểm tra URL chính xác trước khi thêm vào.
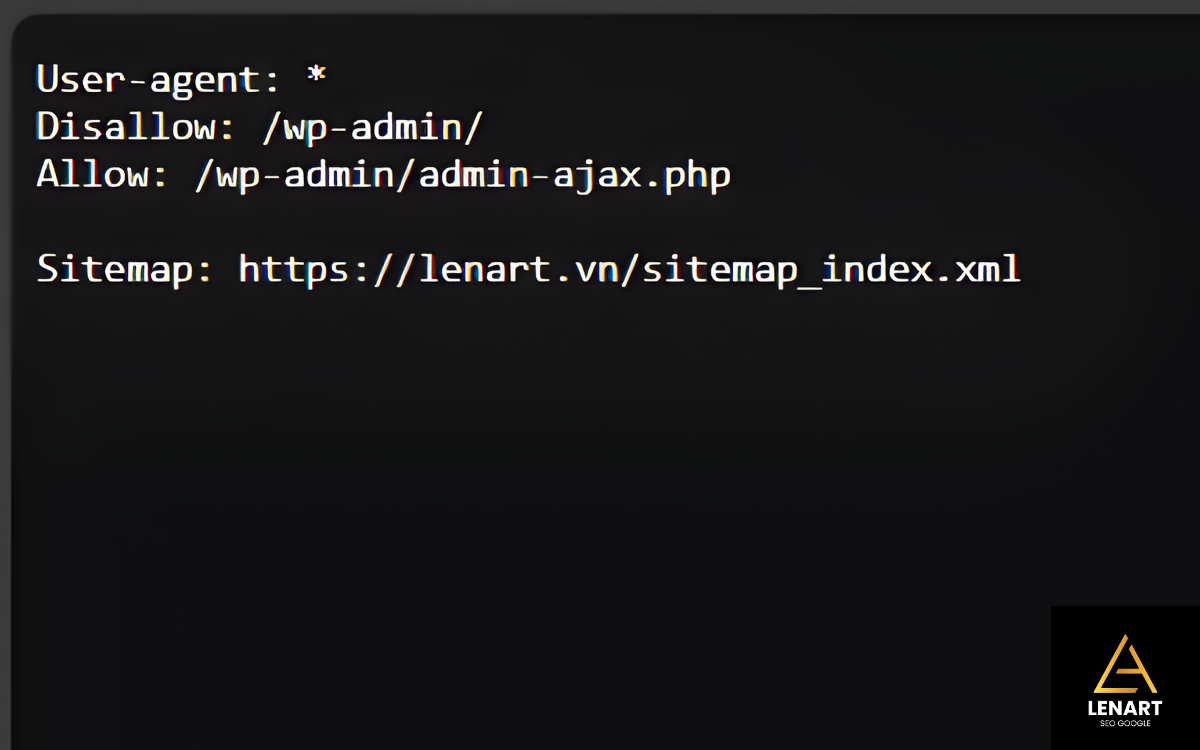
Tại Sao Cần File robots.txt? Tối Ưu Hóa Ngân Sách Thu Thập Dữ Liệu (Crawl Budget)
Vấn đề cốt lõi: Ngân sách thu thập dữ liệu (Crawl Budget) là gì?
Ngân sách thu thập dữ liệu (Crawl Budget) là số lượng URL mà Googlebot sẵn sàng thu thập và số lần mà bot truy cập website của bạn trong một khoảng thời gian nhất định.
Nói đơn giản: Google không có tài nguyên vô hạn để “ghé thăm” website của bạn. Mục tiêu của chúng ta là đảm bảo bot không lãng phí tài nguyên của nó vào những trang vô nghĩa.
Robots.txt giúp tối ưu Crawl Budget như thế nào?
Đây là mục đích quan trọng nhất của robots.txt. Bằng cách chặn các trang/thư mục không quan trọng:
- Bạn đang tập trung tài nguyên của Googlebot vào các trang Content Helpful (những bài viết, sản phẩm, dịch vụ cốt lõi) mà bạn muốn chúng Index nhanh và đạt thứ hạng cao.
- Bạn giảm tải cho server, vì bot sẽ không cố gắng truy cập vào các thư mục quản trị hoặc các trang lọc không cần thiết, giúp tốc độ tải trang ổn định hơn.
Các trường hợp NÊN Disallow để tối ưu Crawl Budget
Dựa trên kinh nghiệm của tôi và khuyến nghị từ Semrush, bạn nên chặn các loại URL sau để tối ưu hiệu quả nhất:
- Trang quản trị/Cài đặt: Ví dụ:
/admin/,/login/, các thư mục lõi của CMS (như/wp-includes/trong WordPress). - Các trang không có giá trị SEO: Trang “Thank You Page” (Sau khi đăng ký), các trang thử nghiệm (Staging), các trang chính sách nội bộ.
- Các tham số URL/Trang lọc (Phổ biến trên E-commerce): Các URL dạng
domain.com/category?sort=pricehaydomain.com/category?filter=blue. Những URL này tạo ra nội dung trùng lặp và lãng phí Crawl Budget một cách nghiêm trọng.
Cách Tạo và Kiểm Tra robots.txt Đúng Cách
Hướng dẫn tạo và đặt robots.txt (Vị trí chính xác)
Việc đặt file đúng chỗ là yếu tố then chốt:
- Tạo File: Sử dụng trình soạn thảo văn bản thuần (không phải Word) để viết các dòng lệnh.
- Đặt Tên File: Lưu tên chính xác là
robots.txt. - Vị trí: Upload file này lên Root Directory (thư mục gốc) của Hosting/Server. Nếu website của bạn là
abc.com, file phải truy cập được tạiabc.com/robots.txt.
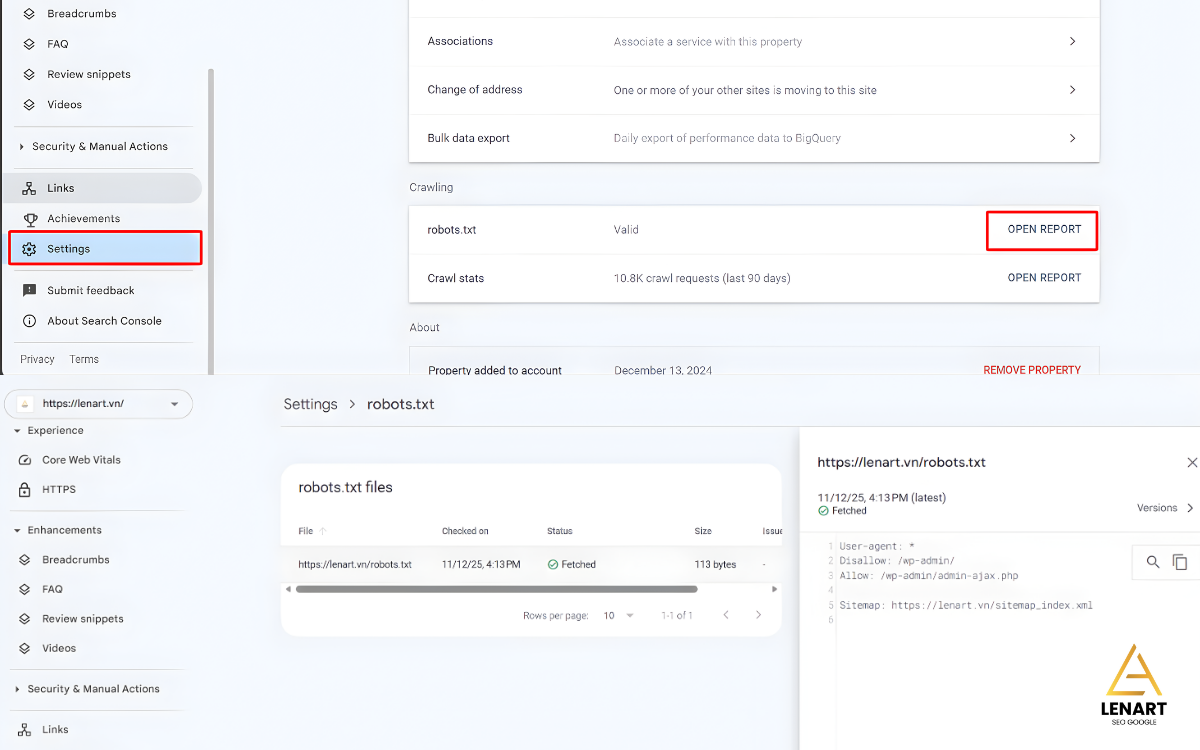
Cách Submit File robots.txt lên Google Search Console (GSC)
Mặc dù Googlebot sẽ tự động tìm kiếm, việc kiểm tra qua GSC giúp bạn quản lý tính Trustworthiness (Độ tin cậy) tốt hơn:
- Đảm bảo khai báo Sitemap: Luôn thêm dòng
Sitemap:vào cuối filerobots.txtcủa bạn. - Sử dụng Báo cáo trong GSC: Sau khi tải lên, bạn có thể kiểm tra trạng thái hoạt động của
robots.txttrong Google Search Console (Mục Cài đặt → Báo cáorobots.txt).
[Cảnh báo lỗi] Kiểm tra và xử lý lỗi phổ biến (Quan trọng nhất)
Sai lầm nghiêm trọng nhất là vô tình chặn toàn bộ website. Để tránh điều này, bạn phải kiểm tra kỹ lưỡng:
Công cụ hỗ trợ: Luôn sử dụng Google’s robots.txt Tester Tool (hiện có sẵn trong GSC/Legacy Tools) để kiểm tra cú pháp và xem các URL quan trọng của bạn có bị chặn (Blocked) hay không trước khi triển khai.
Khi kiểm tra, hãy nhập một URL quan trọng (ví dụ: Trang chủ hoặc một bài viết trọng tâm) và đảm bảo công cụ báo cáo là “Allowed” (Cho phép) chứ không phải “Blocked” (Bị chặn).
Lời Khuyên Của Tôi Cho Bạn Về robots.txt
File robots.txt không phức tạp, nhưng lại rất quyền lực. Hãy nhớ lại kinh nghiệm của tôi: đừng bao giờ coi nó là công cụ để ẩn nội dung nhạy cảm.
Hãy xem nó là công cụ để trợ giúp Googlebot: giúp bot tập trung tài nguyên (Crawl Budget) vào những nội dung thực sự hữu ích và có giá trị cho người dùng (Helpful Content), đồng thời tiết kiệm thời gian cho những trang “rác” không cần thiết.
Chúc bạn thành công với việc tối ưu Technical SEO!