Crawl JavaScript SEO từng gặp nhiều hạn chế do trước đây các bot tìm kiếm như Googlebot chỉ đọc được nội dung HTML tĩnh, không thể thu thập hay lập chỉ mục phần nội dung sinh ra bởi JavaScript.
Tuy nhiên, khi các trang web dần sử dụng nhiều JavaScript cùng các framework phổ biến như Angular, React hay Vue.js, mặt khác là sự phát triển của các ứng dụng một trang (SPA) và các ứng dụng web tiến tiến (PWA), thì mọi chuyện lại thay đổi hoàn toàn. Google lúc này không còn dựa vào phương pháp thu thập dữ liệu AJAX cổ điển nữa, họ bắt đầu tương tác, “render” nội dung web như một trình duyệt hiện đại trước khi lập chỉ mục.
Dù Google xử lý JavaScript rất tốt, nhưng họ vẫn khuyên các nhà phát triển nên dùng render phía máy chủ hoặc pre-rendering bởi bởi vì việc xử lý JavaScript vẫn khá phức tạp, và không phải mọi công cụ tìm kiếm đều có thể phản hồi kịp thời hoặc đầy đủ mọi đoạn script bạn viết.
Cùng với sự tiến bộ của các công cụ tìm kiếm, việc đọc và hiểu DOM sau khi JavaScript đã chạy xong ngày càng quan trọng hơn bao giờ hết. Điều này rất hữu ích để bạn nhận biết rõ sự khác nhau giữa HTML ban đầu và HTML đã được render khi đánh giá một trang web.
Trước đây, nhiều trình thu thập dữ liệu web còn không thể truy cập đúng nội dung ở các trang dùng JavaScript, cho đến khi chúng tôi tích hợp tính năng render JavaScript vào phần mềm Screaming Frog SEO Spider.
Cơ chế này giúp trang web được load và render đầy đủ trong một môi trường trình duyệt không giao diện (headless browser), rồi phần HTML đã “render” (sau khi JavaScript chạy xong) mới được đưa vào quy trình quét dữ liệu.
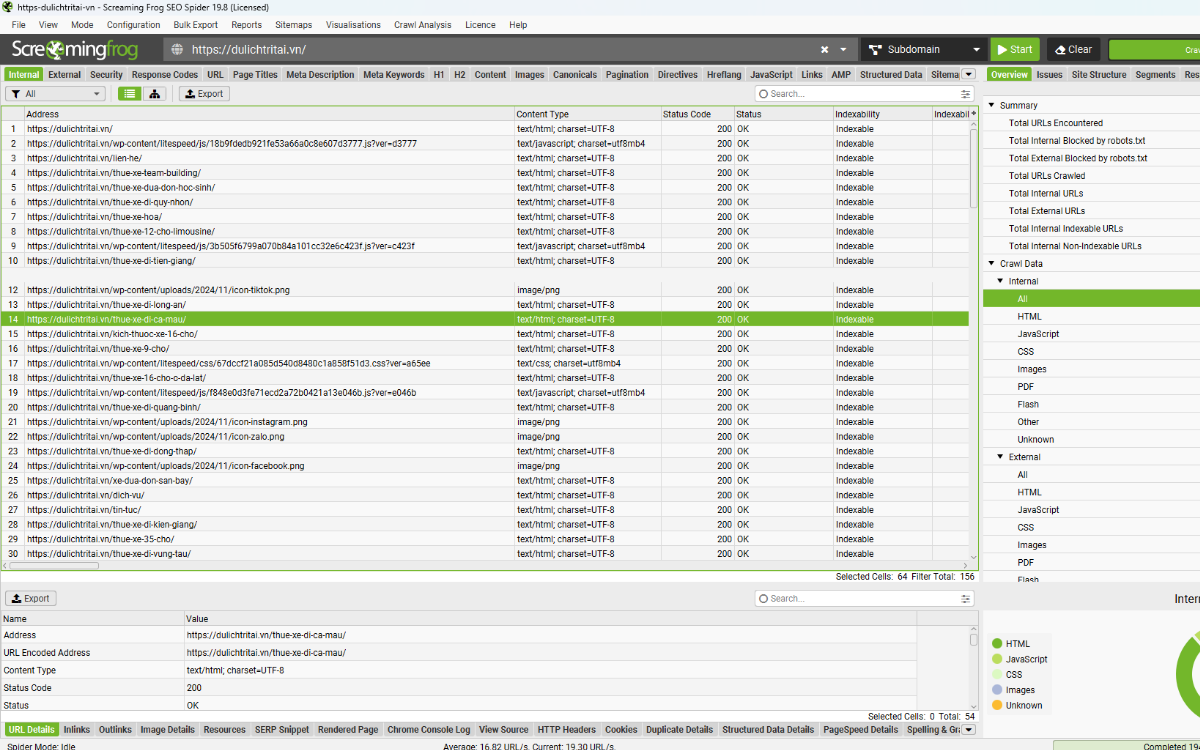
Cũng giống như Google, chúng tôi dùng Chrome làm nền tảng cho dịch vụ Web Rendering Service (WRS), và luôn cập nhật phiên bản mới nhất để đảm bảo sự tương thích và hiệu suất tốt nhất. Bạn có thể kiểm tra phiên bản Chrome đang được SEO Spider sử dụng tại “Help > Debug” trong dòng “Chrome Version”.
Nếu bạn đã nắm vững các kiến thức SEO cơ bản xoay quanh JavaScript, có thể chuyển ngay đến phần hướng dẫn Crawl JavaScript SEO cho website hoặc tiếp tục theo dõi những phần tiếp theo của bài viết
1. Những kiến thức cơ bản về SEO khi làm việc với JavaScript
Khi phát triển website bằng JavaScript, việc tối ưu hoá cho công cụ tìm kiếm trở nên quan trọng hơn bao giờ hết. Bởi lẽ, JavaScript vừa mang lại trải nghiệm tương tác mượt mà, vừa có thể vô tình gây khó khăn cho quá trình thu thập và lập chỉ mục của Google nếu không được triển khai đúng cách. Vì vậy, trước khi đi sâu vào từng kỹ thuật, chúng ta cần nắm rõ những nguyên tắc cơ bản giúp đảm bảo JS hoạt động hài hòa với SEO.
1.1. Những nguyên tắc cốt lõi cần nắm về JavaScript trong SEO
Mặc dù Google có thể thu thập và lập chỉ mục nội dung dùng JavaScript, vẫn có một số nguyên tắc và giới hạn bạn cần nắm rõ:
- Tất cả tài nguyên của trang như JavaScript, CSS, hình ảnh… phải được truy cập đầy đủ thì Google mới có thể thu thập, render và lập chỉ mục chính xác.
- Google vẫn yêu cầu mỗi trang phải có URL rõ ràng, duy nhất; các liên kết phải được đặt trong thẻ <a> chuẩn. Bạn có thể gắn link tĩnh và đồng thời gọi hàm JavaScript nếu cần.
- Google không thao tác trên trang như người dùng thật — họ sẽ không thực hiện các hành động như nhấp chuột, rê chuột hoặc cuộn trang để tải thêm nội dung.
- Google chụp lại phiên bản trang đã render khi mạng không còn hoạt động hoặc sau một khoảng thời gian nhất định. Nếu trang mất quá nhiều thời gian để render, có khả năng Google sẽ bỏ qua và một số nội dung sẽ không được nhìn thấy hoặc lập chỉ mục.
- Google thường render hầu hết các trang, tuy nhiên họ sẽ không đưa trang vào hàng đợi render nếu ngay từ phản hồi ban đầu hoặc trong HTML tĩnh có chứa thẻ “noindex”.
- Quá trình render và lập chỉ mục là hai bước tách biệt. Google sẽ thu thập HTML tĩnh trước, còn phần render sẽ được thực hiện sau khi có tài nguyên phù hợp. Chỉ khi render xong, Google mới phát hiện thêm nội dung và liên kết trong HTML đã xử lý. Trước đây quá trình này có thể mất đến một tuần, nhưng hiện tại Google đã cải thiện đáng kể và thời gian trung bình chỉ còn khoảng 5 giây.
Nắm rõ các nguyên tắc này là điều bắt buộc khi làm JavaScript SEO, bởi thứ hạng của một website phụ thuộc rất nhiều vào việc Google có render được trang hay không.
1.2. Chiến lược Render Nội Dung
Google khuyến khích xây dựng website theo hướng progressive enhancement — tức là tạo khung HTML và hệ thống điều hướng trước, sau đó mới dùng JavaScript để bổ sung giao diện và tăng trải nghiệm cho người dùng.
Thay vì phụ thuộc quá nhiều vào việc render hoàn toàn trên trình duyệt của người dùng, Google gợi ý nên áp dụng các phương pháp như render phía máy chủ, render tĩnh hoặc hydration. Những cách này vừa cải thiện tốc độ tải trang cho người dùng, vừa giúp các công cụ tìm kiếm xử lý nội dung hiệu quả hơn.
- Server-side rendering (SSR) và pre-rendering: JavaScript của trang sẽ được chạy trước trên máy chủ, sau đó gửi về cho người dùng và bot tìm kiếm một phiên bản HTML đã render sẵn.
- Hydration hoặc hybrid rendering (isomorphic): phần HTML quan trọng ban đầu được render từ máy chủ, còn những phần bổ sung hoặc không quá quan trọng sẽ được xử lý bằng JavaScript phía trình duyệt.
Nhiều framework hiện đại như React hay Angular Universal đều hỗ trợ render phía máy chủ hoặc render kết hợp.
Dynamic rendering cũng có thể dùng như một giải pháp tạm thời khi không thể điều chỉnh mã nguồn front-end. Cách này hoạt động bằng cách phục vụ phiên bản render phía client cho người dùng thật, còn các công cụ tìm kiếm thì sẽ nhận phiên bản HTML tĩnh đã pre-render. Tuy nhiên, Google không xem đây là giải pháp lâu dài vì không mang lại lợi ích tối ưu về trải nghiệm người dùng và hiệu suất.
Nếu website của bạn đang dùng dynamic rendering, bạn có thể kiểm tra bằng cách đổi user-agent sang Googlebot trong SEO Spider tại mục Config > User-Agent.
1.3. Những phức tạp khi lập chỉ mục nội dung JavaScript
Mặc dù Google có thể xử lý và lập chỉ mục các trang dùng JavaScript, vẫn có nhiều yếu tố cần lưu ý thêm.
Google áp dụng cơ chế lập chỉ mục gồm hai giai đoạn:
- Ban đầu, họ chỉ thu thập và lập chỉ mục phần HTML tĩnh.
- Sau đó, khi có đủ tài nguyên, Google mới quay lại để render trang và thu thập thêm nội dung cũng như liên kết xuất hiện sau khi JavaScript chạy.
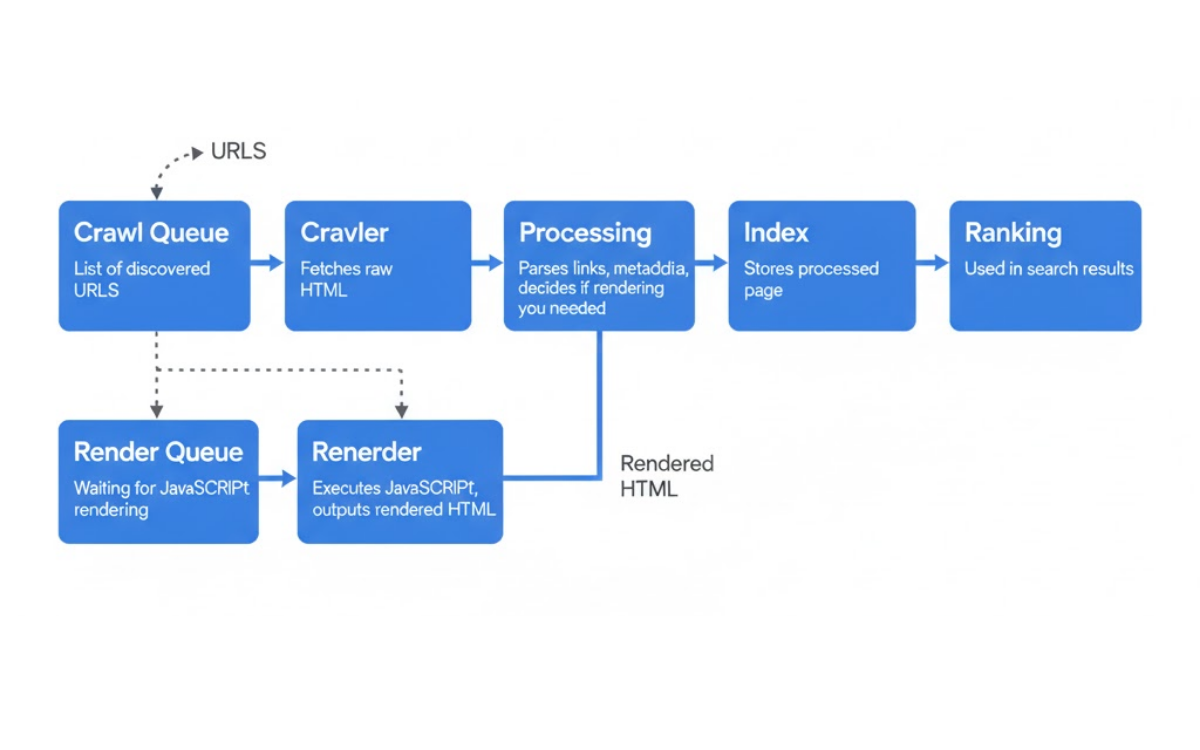
Thời gian trung bình giữa lần crawl đầu tiên và lúc Google thực hiện render là khoảng 5 giây. Tuy nhiên, con số này có thể lớn hơn tùy vào mức độ sẵn sàng của tài nguyên Google. Với những website có nội dung cần lập chỉ mục nhanh (như tin tức), sự chậm trễ này đôi khi có thể gây ra vấn đề.
Nếu một trang mất quá lâu để render, Google có thể tạm thời sử dụng dữ liệu ban đầu trong HTML phản hồi (ví dụ: thẻ meta hoặc canonical) cho đến khi họ có thể render trang. Tất cả các trang đều sẽ được render, trừ khi ngay từ đầu trong HTML đã có chỉ dẫn yêu cầu Googlebot không lập chỉ mục. Vì vậy, phần HTML tĩnh ban đầu cũng phải nhất quán và chính xác.
Một số công cụ tìm kiếm khác như Bing không xử lý JavaScript tốt như Google khi phải làm việc trên quy mô lớn. Do JavaScript khá “nhạy cảm”, chỉ cần một lỗi nhỏ hoặc việc chặn tài nguyên quan trọng cũng có thể khiến quá trình render thất bại, dẫn đến việc nội dung không được lập chỉ mục.
Tóm lại, việc render và lập chỉ mục JavaScript có khá nhiều điểm phức tạp:
- Cơ chế lập chỉ mục hai giai đoạn
- Lỗi JavaScript
- Tài nguyên bị chặn khiến Google không render được
- Các chỉ dẫn trong HTML khiến bot không tiếp tục tới bước render
Mặc dù đa phần những vấn đề này hiếm khi xảy ra, nhưng nếu website quá phụ thuộc vào JavaScript phía trình duyệt, chỉ một lỗi nhỏ cũng có thể gây ảnh hưởng lớn đến khả năng lập chỉ mục của trang.
2. Cách nhận diện nội dung được tạo ra bởi JavaScript trên trang web
Việc nhận biết một website sử dụng framework JavaScript khá dễ. Tuy nhiên, xác định những phần nội dung, khu vực trên trang, hay các thẻ HTML được thay đổi động bằng JavaScript lại là việc khó hơn nhiều.
Dưới đây là một số dấu hiệu giúp bạn biết website có đang dùng JavaScript hay không.
2.1. Crawling website ở chế độ HTML
Đây thường là bước đầu tiên mà nhiều người thực hiện. Bạn có thể bắt đầu thu thập dữ liệu của website bằng Screaming Frog SEO Spider ở chế độ mặc định.
Theo thiết lập ban đầu, công cụ sẽ crawl ở chế độ “text only”, nghĩa là nó chỉ đọc HTML thô trước khi JavaScript được thực thi.
Nếu website dựa hoàn toàn vào JavaScript phía trình duyệt, rất thường gặp tình huống SEO Spider chỉ crawl được mỗi trang chủ với trạng thái 200 “OK”, cùng một vài file JavaScript hoặc CSS.
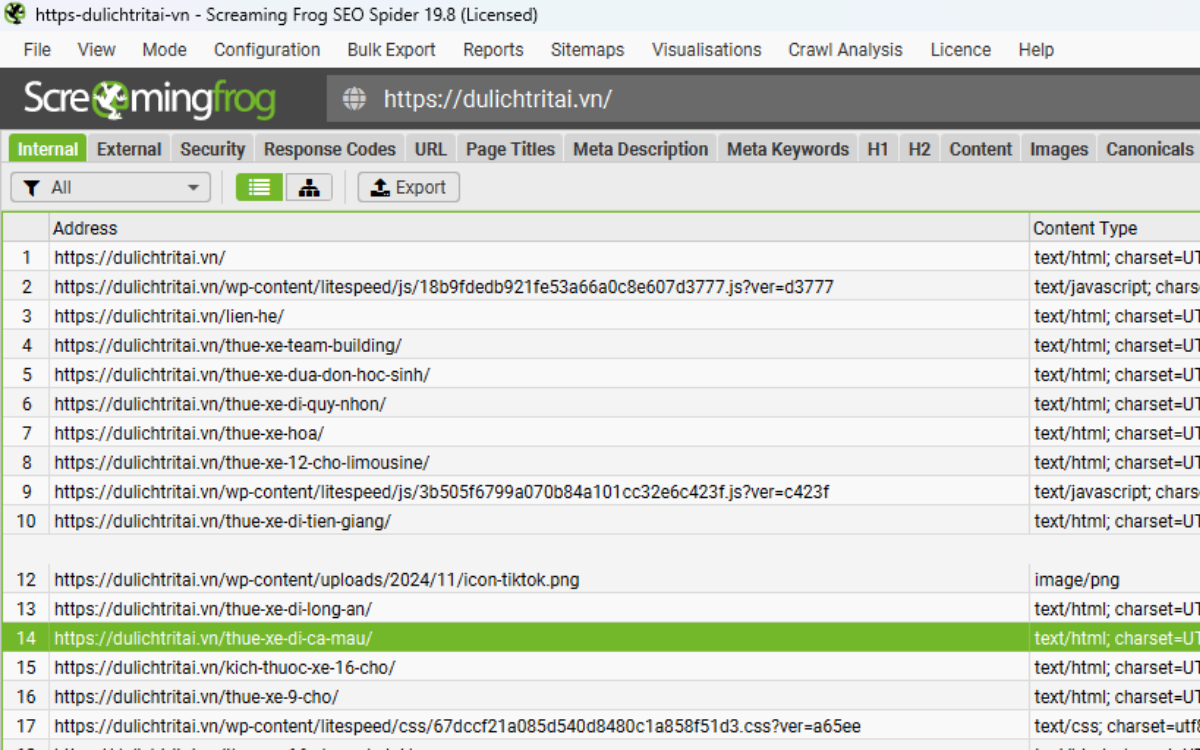
2.2. Crawling website có sử dụng JavaScript
Bạn cũng sẽ thấy rằng trang này không xuất hiện bất kỳ liên kết nào trong tab Outlinks, vì các liên kết đó chỉ được tạo ra sau khi JavaScript chạy — mà ở chế độ text-only, chúng chưa được render nên công cụ không nhìn thấy.
Điều này là dấu hiệu cho thấy trang web đang dùng JavaScript framework với cơ chế render phía client. Tuy nhiên, dấu hiệu này không nói rõ các phần khác của website có phụ thuộc JavaScript hay không.
Ví dụ:
- Một website có thể dùng JavaScript chỉ để tải danh sách sản phẩm trong trang danh mục.
- Hoặc chỉ dùng để cập nhật tiêu đề trang (title) hay thẻ meta.
Vậy làm sao để phát hiện những phần này dễ dàng hơn?
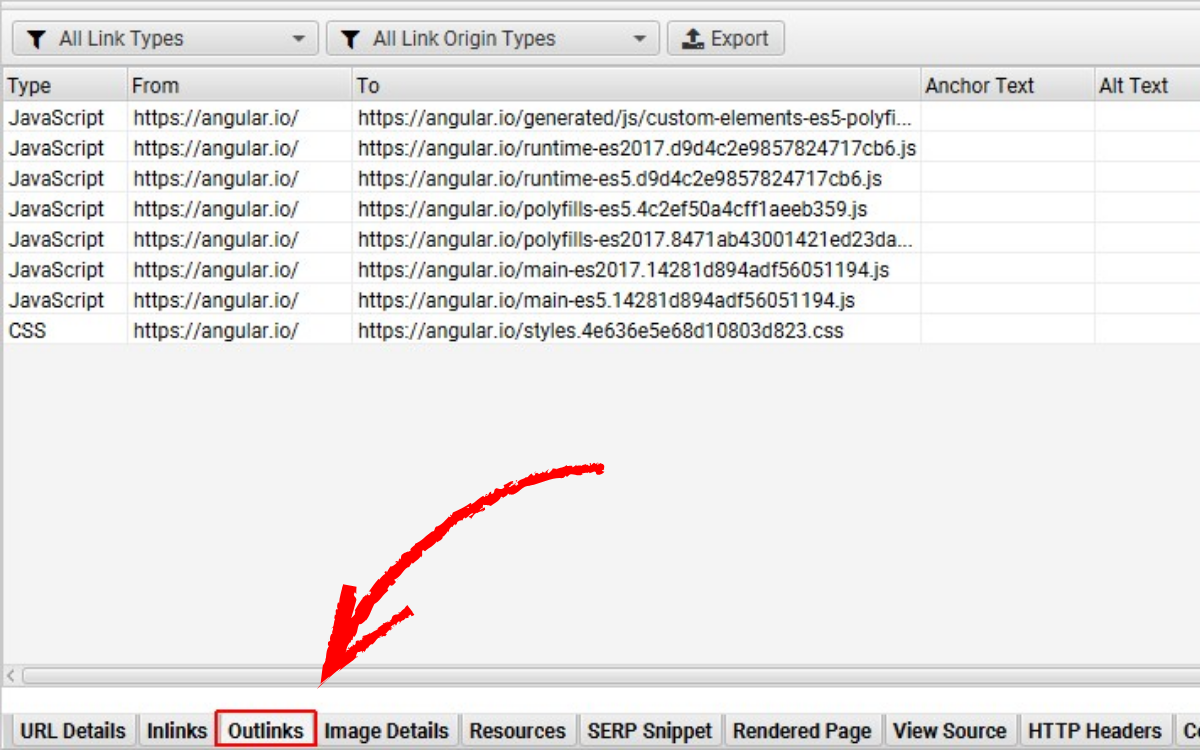
2.3. Chuyển sang chế độ JavaScript Rendering
Để nhận biết JavaScript hiệu quả hơn, bạn cần bật chế độ render JavaScript tại:
Config > Spider > Rendering
Sau đó tiến hành crawl toàn bộ website hoặc crawl mẫu một số template.
SEO Spider lúc này sẽ thu thập cả HTML ban đầu lẫn HTML sau khi render, từ đó xác định những trang có nội dung hoặc liên kết chỉ xuất hiện sau khi JavaScript chạy, đồng thời báo cáo những điểm phụ thuộc quan trọng.

2.4. JavaScript Dependency Identification
Trong phần JavaScript tab, công cụ sẽ hiển thị danh sách các bộ lọc giúp bạn phát hiện các vấn đề thường gặp khi audit trang web sử dụng JavaScript phía client.
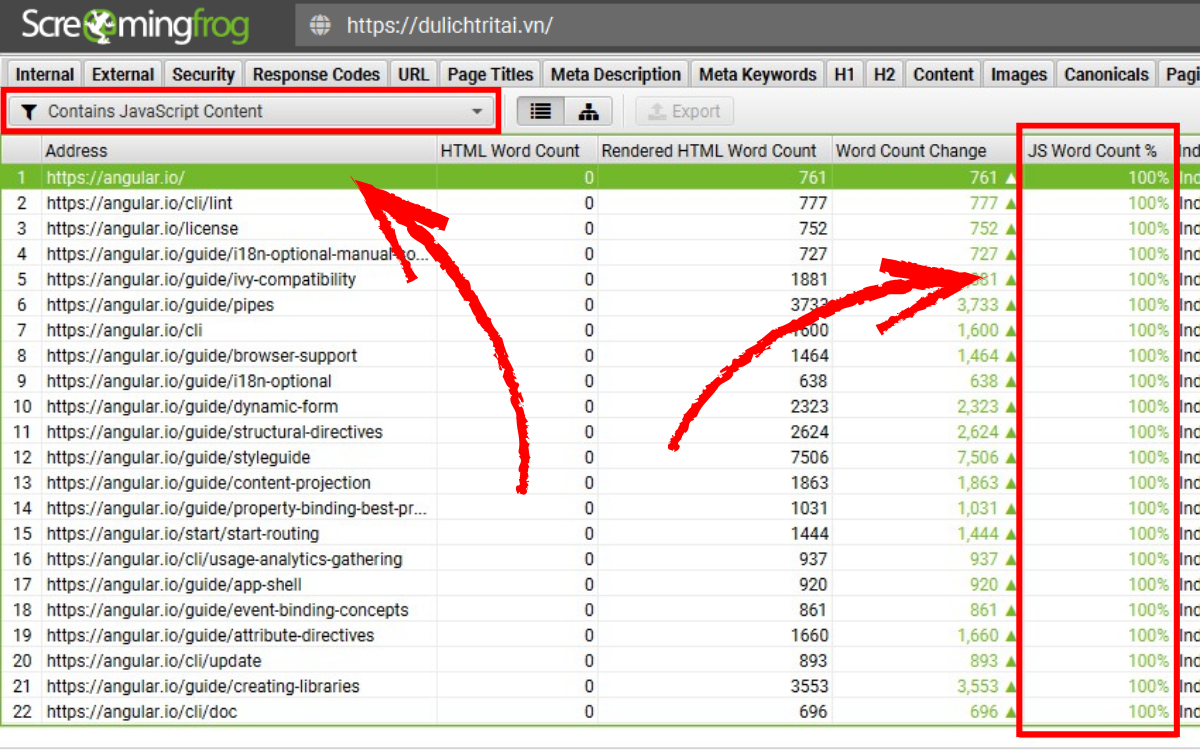
Công cụ sẽ cảnh báo nếu một trang có nội dung chỉ xuất hiện trong HTML sau khi render, tức là hoàn toàn phụ thuộc vào JavaScript.
Ví dụ:
- Toàn bộ nội dung nằm trong HTML đã render.
- Một số liên kết chỉ có trong HTML sau render.
- Tiêu đề trang hoặc mô tả meta được JavaScript thay đổi so với HTML thô.
Bạn có thể xem từng trường hợp trực tiếp trong giao diện của công cụ. Ngoài những tính năng giúp kiểm tra trên diện rộng, bạn hoàn toàn có thể sử dụng thêm nhiều công cụ hoặc kỹ thuật khác để phân tích sâu và nhận diện JavaScript trong trang web.
2.5. Trao đổi trực tiếp với khách hàng
Đây thực ra nên là bước đầu tiên. Cách đơn giản nhất để hiểu một website hoạt động thế nào là hỏi thẳng khách hàng hoặc đội ngũ lập trình.
Bạn có thể đặt những câu hỏi như:
- Website được xây dựng bằng công nghệ gì?
- Có sử dụng framework JavaScript không?
- Nội dung hoặc liên kết trên trang có phải phụ thuộc vào JavaScript phía trình duyệt không?
Những câu hỏi này nghe rất cơ bản, nhưng trong nhiều trường hợp, bạn sẽ nhận được thông tin cực kỳ hữu ích.
2.6. Tắt JavaScript để kiểm tra
Một cách khác để nhận biết mức độ phụ thuộc vào JavaScript là thử tắt JavaScript trong trình duyệt.
Trong Chrome, bạn có thể tắt JavaScript từ DevTools; còn Firefox có sẵn tùy chọn tương tự qua Web Developer Toolbar.
Hãy xem thử: khi JavaScript bị tắt, phần nội dung nào của trang còn hoạt động? Có trang chỉ hiện ra một màn hình trắng — lúc đó bạn biết phần lớn nội dung được tạo động.
Ngoài ra, khi audit, việc tắt thêm cookie và CSS cũng giúp bạn dễ phát hiện các vấn đề liên quan đến quá trình crawl.
2.7. Kiểm tra mã nguồn HTML ban đầu
Nhấp chuột phải và chọn “View page source” trong Chrome để xem HTML gốc — đây là phần HTML mà Google và SEO Spider nhìn thấy trước khi JavaScript chạy.
Bạn hãy kiểm tra xem:
- Có nội dung văn bản nào trong HTML không?
- Có liên kết nào không?
- Có dấu hiệu sử dụng framework hoặc thư viện JavaScript không?
Nếu bạn tìm kiếm mà không thấy nội dung hoặc liên kết trong mã nguồn, thì chắc chắn chúng được tạo ra động trong DOM và chỉ xuất hiện sau khi render JavaScript.
Trường hợp phần <body> trống trơn gần như chắc chắn là trang đang dựa hoàn toàn vào JavaScript để hiển thị thông tin.
2.8. Kiểm tra mã nguồn sau khi JavaScript chạy
Bạn cũng nên so sánh HTML tĩnh ban đầu với mã HTML đã được render.
Nhấn chuột phải → Inspect để xem phiên bản HTML sau khi JavaScript thực thi.
Ở đây bạn thường có thể nhìn thấy tên của framework (ví dụ như “React”) trong mã nguồn đã render.
Nhiều nội dung và liên kết sẽ chỉ xuất hiện trong rendered HTML, chứ không nằm trong HTML ban đầu. Đây chính là phiên bản mà SEO Spider sẽ sử dụng khi bật chế độ JavaScript rendering.
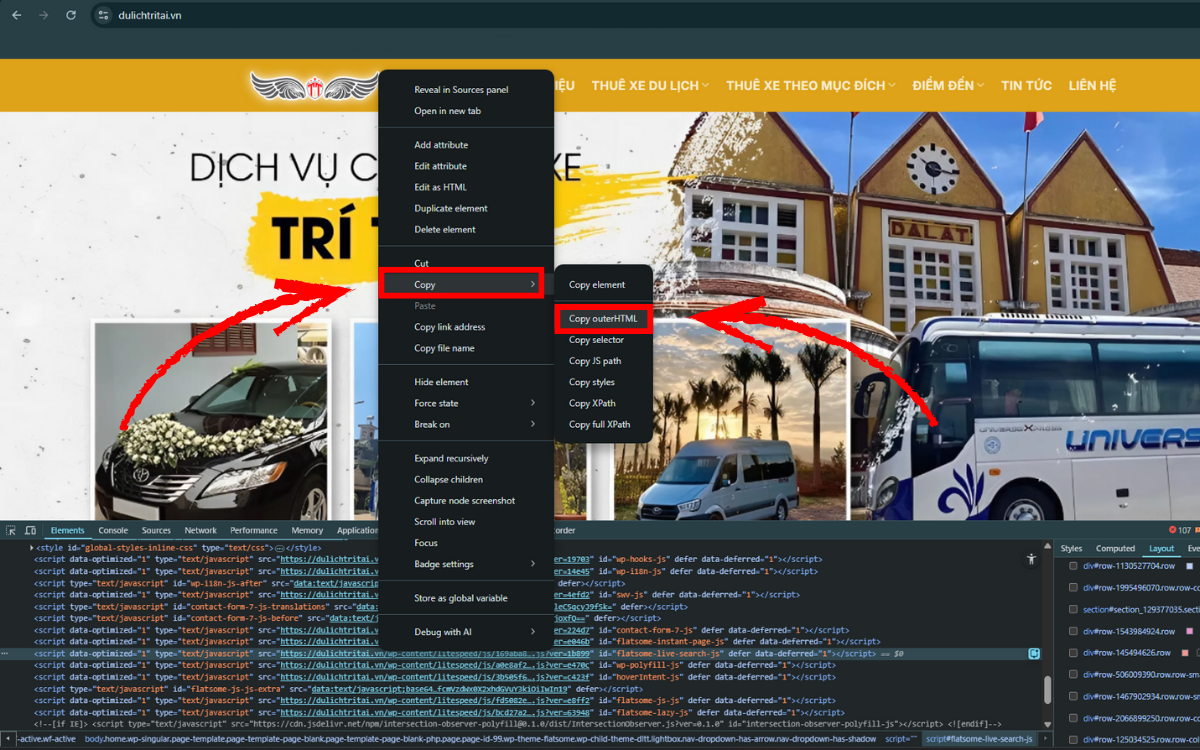
Bạn có thể nhấp vào thẻ <html>, sau đó chọn Copy > outerHTML để sao chép toàn bộ mã render và so sánh với mã nguồn gốc.
2.9. Sử dụng tiện ích Toolbars & Plugins
Có nhiều tiện ích như:
- BuiltWith
- Wappalyzer
- JS Library Detector
Chúng có thể giúp nhận diện framework hoặc thư viện JavaScript được sử dụng trên trang chỉ trong vài giây.
Dù không phải lúc nào cũng chính xác tuyệt đối, nhưng đây là những công cụ giúp bạn có thêm manh mối mà không tốn nhiều thời gian.
3. Khi nào nên thu thập dữ liệu bằng JavaScript
Mặc dù Google có thể render hầu hết mọi trang web, bạn vẫn nên sử dụng chế độ crawl JavaScript một cách chọn lọc trong các trường hợp sau:
- Khi lần đầu phân tích một website để xem mức độ phụ thuộc vào JavaScript.
- Khi audit những trang mà bạn biết chắc có nội dung hoặc liên kết được tạo động.
- Khi website chuẩn bị có đợt triển khai lớn và bạn cần đảm bảo mọi thứ hoạt động ổn định sau thay đổi.
3.1. Vì sao cần dùng một cách chọn lọc?
Crawl bằng JavaScript tiêu tốn nhiều tài nguyên hơn và chạy chậm hơn bình thường. Lý do là khi thu thập dữ liệu, công cụ phải tải toàn bộ tài nguyên của trang như JavaScript, CSS, hình ảnh… rồi render trang trong chế độ headless để tạo ra DOM giống như trình duyệt thật.
Với các website nhỏ, điều này không gây ảnh hưởng lớn.
Nhưng với những trang lớn có hàng chục nghìn trang trở lên, việc render từng trang có thể làm quá trình crawl kéo dài đáng kể. Nếu website của bạn không phụ thuộc nhiều vào JavaScript để thay đổi nội dung trên trang, thì không cần thiết phải bật tính năng này cho tất cả URL — vừa tốn thời gian, vừa tốn tài nguyên.
Nếu bạn muốn luôn crawl với JavaScript được bật, có thể vào:
Bắt đầu với Config > Spider > Rendering và lưu lại thiết lập để sử dụng mặc định.
4. Hướng dẫn thu thập dữ liệu cho các website chạy JavaScript
Để crawl những website được xây dựng bằng các framework JavaScript như Angular, React hoặc Vue.js và phát hiện những phần phụ thuộc vào JavaScript, bạn cần chuyển SEO Spider sang chế độ JavaScript Rendering.
Dưới đây là 10 bước gợi ý giúp bạn thiết lập và kiểm tra một website chạy JavaScript trong hầu hết các trường hợp thường gặp.
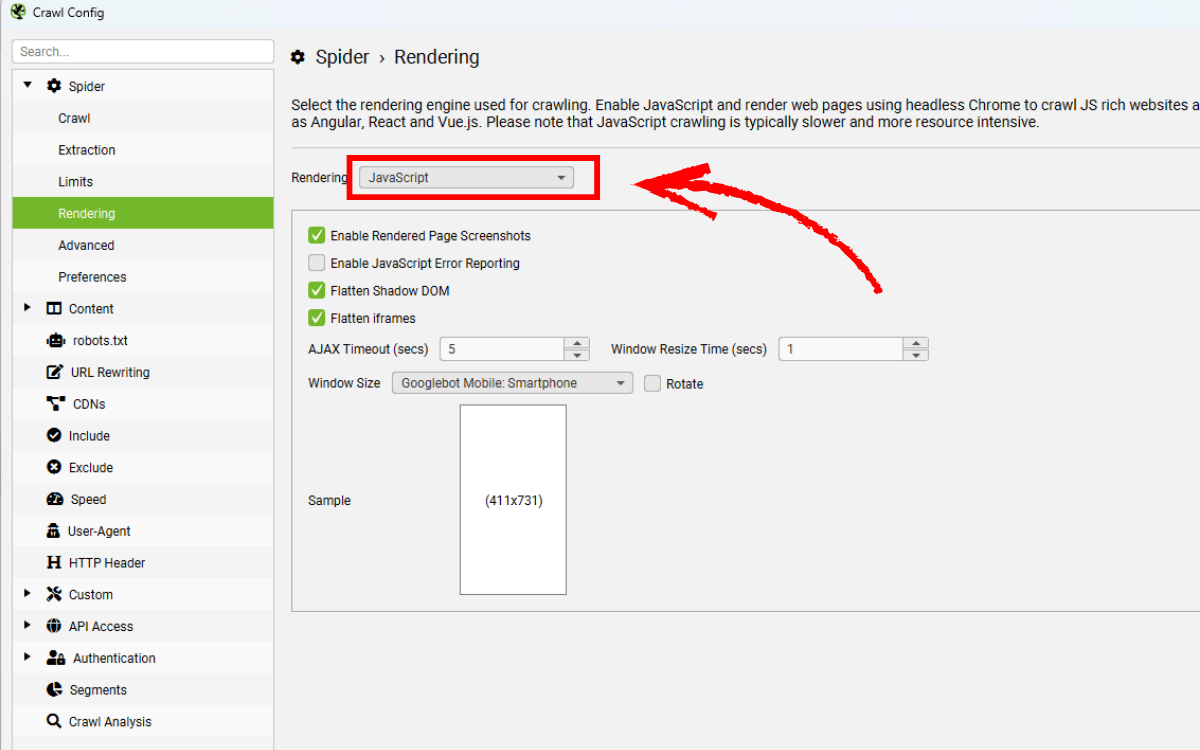
4.1. Chuyển chế độ Rendering sang “JavaScript”
Để bắt đầu thu thập dữ liệu một website chạy JavaScript, mở SEO Spider và vào:
Chọn Configuration > Spider > Rendering Sau đó thay đổi tùy chọn “Rendering” thành JavaScript.
(Đây là bước kích hoạt việc render trang giống như trình duyệt thật.)
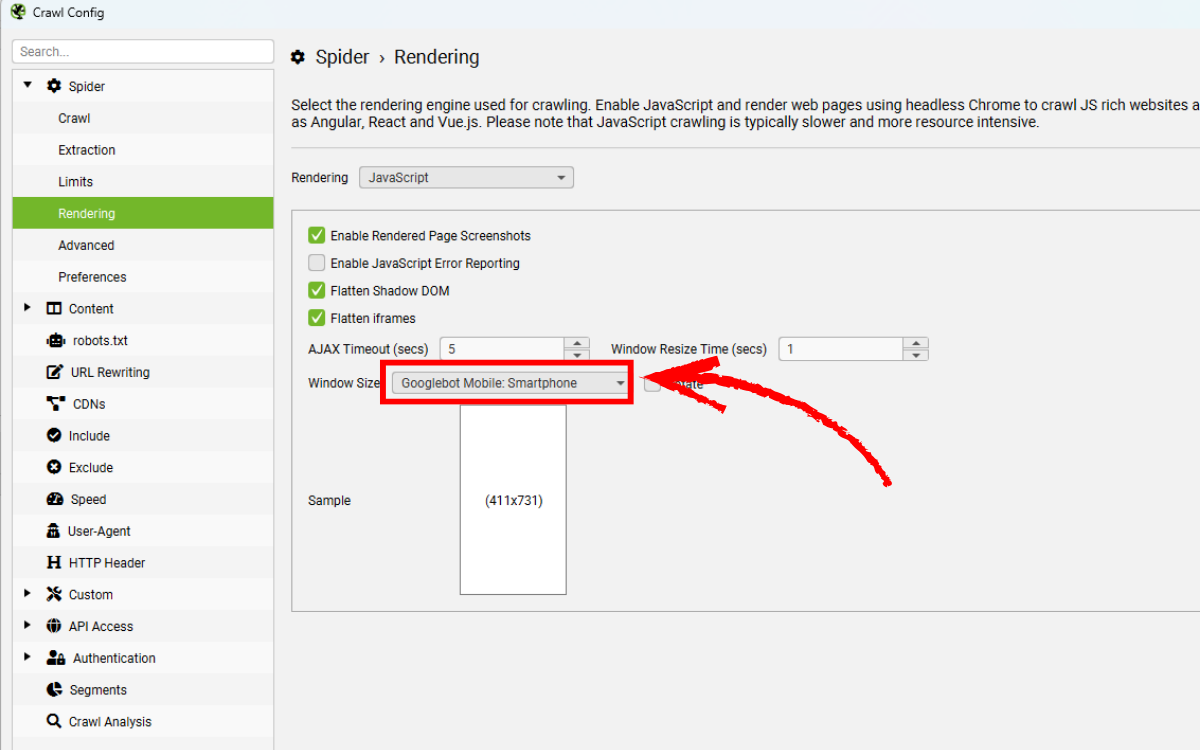
4.2. Thiết lập User-Agent và kích thước cửa sổ hiển thị
Theo mặc định, SEO Spider dùng Googlebot Smartphone để render, vì Google ưu tiên thu thập và lập chỉ mục bằng thiết bị di động (mobile-first indexing).
Điều này đồng nghĩa là trong tab “rendered page” ở phía dưới, bạn sẽ thấy ảnh chụp trang web ở kích thước của màn hình di động.
Bạn có thể thay đổi:
- User-Agent tại: Configuration > HTTP Header > User-Agent
- Kích thước cửa sổ (window size) tại: Configuration > Spider > Rendering
Tùy chỉnh này giúp bạn render trang theo định dạng phù hợp với nhu cầu kiểm tra.
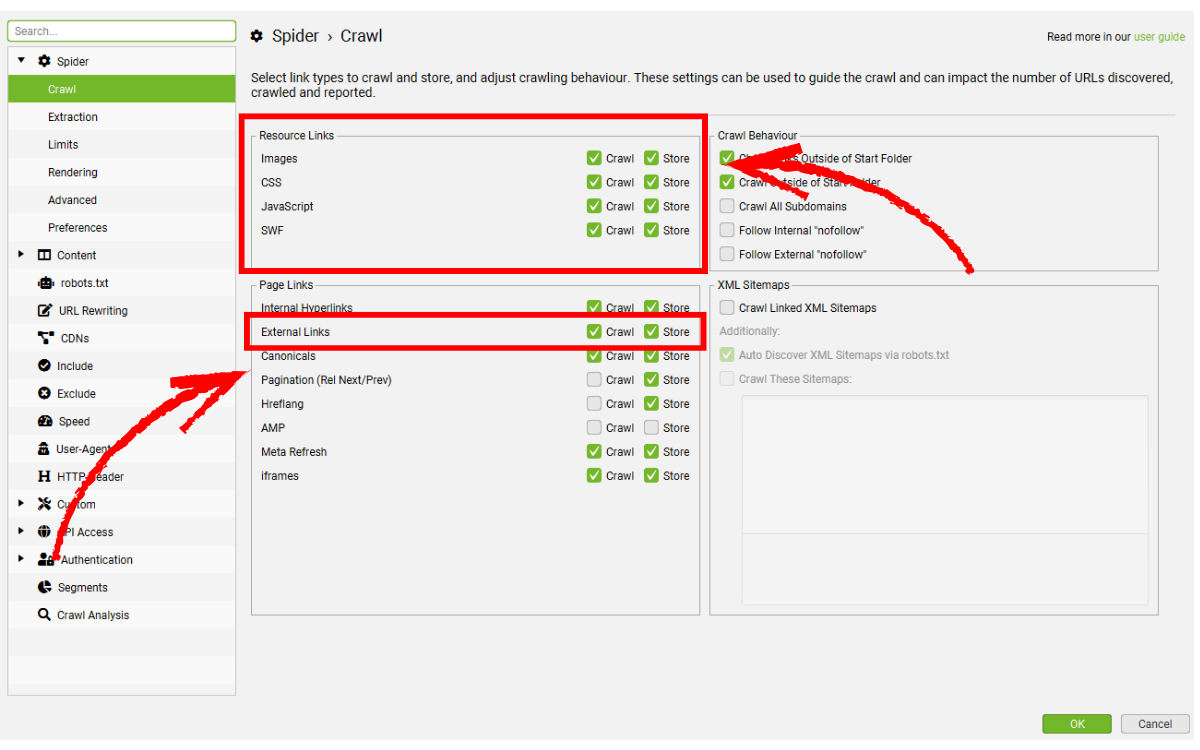
4.3. Kiểm tra tài nguyên và liên kết ngoài
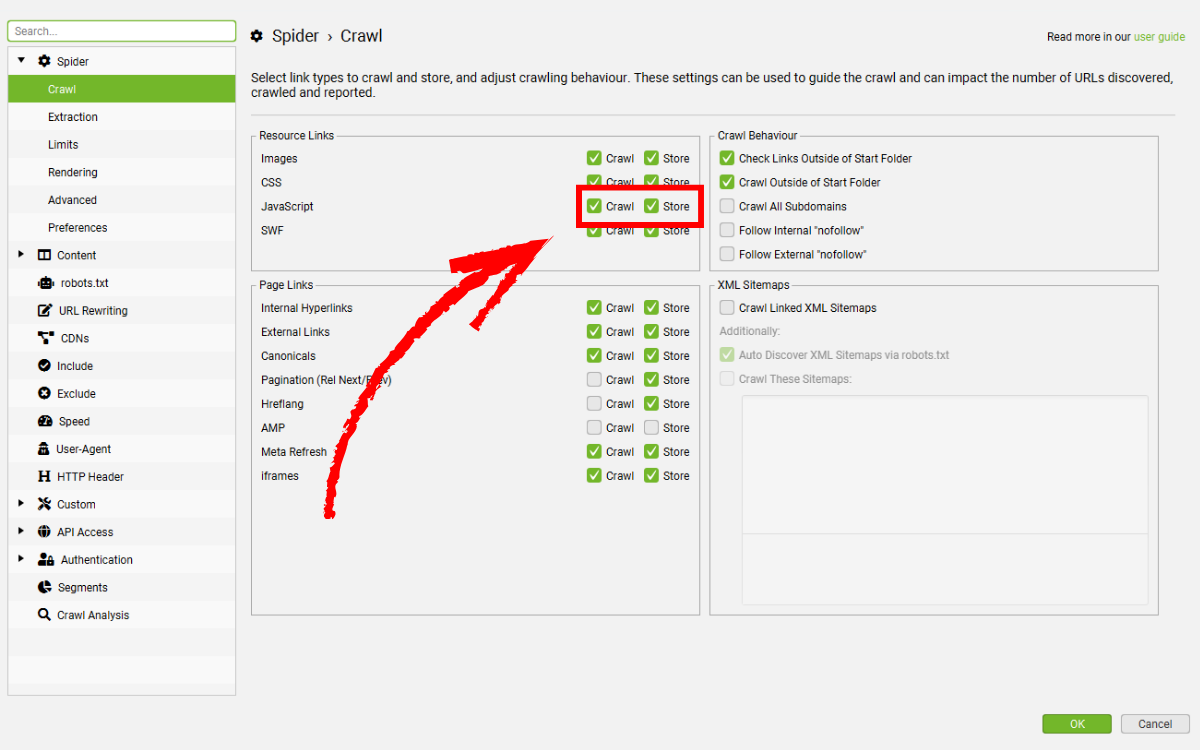
Hãy chắc chắn rằng các loại tài nguyên như hình ảnh, file CSS, file JS… đều được bật crawl trong mục: Configuration > Spider
Nếu những tài nguyên này nằm trên một subdomain khác hoặc thậm chí trên một domain hoàn toàn khác, bạn cần bật tùy chọn Check External Links, nếu không SEO Spider sẽ không tải được tài nguyên đó đồng nghĩa trang sẽ không render đầy đủ.
Đây vốn là thiết lập mặc định. Nếu bạn đã thay đổi gì trước đó, có thể khôi phục lại cấu hình gốc bằng cách chọn:
Chọn File > Default Config > Clear Default Configuration
4.4. Tiến hành Crawl JavaScript SEO
Nhập URL cần kiểm tra vào ô “Enter URL to spider”, sau đó nhấn Start để bắt đầu crawl.
Khi crawl website chạy JavaScript, giao diện có thể thể hiện hơi khác so với crawl trang HTML thông thường. Lúc đầu có thể bạn chưa thấy gì xuất hiện, nhưng sau một khoảng thời gian, hàng loạt URL sẽ xuất hiện cùng lúc.
Lý do là SEO Spider phải tải toàn bộ tài nguyên của trang để render hoàn chỉnh, rồi mới hiển thị dữ liệu thu thập được.
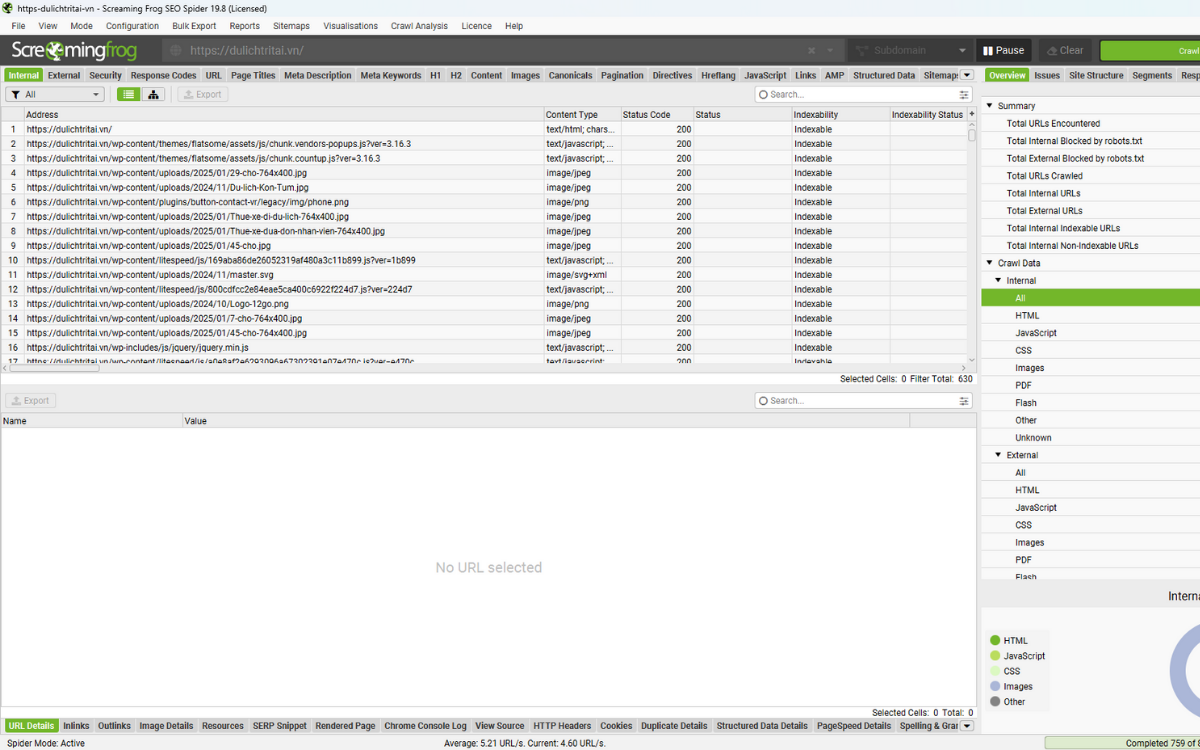
4.5. View JavaScript Tab
Trong tab JavaScript, bạn sẽ tìm thấy 15 bộ lọc khác nhau giúp bạn nhận diện các phần phụ thuộc vào JavaScript và những vấn đề thường gặp khi đánh giá website sử dụng client-side rendering.
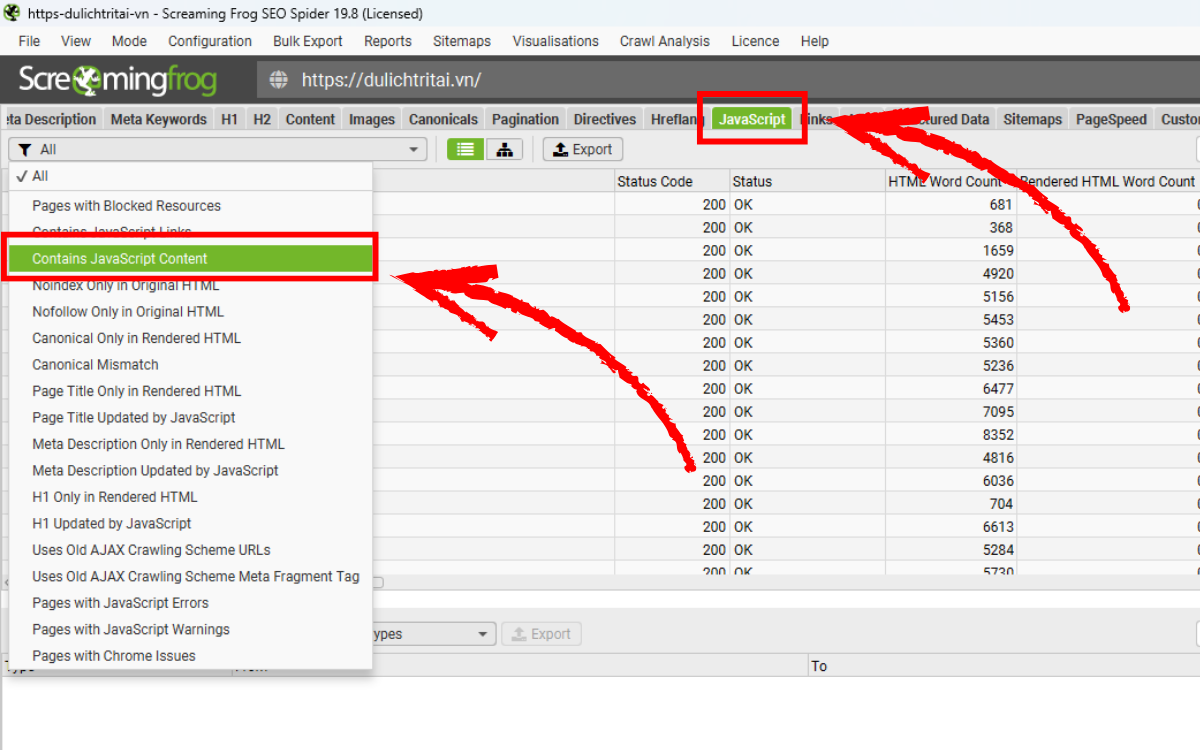
Bạn có thể lọc theo các nhóm liên quan đến SEO như sau:
- Pages with Blocked Resources – Các trang chứa những tài nguyên (như hình ảnh, file JavaScript hoặc CSS) bị robots.txt chặn lại. Việc các file quan trọng không thể truy cập có thể khiến công cụ tìm kiếm không render được trang đúng cách. Hãy cập nhật robots.txt để cho phép thu thập những tài nguyên cần thiết phục vụ quá trình render nội dung trang; những tài nguyên không quan trọng (chẳng hạn bản đồ Google Maps nhúng) có thể bỏ qua.
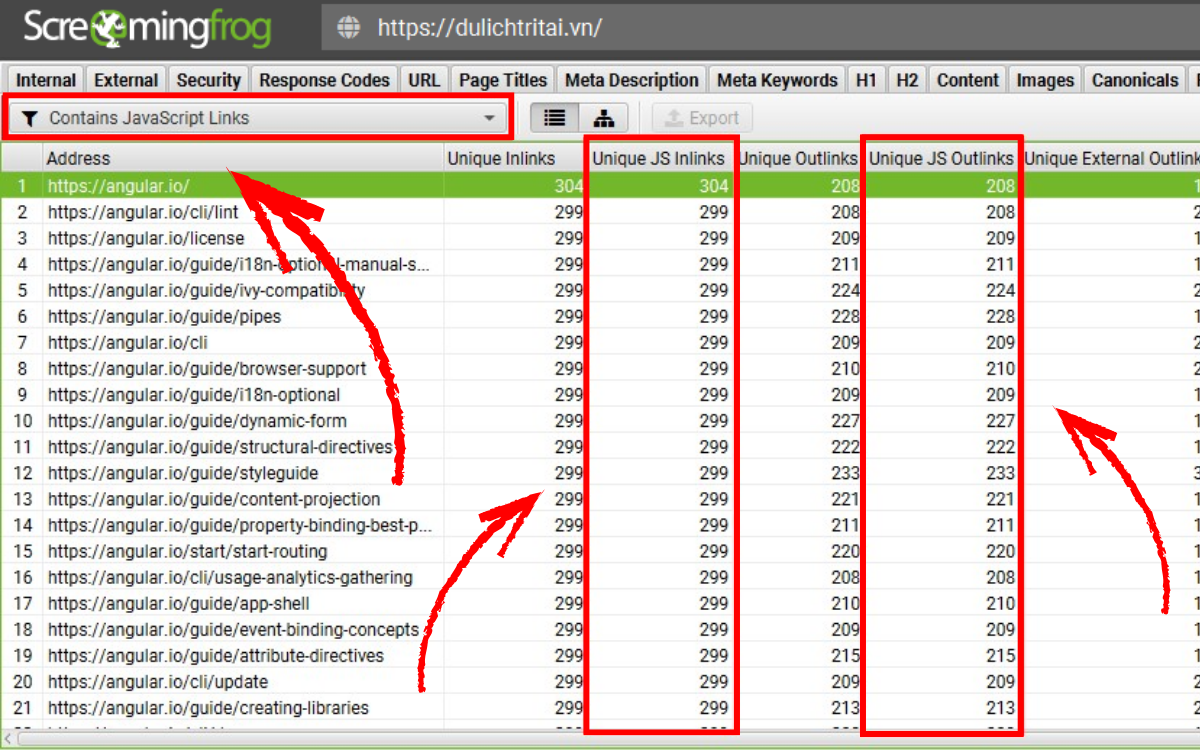
- Contains JavaScript Links – Những trang có liên kết chỉ xuất hiện trong HTML sau khi JavaScript chạy xong. Các liên kết này không tồn tại trong HTML gốc. Google có thể thấy các link được tạo động, nhưng bạn nên cân nhắc đưa những liên kết quan trọng vào HTML phía máy chủ.
- Contains JavaScript Content – Các trang có phần nội dung văn bản chỉ xuất hiện sau khi trang được render. Google vẫn có thể đọc nội dung tạo động, nhưng để đảm bảo ổn định, những phần nội dung chính nên được đặt ngay trong HTML gốc.
- Noindex Only in Original HTML – Những trang có thẻ noindex trong HTML ban đầu nhưng không còn trong bản HTML render. Khi Googlebot bắt gặp noindex trong HTML thô, quá trình render sẽ bị bỏ qua. Do Google không chạy JavaScript khi gặp noindex, việc dùng script để xóa thẻ này trong bản render sẽ không có tác dụng. Hãy kiểm tra kỹ các trang có noindex trong HTML gốc để đảm bảo chúng thật sự không cần lập chỉ mục, và gỡ noindex nếu trang cần được index.
- Nofollow Only in Original HTML – Trang có thẻ nofollow trong HTML ban đầu nhưng không xuất hiện trong HTML đã render. Điều này có nghĩa là các liên kết trong HTML thô sẽ không được bot theo dõi trước khi JavaScript chạy. Kiểm tra những trang có nofollow trong HTML gốc để đảm bảo đây là hành vi bạn mong muốn; gỡ nofollow nếu bạn muốn bot thu thập các liên kết đó.
- Canonical Only in Rendered HTML – Các trang chỉ chứa thẻ canonical trong bản render sau khi JavaScript chạy. Google có thể xử lý canonical trong HTML render, tuy nhiên họ khuyến nghị đặt canonical sớm trong HTML gốc để tránh lỗi hoặc tín hiệu xung đột. Hãy thêm canonical vào HTML thô (hoặc header HTTP) thay vì dựa hoàn toàn vào bản render.
- Canonical Mismatch – Những trang có canonical trong HTML gốc khác với canonical có trong HTML sau render. Google có thể đọc canonical từ bản render, nhưng nếu có sự mâu thuẫn, kết quả lập chỉ mục có thể không như mong muốn. Đảm bảo canonical trong HTML thô và HTML render trùng khớp nhau.
- Page Title Only in Rendered HTML – Những trang có thẻ tiêu đề chỉ xuất hiện sau khi JavaScript thực thi. Điều này buộc công cụ tìm kiếm phải render trang để thấy title. Dù Google có thể làm điều này, bạn vẫn nên đưa tiêu đề quan trọng vào HTML gốc.
- Page Title Updated by JavaScript – Các trang có tiêu đề bị JavaScript chỉnh sửa, dẫn đến sự khác biệt giữa title trong HTML thô và title trong HTML render. Google vẫn hiểu được phần chỉnh sửa này, nhưng để giảm sai lệch, tiêu đề nên thống nhất ở HTML gốc.
- Meta Description Only in Rendered HTML – Các trang có thẻ mô tả chỉ được thêm vào sau khi JavaScript chạy. Điều này khiến bot phải render trang để thấy mô tả. Nội dung mô tả quan trọng nên đặt trực tiếp trong HTML ban đầu.
- Meta Description Updated by JavaScript – Những trang có meta description bị JavaScript thay đổi. Nội dung mô tả trong HTML thô và HTML render không trùng nhau. Để tránh xung đột tín hiệu, mô tả nên được đặt chính xác trong HTML tĩnh.
- H1 Only in Rendered HTML – Những trang chỉ có thẻ H1 sau khi JavaScript thực thi. Điều này yêu cầu bot phải render trang để nhận diện chủ đề nội dung. Bạn nên đưa H1 vào HTML gốc để giữ cấu trúc nội dung rõ ràng.
- H1 Updated by JavaScript – Các trang có H1 bị JavaScript chỉnh sửa, dẫn đến sự khác biệt giữa HTML ban đầu và HTML render. Đảm bảo H1 quan trọng được xác định ngay trong HTML gốc để tránh tín hiệu mâu thuẫn.
- Uses Old AJAX Crawling Scheme URLs – Các URL vẫn đang dùng kiểu AJAX cũ (#!) mà Google đã chính thức ngừng hỗ trợ vào tháng 10/2015. Hãy cập nhật URL theo chuẩn hiện nay và cân nhắc hỗ trợ server-side rendering, pre-render hoặc dynamic rendering nếu cần.
- Uses Old AJAX Crawling Scheme Meta Fragment Tag – Các URL chứa meta fragment cho thấy website vẫn đang chạy cơ chế AJAX lỗi thời đã bị khai tử từ năm 2015. Cần cập nhật theo tiêu chuẩn JavaScript hiện đại. Nếu thẻ meta fragment tồn tại do sai sót, hãy gỡ bỏ hoàn toàn.
4.6. Monitor Blocked Resources
Hãy theo dõi các mục xuất hiện dưới bộ lọc “Pages With Blocked Resources” trong tab JavaScript. Bạn có thể quan sát nhanh ở khung tổng quan bên phải mà không cần mở hẳn tab. Nếu những tài nguyên quan trọng như JavaScript, CSS hoặc hình ảnh bị robots.txt chặn, không phản hồi hoặc trả lỗi, điều này sẽ làm ảnh hưởng đến quá trình render, crawl và lập chỉ mục.
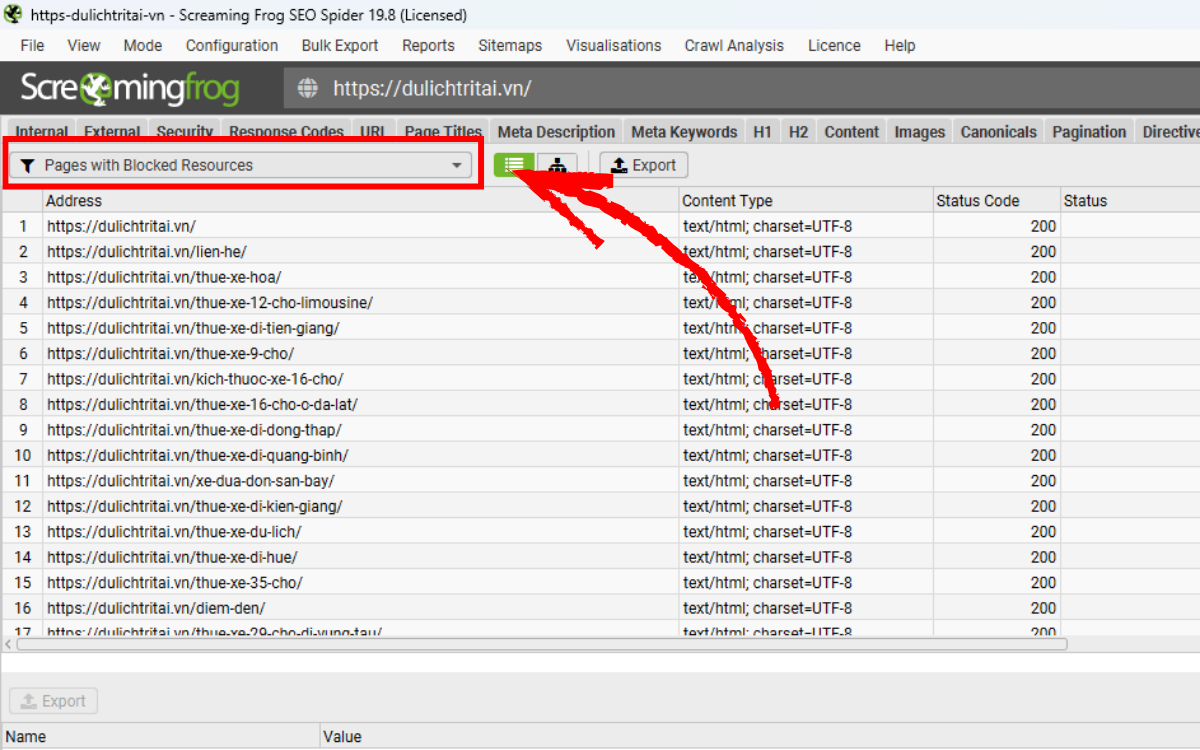
Bạn cũng có thể xem các tài nguyên bị chặn của từng trang thông qua tab Rendered Page, nằm ngay cạnh ảnh chụp trang đã render trong khu vực màn hình phía dưới. Với các website phụ thuộc nhiều vào JavaScript, nếu JS bị chặn hoàn toàn thì việc crawl gần như không thể thực hiện được.
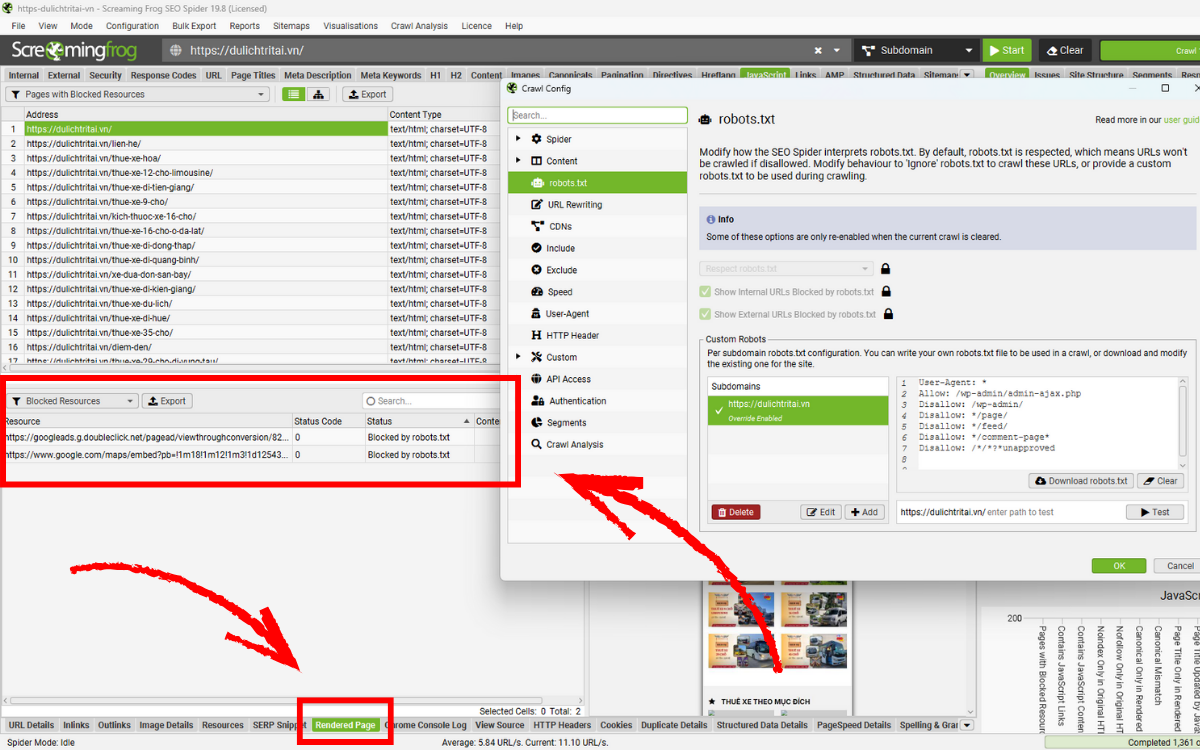
Nếu những tài nguyên quan trọng bị chặn khiến việc render không đầy đủ, bạn cần mở quyền truy cập cho chúng, hoặc sử dụng robots.txt tùy chỉnh để cho phép chúng được crawl. Công cụ cũng cho phép bạn kiểm tra nhiều trường hợp khác nhau bằng cách kết hợp tính năng exclude và custom robots.txt.
Bạn có thể xem chi tiết từng tài nguyên bị chặn trong mục Response Codes > Blocked Resource.
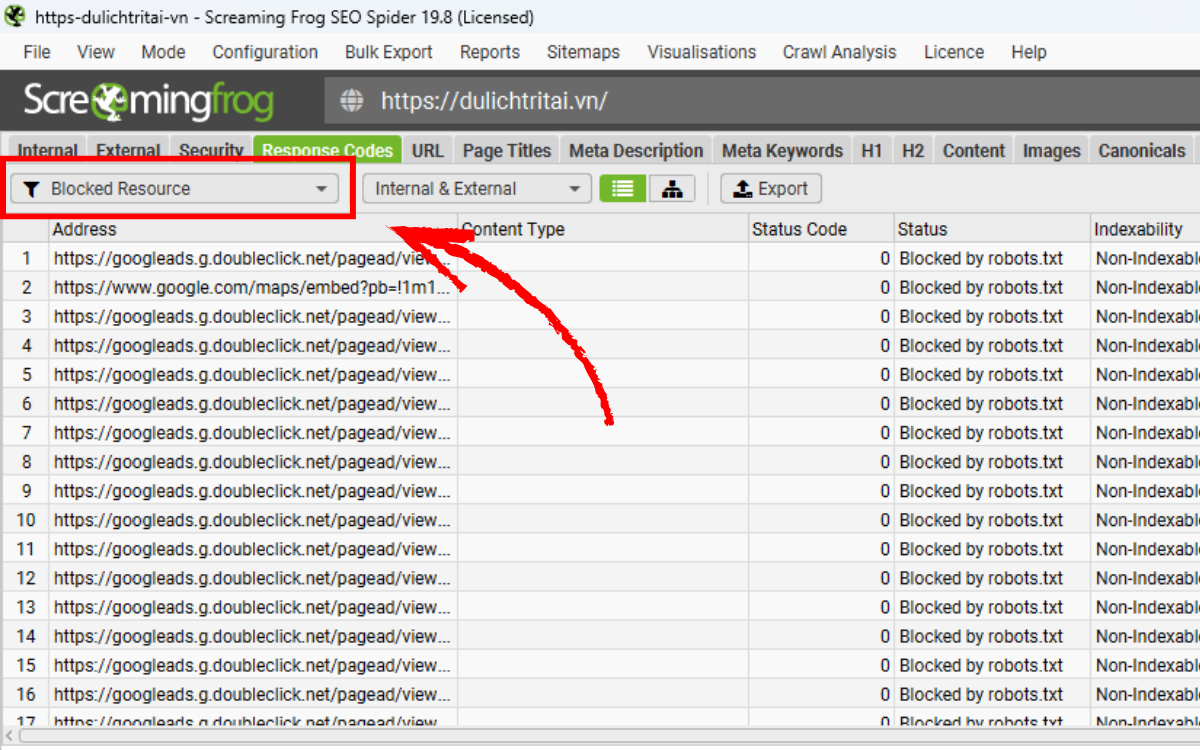
Nếu muốn xuất toàn bộ danh sách kèm theo những trang chứa liên kết tới các tài nguyên bị chặn này, bạn có thể dùng báo cáo:
Chọn Bulk Export > Response Codes > Blocked Resource Inlinks
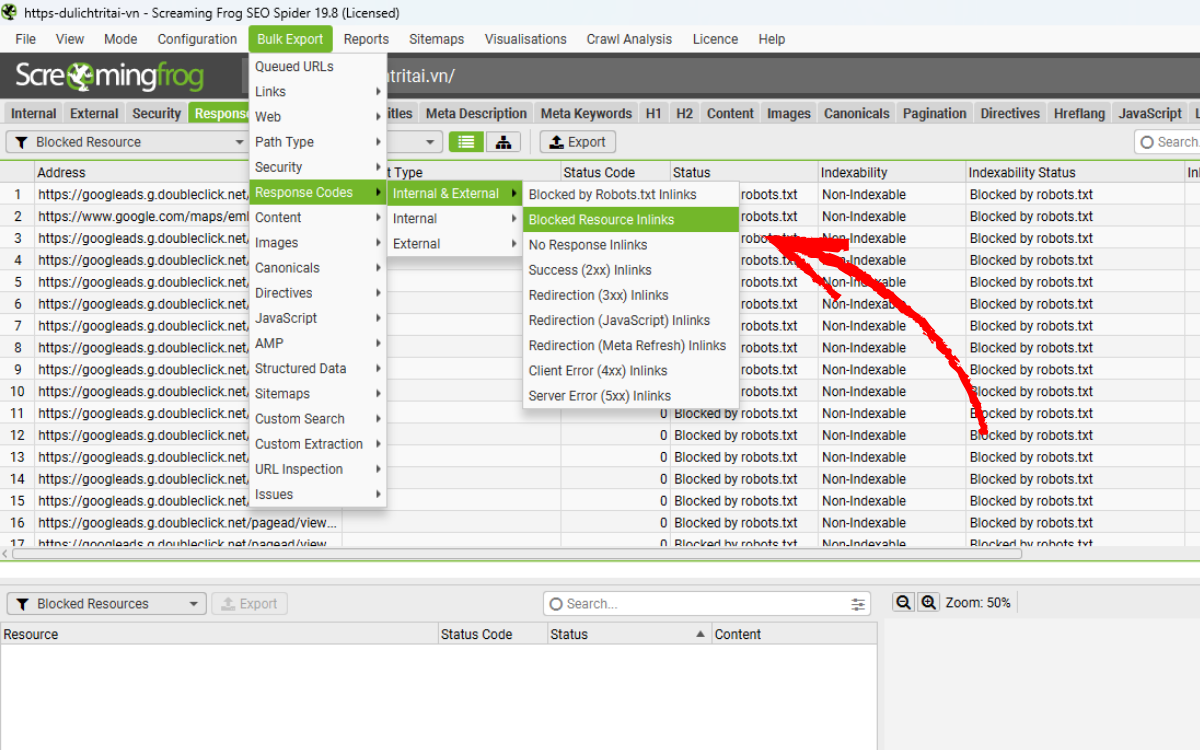
4.7. View Rendered Pages
Khi crawl ở chế độ JavaScript, bạn có thể xem ảnh chụp của trang đã được render trong tab Rendered Page (nằm ở cửa sổ dưới), chỉ cần chọn URL ở danh sách phía trên.
Xem trang đã render giúp bạn hình dung chính xác nội dung mà một bot hiện đại có thể nhìn thấy. Điều này đặc biệt hữu ích khi bạn kiểm tra website trên môi trường staging, nơi bạn không thể sử dụng công cụ URL Inspection của Google Search Console.
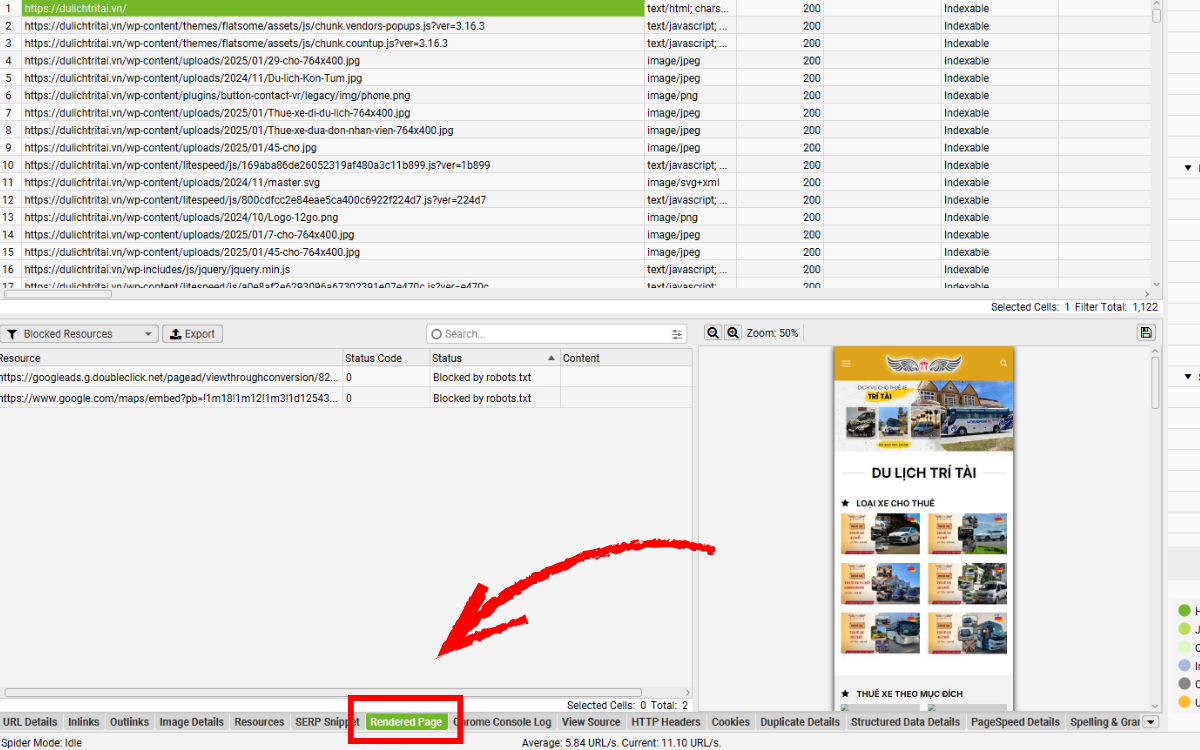
Nếu ảnh render hiển thị lỗi hoặc thiếu nội dung, và nguyên nhân không phải do tài nguyên bị chặn, bạn có thể cần tăng thời gian AJAX timeout hoặc xem xét kỹ hơn mã HTML sau render để phân tích thêm.
4.8. Compare Raw & Rendered HTML & Visible Content
Trong quá trình làm việc với trang dùng JavaScript, đôi khi bạn sẽ muốn lưu lại cả HTML gốc và HTML đã render để tiện so sánh. Bạn có thể bật tính năng này trong:
Chọn Configuration > Spider > Extraction và đánh dấu vào tùy chọn “store HTML” và “store rendered HTML”.
Sau khi bật, cửa sổ view source ở phần dưới sẽ hiển thị cả hai phiên bản HTML để giúp bạn so sánh và xác nhận rằng nội dung quan trọng hoặc liên kết đã xuất hiện trong DOM. Nhấn “Show Differences” để xem bảng so sánh chi tiết giữa HTML gốc và HTML render.
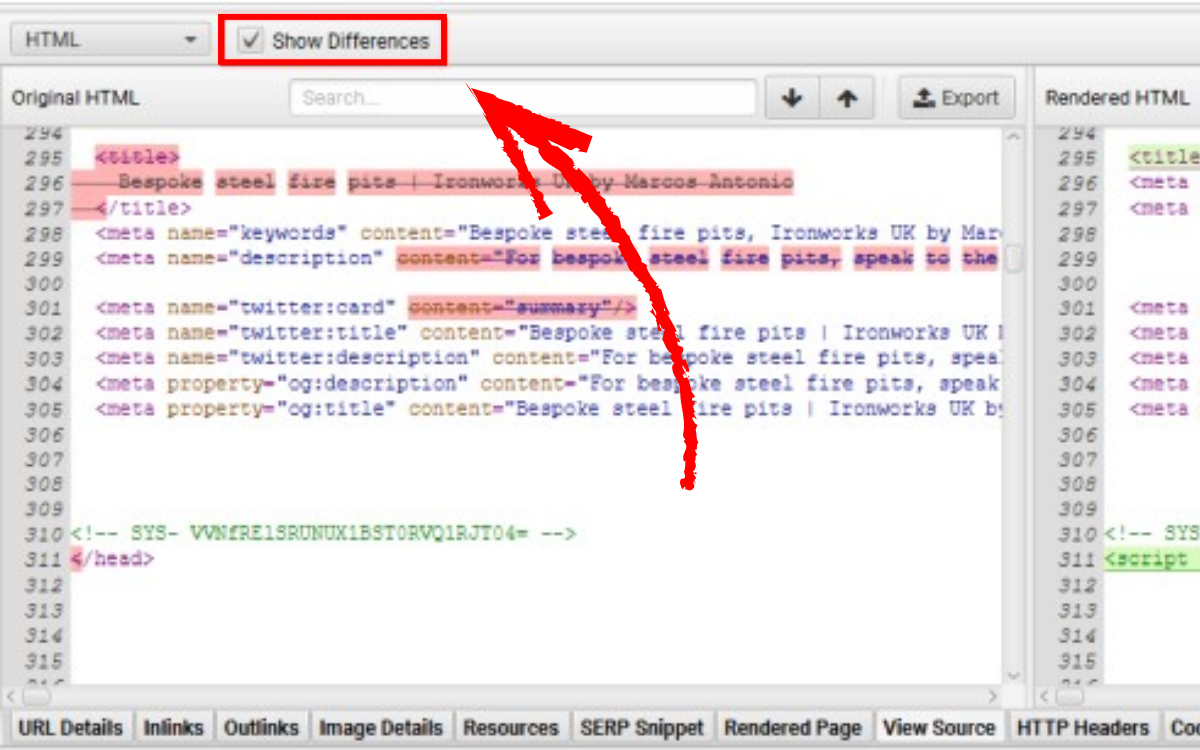
Tính năng này cực kỳ hữu ích khi bạn cần kiểm tra khác biệt giữa những gì trình duyệt hiển thị và những gì SEO Spider thu thập, hoặc khi muốn xem JavaScript đã xử lý trang như thế nào và liệu có thành phần nào bị thay đổi hay không.
Nếu bộ lọc JavaScript Content được kích hoạt cho một trang, bạn có thể chuyển sang chế độ xem Visible Content để xác định chính xác đoạn văn bản nào chỉ xuất hiện trong HTML đã render.

4.9. Identify JavaScript Only Links
Khi bộ lọc Contains JavaScript Links được kích hoạt, bạn có thể xem các liên kết chỉ xuất hiện trong HTML sau khi JavaScript chạy bằng cách chọn URL tương ứng ở danh sách trên, sau đó mở tab Outlinks ở phần dưới và chuyển bộ lọc nguồn liên kết sang Rendered HTML.
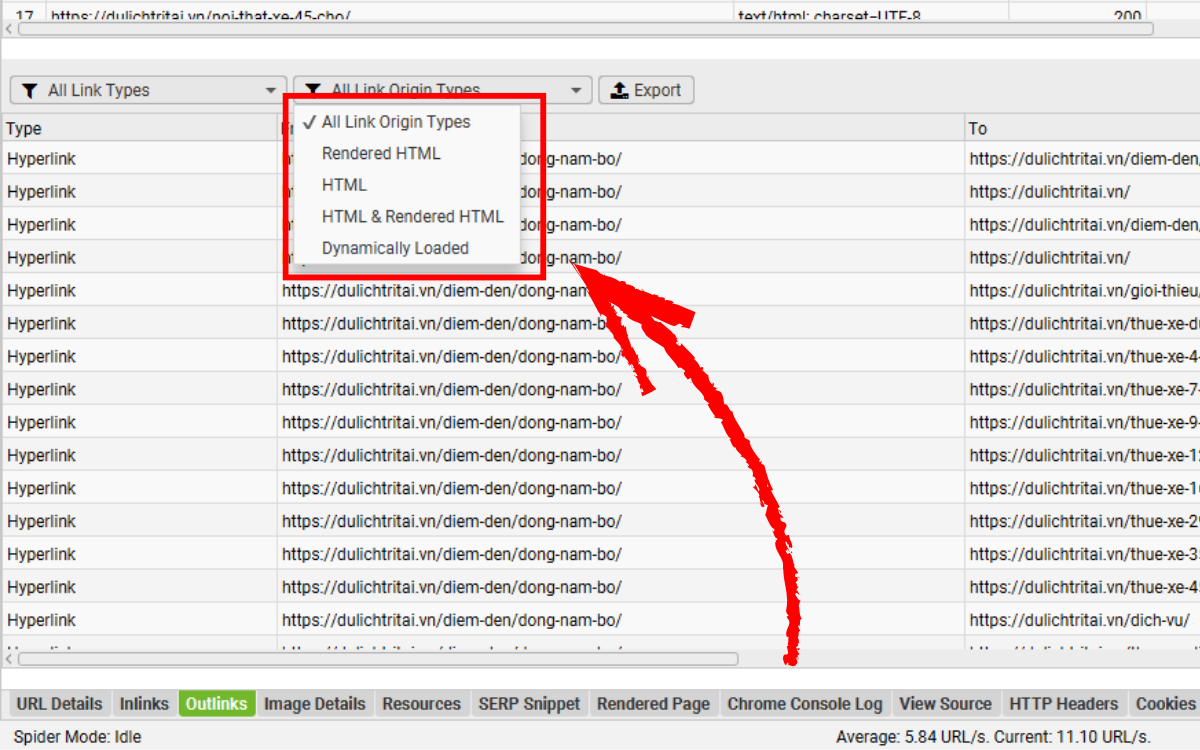
Cách này cực kỳ hữu ích trong các tình huống mà chỉ một số liên kết — chẳng hạn link sản phẩm trên trang danh mục — được tải bằng JavaScript. Bạn cũng có thể xuất toàn bộ danh sách liên kết phụ thuộc vào JavaScript qua báo cáo:
Chọn Bulk Export > JavaScript > Contains JavaScript Links
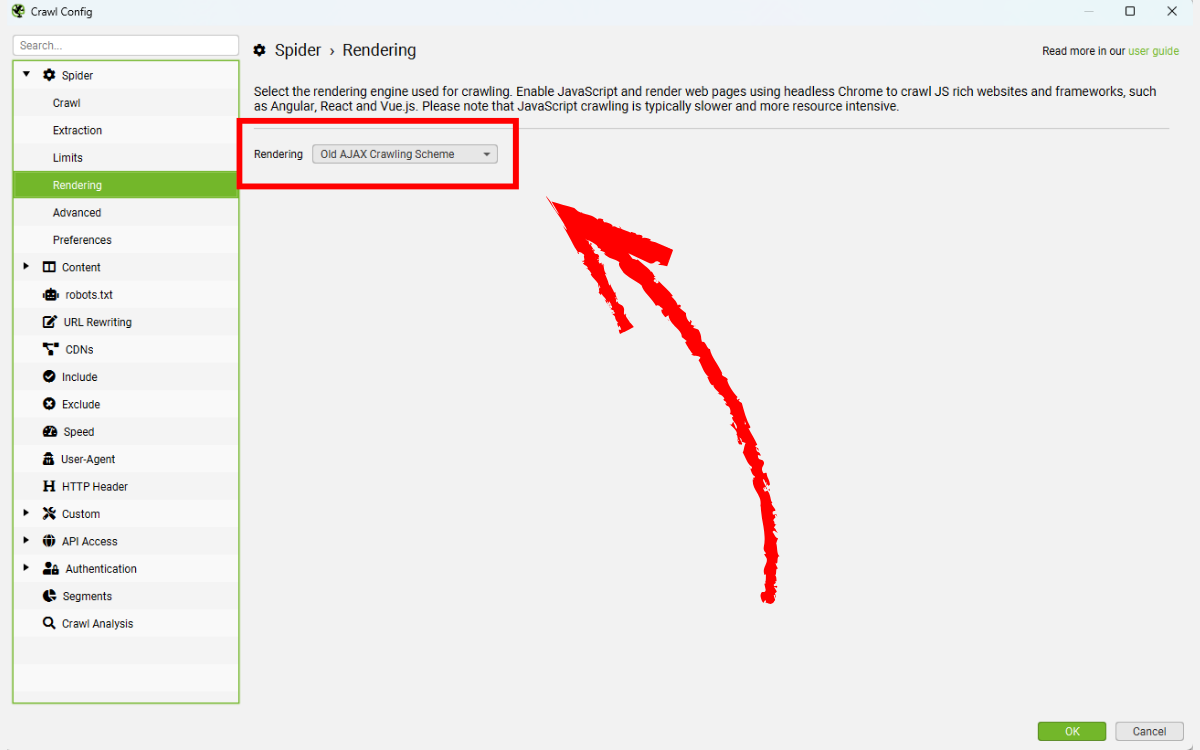
4.10. Adjust The AJAX Timeout
Dựa trên kết quả crawl, bạn có thể thay đổi thời điểm SEO Spider chụp lại phiên bản render của trang bằng cách điều chỉnh AJAX timeout, vốn mặc định là 5 giây. Bạn có thể chỉnh trong:
Chọn Configuration > Spider > Rendering (khi ở chế độ JavaScript rendering).
Thời gian 5 giây thường phù hợp với đa số website. Googlebot cũng linh hoạt hơn, vì họ dựa vào thời gian tải thực tế của trang và lượng hoạt động mạng, đồng thời họ cũng sử dụng cache mạnh mẽ. Tuy nhiên, Google không đợi quá lâu nội dung quan trọng phải được tải sớm, nếu không sẽ không được thu thập hoặc lập chỉ mục.
Lưu ý rằng quá trình crawl của SEO Spider thường tiêu tốn nhiều tài nguyên hơn so với Googlebot khi crawl theo thời gian dài. Điều này khiến website phản hồi chậm hơn bình thường và buộc bạn phải tăng AJAX timeout.
Bạn sẽ biết cần tăng timeout khi:
- Website không crawl được đầy đủ,
- Thời gian phản hồi trong tab Internal vượt quá 5 giây,
- Hoặc trang trong tab Rendered Page không hiển thị đúng, bị thiếu hoặc không render thành công.
5. Kết Luận
Qua nội dung trên, Công Ty Seo Lenart đã chia sẻ cho bạn quy trình kiểm tra và thu thập dữ liệu các website sử dụng JavaScript bằng Screaming Frog SEO Spider một cách đầy đủ và dễ hiểu — từ việc nhận diện những phần phụ thuộc vào JavaScript, xử lý tài nguyên bị chặn, cho đến so sánh HTML gốc và HTML render nhằm đảm bảo nội dung quan trọng đều được bot nhìn thấy.
Hy vọng hướng dẫn này sẽ giúp bạn tối ưu khả năng lập chỉ mục, cải thiện cấu trúc website và hạn chế các rủi ro kỹ thuật liên quan đến JavaScript trong quá trình SEO.
Nếu bạn chưa từng thử, hãy mở Screaming Frog và bắt đầu crawl website của mình bằng chế độ JavaScript ngay hôm nay. Chỉ cần một vài thiết lập cơ bản, bạn sẽ phát hiện được những vấn đề mà trước đây rất khó nhận ra — và từ đó nâng cấp hiệu suất SEO của toàn bộ trang.









