Duplicate content là một trong những vấn đề âm thầm nhưng ảnh hưởng trực tiếp đến chất lượng và khả năng hiển thị của website. Khi nhiều trang có nội dung giống hoặc gần giống nhau, người dùng dễ bị rối, hệ thống xếp hạng cũng khó xác định đâu là trang quan trọng nhất. Điều này không chỉ khiến website thiếu mạch lạc mà còn làm giảm hiệu quả triển khai nội dung về lâu dài. Trong quá trình làm việc với các dự án kỹ thuật, LENART nhận thấy đây là lỗi phổ biến ở hầu hết website – từ cấu trúc URL chưa chặt chẽ, nội dung được sao chép, cho đến việc tự động tạo ra nhiều trang tương tự nhau.
Với bài viết này, Công ty TNHH LENART sẽ hướng dẫn bạn cách kiểm tra duplicate content một cách chính xác bằng công cụ Screaming Frog. Bạn cũng sẽ thấy rõ quy trình LENART áp dụng khi xử lý nội dung trùng lặp trong thực tế. Đây sẽ là nền tảng giúp website vận hành rõ ràng, ổn định và nhất quán hơn về mặt nội dung.
1. Duplicate content là gì? Tại sao lại quan trọng trong SEO?
Nội dung trùng lặp làm hệ thống tìm kiếm khó xác định trang chính, làm giảm tín hiệu liên quan và ảnh hưởng thứ hạng. Chúng thường do lỗi kỹ thuật (URL trùng lặp, http/https) hoặc sao chép/tự viết nội dung quá giống nhau. Phát hiện và xử lý duplicate content là bước kỹ thuật bắt buộc để giữ website ổn định và dễ tối ưu.
1.1. Khái niệm duplicate content

Nội dung trùng lặp là tình trạng hai hoặc nhiều trang trên cùng một website có nội dung giống hoặc gần giống nhau. Có hai dạng chính: trùng lặp chính xác (giống 100%) và trùng lặp gần giống (có sự thay đổi nhỏ), trong đó dạng gần giống phổ biến hơn, khó phát hiện bằng mắt thường và thường xuất hiện ở mô tả sản phẩm, trang danh mục, hoặc các trang dịch vụ.
1.2. Nguyên nhân dẫn đến trùng lặp nội dung trong SEO
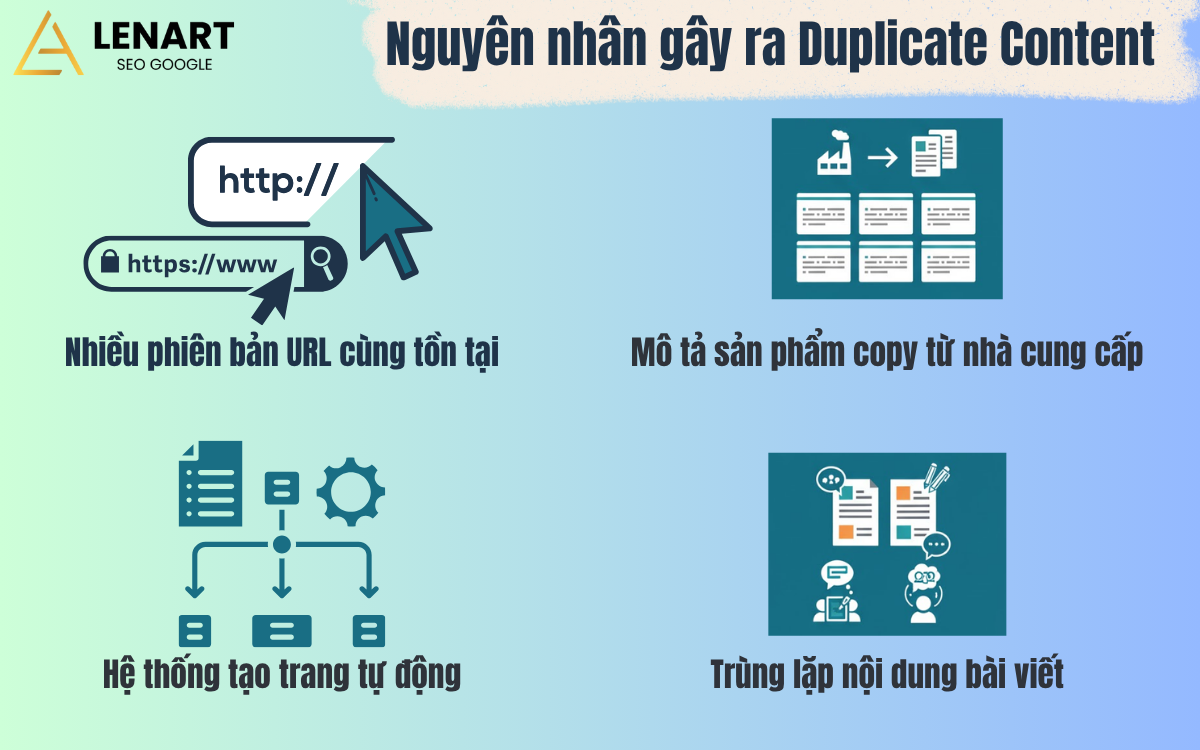
Các nguyên nhân chính gây ra duplicate content, được chia thành hai nhóm chính:
- Lỗi kỹ thuật và Cấu hình hệ thống:
- Nhiều phiên bản URL cùng hoạt động: Lỗi phổ biến nhất là khi các phiên bản như http/https hoặc www/non-www đều có thể truy cập, tạo ra nhiều URL cho cùng một trang. Đây là nhóm lỗi mà LENART thường gặp và xử lý đầu tiên trong các dự án mới.
- Hệ thống tạo trang tự động: Xảy ra trên các website thương mại điện tử, khi hệ thống tạo ra nhiều trang biến thể sản phẩm (SKU) có cùng mô tả hoặc các trang tìm kiếm nội bộ/lọc dữ liệu không được kiểm soát.
- Vấn đề Nội dung và Quy trình:
- Sử dụng dữ liệu từ nhà cung cấp: Nhiều website đăng mô tả sản phẩm y hệt từ nhà sản xuất. Điều này gây ra trùng lặp không chỉ trong nội bộ mà còn trùng với nhiều đối thủ cạnh tranh khác.
- Nội dung tự soạn bị trùng lặp: Xảy ra khi nhiều bài viết/trang dịch vụ cùng nhắm vào một chủ đề hoặc khu vực, khiến tác giả lặp lại các đoạn mô tả cốt lõi. Khả năng trùng lặp càng tăng nếu website có nhiều biên tập viên thiếu quy trình kiểm soát nội dung.
1.3. Ảnh hưởng tiêu cực của nội dung trùng lặp

Các ảnh hưởng chính của duplicate content đối với hiệu suất và cấu trúc website:
- Làm giảm sự rõ ràng của website: Nội dung trùng lặp khiến hệ thống tìm kiếm không thể ưu tiên trang nào là quan trọng nhất, làm giảm khả năng xuất hiện của các trang đích giá trị.
- Phân tán tín hiệu và giá trị: Nội dung giống nhau nằm rải rác khiến giá trị và thẩm quyền của trang bị chia nhỏ, không thể tập trung vào một trang mạnh. Đây là lý do LENART luôn thực hiện check trùng lặp nội dung trước khi triển khai kế hoạch nội dung mới.
- Ảnh hưởng tiêu cực đến trải nghiệm người dùng: Người dùng dễ gặp các trang gần giống nhau, gây rối loạn và thiếu điều hướng rõ ràng, dẫn đến việc họ rời trang sớm vì thiếu tính nhất quán.
- Lãng phí tài nguyên hệ thống: Nội dung trùng nhau buộc hệ thống phải xử lý các trang không cần thiết, gây áp lực lên website.
Khi sự trùng lặp được tạo ra với mục đích thao túng thứ hạng hoặc số lần hiển thị trong kết quả tìm kiếm (ví dụ: tạo ra các trang nội dung kém chất lượng, chỉ thay đổi vài từ khóa), Google sẽ coi đây là hành vi spam và có thể bị xử lý nghiêm khắc theo Chính sách về nội dung rác. Do đó, nhiệm vụ của LENART SEOer là kiểm tra và giải quyết vấn đề trùng lặp bằng Screaming Frog để đảm bảo tính minh bạch, ổn định và tránh mọi rủi ro liên quan đến việc phân loại là nội dung thao túng hoặc duplicate content.
2. Các bước kiểm tra nội dung trùng lặp bằng Screaming Frog
Quy trình kiểm tra duplicate content sử dụng Screaming Frog để phát hiện các trang giống nhau hoặc gần giống nhau. Việc này giúp bạn làm rõ trang chính, nhóm các lỗi, và lên kế hoạch khắc phục để tối ưu hóa SEO.
2.1. Bước 1: Chuẩn bị công cụ và thiết lập cấu hình
Bước đầu tiên bạn cần cài Screaming Frog bản miễn phí hoặc trả phí. Bản miễn phí giới hạn 500 URL nhưng đủ cho website nhỏ. Khi mở công cụ, bạn cần kiểm tra lại cấu hình thu thập dữ liệu. Mục tiêu của bước này là tạo môi trường chính xác để cách kiểm tra trùng lặp nội dung cho ra kết quả đúng.
Vào mục Configuration → Spider và bật thu thập toàn bộ HTML. Bạn nên bật thêm chế độ lấy nội dung, ảnh, và rendering nếu website dùng script nhiều. Việc chuẩn bị đúng cấu hình giúp công cụ hoạt động như một Duplicate content checker, giảm lỗi khi phân tích và tăng độ chính xác khi xác định trang trùng.
2.2. Bước 2: Bật chế độ Near Duplicates
Cài đặt này nằm trong Configuration → Content → Duplicates. Đây là bước quan trọng vì phần lớn website không chỉ trùng lặp hoàn toàn mà còn có nhiều trang Near duplicate. Khi bật chế độ này, công cụ sẽ dùng thuật toán MinHash để tính điểm tương đồng giữa các trang. Việc bật tính năng này giúp bạn thấy cả những trang không giống 100% nhưng vẫn trùng ý và trùng cấu trúc.
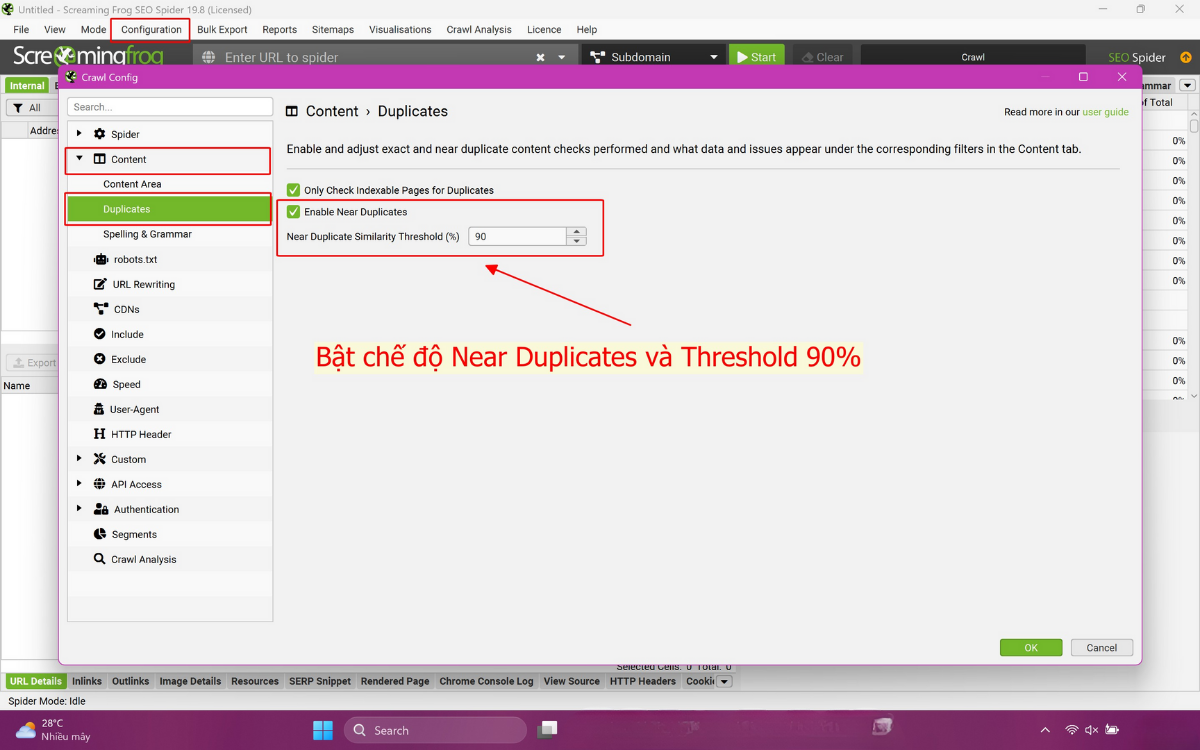
Bạn nên giữ mức nhận diện Threshold mặc định 90% để lọc trang giống nhau rõ ràng. Với website lớn hoặc có nhiều nội dung tự động, mức này giúp bạn check trùng lặp nội dung chính xác. Đây là cài đặt bắt buộc để phân tích sâu trong Duplicate trong SEO.
2.3. Bước 3: Chọn đúng khu vực nội dung cần phân tích
Việc chọn đúng vùng nội dung giúp kết quả rõ ràng hơn, vào Configuration → Content → Area để loại bỏ các thành phần lặp nhiều như header, footer, menu, side-bar. Nếu không loại trừ các vùng này, công cụ có thể cho rằng các trang giống nhau dù nội dung chính khác nhau.
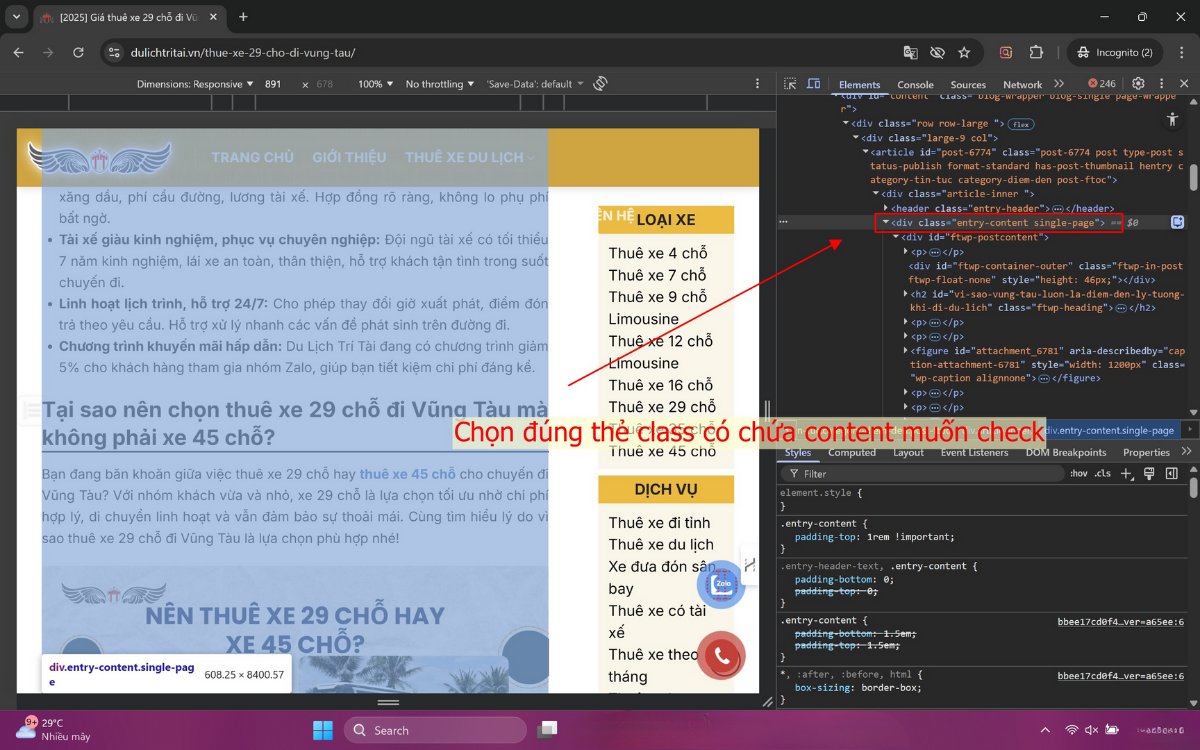
Nếu chỉ ưu tiên check content trong các phần nội dung blog/sản phẩm, tìm đúng tên class của vùng chứa nội dung và chọn mode Include để giới hạn nội dung cần check.
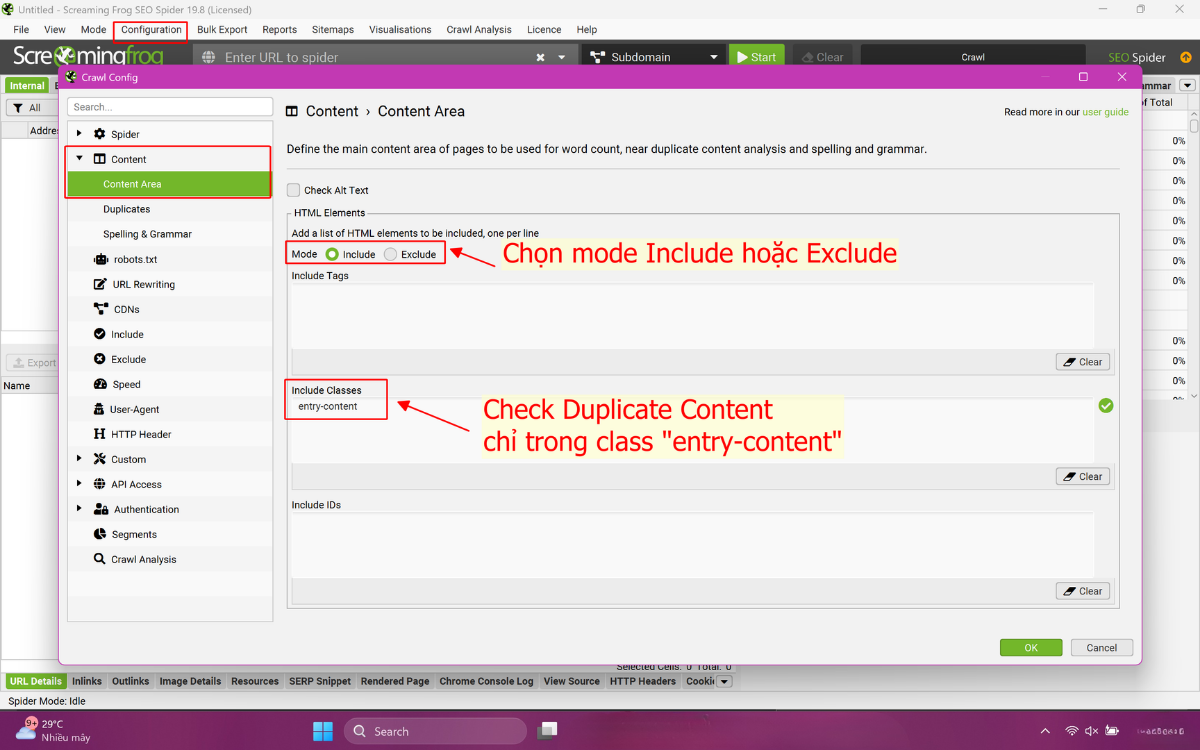
Việc chọn đúng vùng nội dung là cách nâng độ chính xác khi kiểm tra bài viết bị trùng lặp hoặc lọc phần mô tả sản phẩm. Khi thiết lập đúng, bạn dễ xác định trang nào thuộc duplicate group, trang nào chỉ giống ở phần giao diện.
2.4. Bước 4: Crawl website

Nhập domain website và nhấn Start để chạy thu thập dữ liệu. Công cụ sẽ duyệt toàn bộ URL và ghi lại nội dung để phân tích. Khi thu thập xong, bạn sẽ thấy số lượng trang đủ dữ liệu để kiểm tra.
2.5. Bước 5: Kiểm tra duplicate content
Truy cập tab Content và xem hai phần: Exact Duplicates và Near Duplicates. Đây là nơi công cụ hiển thị các trang giống nhau. Các trang giống hoàn toàn sẽ nằm trong nhóm Exact. Các trang chỉ giống một phần sẽ nằm trong nhóm Near.
Bạn có thể lọc theo từng loại để ưu tiên xử lý. Phần này giúp bạn phát hiện lỗi ngay lập tức và biết trang nào cần xem trước. Đây là bước quan trọng trong cách kiểm tra trùng lặp nội dung, nhất là khi bạn muốn loại bỏ trang gây nhầm lẫn.
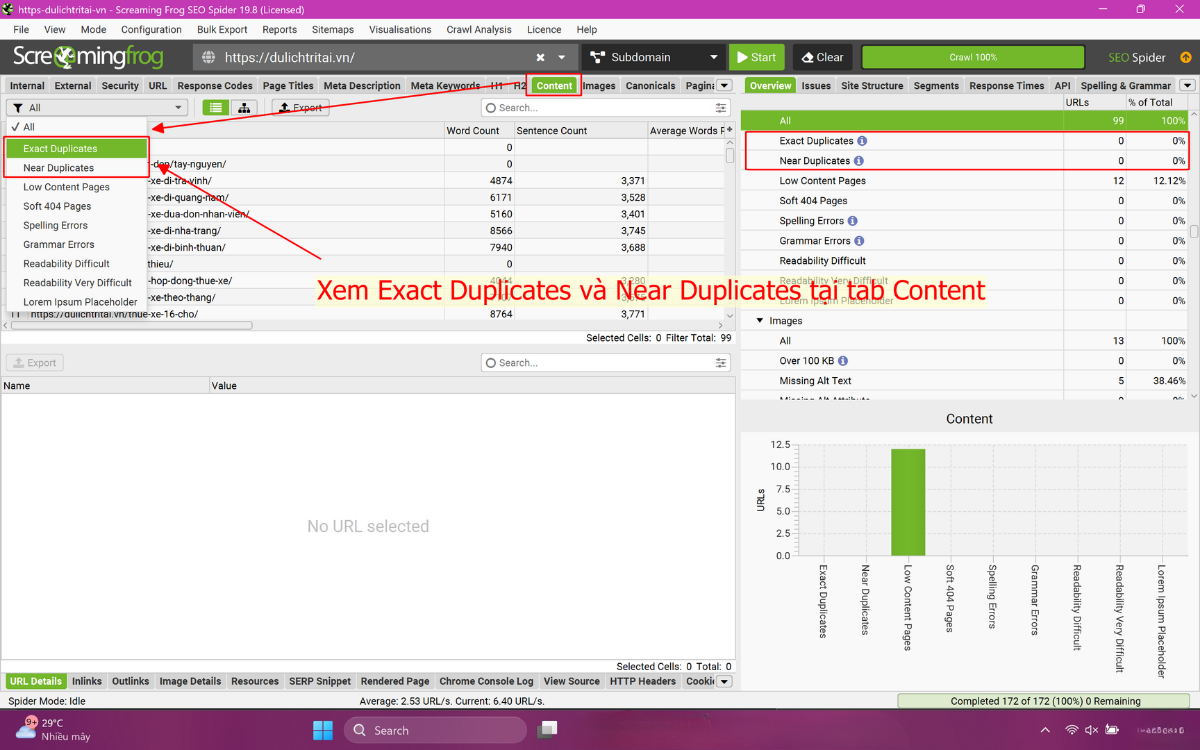
Trong hình minh họa, Screaming Frog hiển thị mức trùng lặp nội dung bằng 0. Kết quả này có được vì LENART luôn ưu tiên xây dựng nội dung rõ ràng ngay từ giai đoạn nghiên cứu từ khóa và kiểm soát dữ liệu content onsite theo quy trình chặt chẽ.
2.6. Bước 6: Phân tích kết quả trùng lặp
Khi phần Near Duplicates chưa hiển thị, bạn cần chạy thêm Crawl Analysis. Đây là chức năng cho phép Screaming Frog tạo mức độ giống nhau giữa các trang. Công cụ sẽ tính điểm Similarity Score và xác định trang giống nhất trong từng nhóm.

Việc phân tích giúp bạn biết mức độ trùng lặp nặng hay nhẹ. Các trang có điểm tương đồng cao cần được loại bỏ nội dung trùng lặp hoặc viết lại. Đây là bước giúp đảm bảo bạn hiểu toàn cảnh và quyết định cách xử lý hợp lý.
2.7. Bước 7: Xem từng URL bị trùng lặp nội dung
Vào mục Duplicate Details để xem từng trang bị trùng (nếu website có duplicate content), mục này hiển thị nội dung nào giống và nội dung nào khác, giúp bạn dễ đánh giá chất lượng từng trang. Công cụ còn hiển thị trang giống nhất, giúp bạn quyết định trang nào làm trang chính.
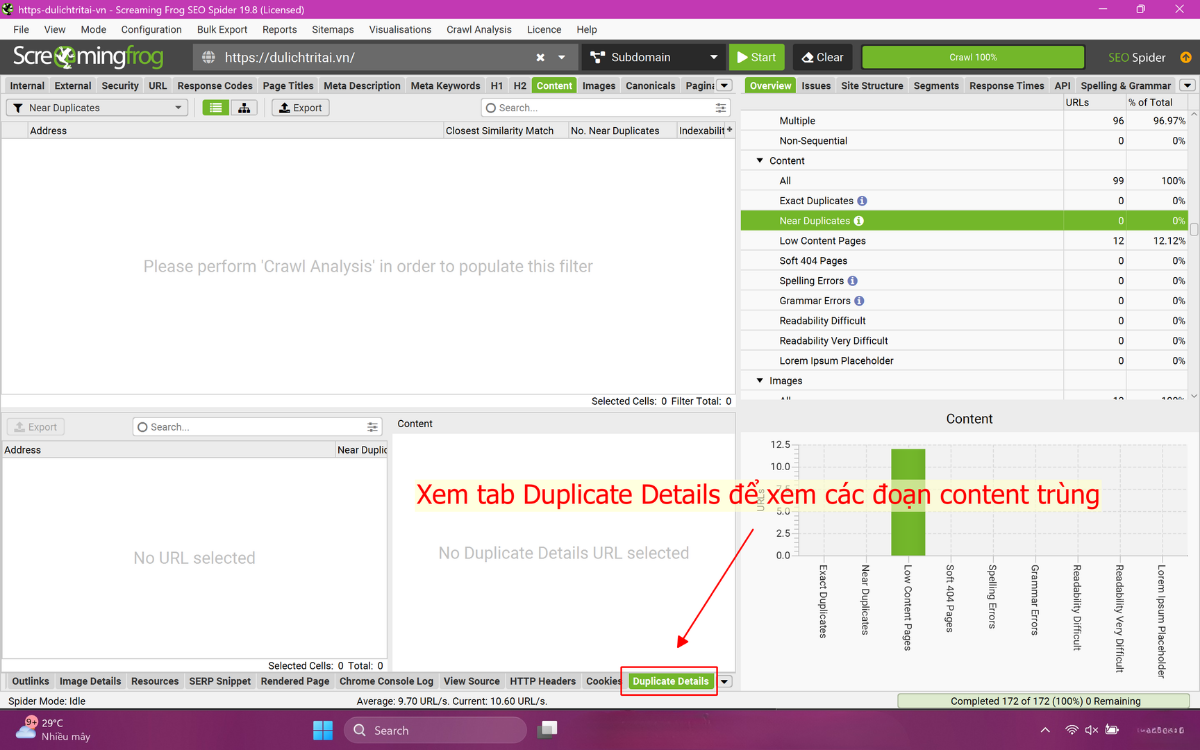
Đây là phần quan trọng khi Kiểm tra bài viết bị trùng lặp hoặc trang sản phẩm có mô tả giống nhau. Xem từng URL giúp bạn đánh giá chính xác từng trường hợp.
2.8. Bước 8: Xuất báo cáo dữ liệu trùng lặp
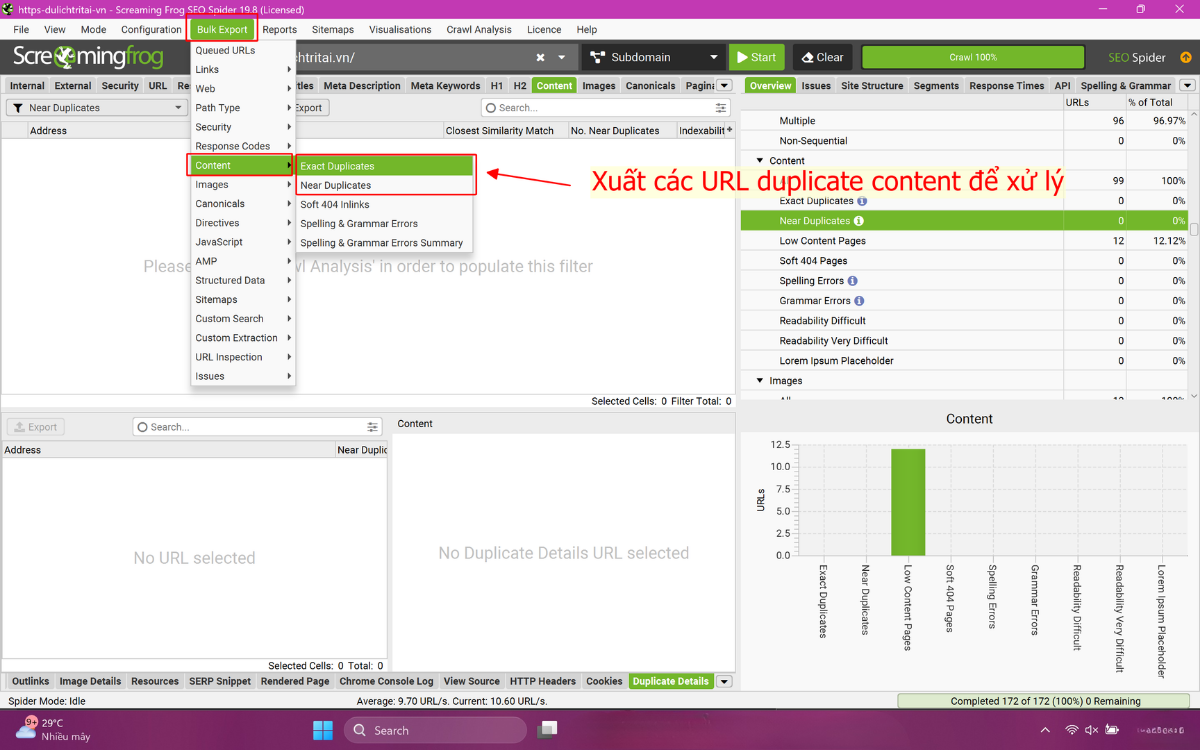
Vào Bulk Export → Content → All Duplicate Details để tải toàn bộ dữ liệu thành file CSV. File này giúp bạn xem toàn bộ nhóm duplicate content, mức độ trùng lặp và danh sách URL. Đây là tài liệu quan trọng để lên kế hoạch xử lý.
2.9. Bước 9: Tinh chỉnh kết quả
Bạn có thể điều chỉnh lại Similarity Threshold và Content Area sau khi crawl xong mà không cần thu thập lại website. Việc này giúp tăng hoặc giảm số lượng trang Near Duplicate được phát hiện.
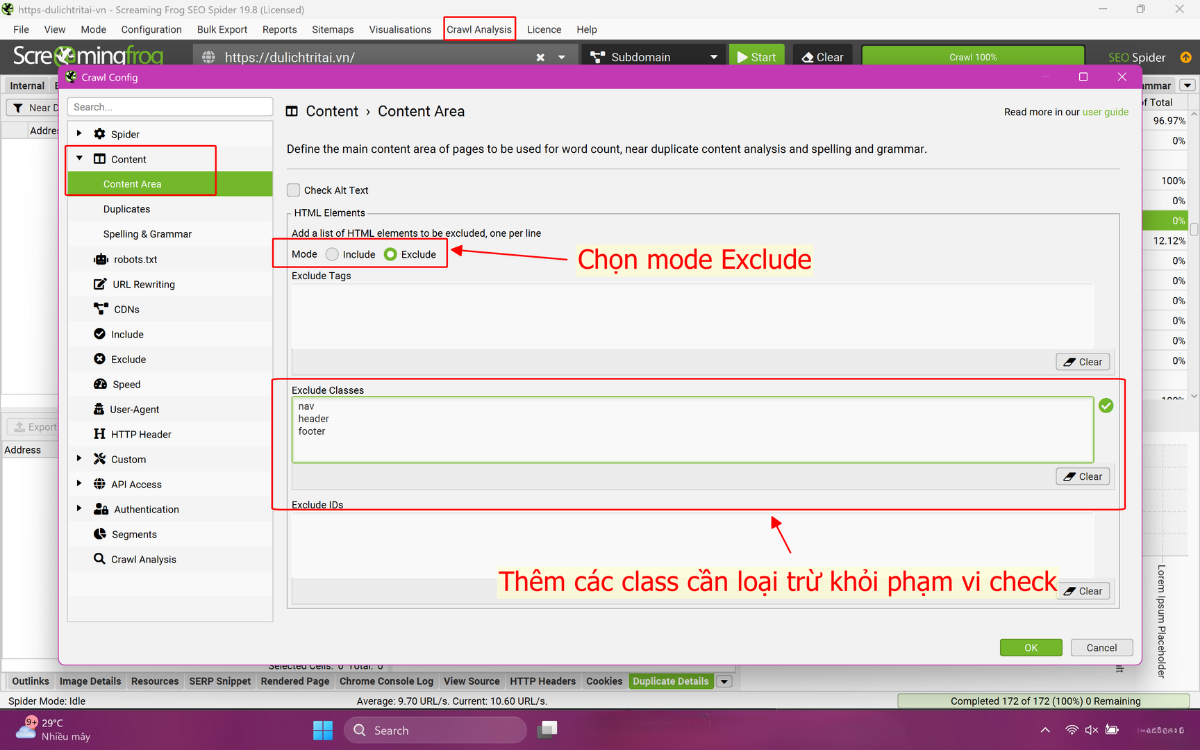
Nếu website có phần giao diện nằm ngoài khu vực nội dung chính, như menu di động, bạn cần loại trừ thành phần này trong mục Config → Content → Area → Exclude Classes. Khi loại bỏ đúng khu vực không liên quan, kết quả phân tích sẽ tập trung vào nội dung chính xác hơn. Sau khi tinh chỉnh, bạn chạy lại Crawl Analysis để có kết quả sạch và rõ ràng hơn.
3. Cách Lenart kiểm tra duplicate content trên website
Quy trình của LENART được xây dựng để phát hiện và xử lý duplicate content dựa trên nền tảng Kiến thức SEO rõ ràng và có thể áp dụng lại cho nhiều dự án. Khi nhận một website mới, đội kỹ thuật luôn thực hiện check trùng lặp nội dung trong tuần đầu để đánh giá hiện trạng. Việc này giúp xác định các URL trùng nhau, các nhóm nội dung near duplicate, và những khu vực cần ưu tiên chỉnh sửa.
3.1. Bước 1: Check duplicate content khi mới nhận dự án
Khi bắt đầu một dự án, LENART luôn kiểm tra cấu trúc URL trước. Phòng kỹ thuật sẽ xác định xem website có chạy đồng thời nhiều phiên bản như http/https hoặc www/non-www hay không. Đây là lỗi phổ biến làm xuất hiện nhiều nội dung giống nhau ở các URL khác nhau. Việc chuẩn hóa các phiên bản ngay từ đầu giúp giảm đáng kể lỗi trùng lặp.
3.2. Bước 2: Thu thập dữ liệu nội dung trùng lặp

Sau khi kiểm tra cấu trúc URL, LENART tiến hành thu thập toàn bộ dữ liệu bằng công cụ phù hợp. Screaming Frog được dùng như một Duplicate content checker để lấy danh sách trang trùng hoàn toàn và trang Near Duplicate. File dữ liệu này giúp xem toàn cảnh các nhóm nội dung giống nhau.
Bước này giúp nhận biết mức độ trùng lặp nặng hay nhẹ. Nếu website có nhiều trang danh mục hoặc nhiều biến thể sản phẩm, bạn sẽ thấy các nhóm nội dung giống nhau xuất hiện rõ trong dữ liệu. Việc thu thập dữ liệu giúp đưa ra danh sách URL cần xử lý theo đúng mức độ ưu tiên.
3.3. Bước 3: Phân loại duplicate content và giải pháp xử lý cho từng loại
Sau khi có danh sách dữ liệu, LENART tiến hành phân loại theo 4 dạng chính.
| Loại Duplicate Content | Mô tả | Dấu hiệu nhận biết | Giải pháp xử lý |
| Trùng URL do cấu trúc (URL Variants) | Nhiều phiên bản URL cùng hiển thị một nội dung | http/https, www/non-www, có hoặc không có dấu “/” cuối URL | Redirect 301 về một phiên bản chuẩn |
| Trùng lặp hoàn toàn (Exact Duplicate) | Nội dung giống 100% giữa các trang | Trang mẫu, trang copy, bài viết bị trùng hoàn toàn | Loại bỏ nội dung trùng lặp, xóa trang phụ hoặc hợp nhất nội dung |
| Trùng lặp gần giống (Near Duplicate) | Nội dung giống nhau phần lớn, chỉ khác vài câu | Trang dịch vụ theo khu vực, mô tả sản phẩm lặp lại | Rewrite nội dung, tăng sự khác biệt, bổ sung nội dung độc nhất |
| Nội dung không cần thiết / thừa | Trang sinh tự động, trang không mang giá trị | Tag pages, archive pages, trang rỗng | Xóa trang, hoặc hợp nhất vào trang chính |
| Nội dung cần giữ một bản gốc (Canonical Case) | Nhiều trang trùng nhưng chỉ muốn giữ 1 trang chính | Trang tương tự chủ đề, URL có tham số | Chọn 1 trang làm bản gốc, điều hướng hoặc hợp nhất phần còn lại |
3.4. Bước 4: Kiểm tra định kỳ
Sau khi xử lý trùng lặp, LENART thực hiện kiểm tra định kỳ để tránh nội dung phát sinh lỗi mới. Website thay đổi liên tục, vì vậy cần kiểm tra lại mỗi tháng hoặc sau các đợt đăng nội dung lớn. Việc kiểm tra định kỳ nội dung trùng lặp giúp LENART phát hiện sớm lỗi và tiếp tục giữ cấu trúc rõ ràng.
Việc kiểm soát duplicate content cần được thực hiện thường xuyên để giữ website rõ ràng và ổn định. Khi áp dụng đúng quy trình kiểm tra và xử lý, bạn có thể tránh nhầm lẫn nội dung, giảm các nhóm content trùng lặp và nâng chất lượng toàn bộ trang. Quy trình của LENART giúp bạn phát hiện lỗi sớm, xử lý đúng trọng tâm và duy trì cấu trúc nội dung mạch lạc. Nếu bạn đang xây dựng chiến lược dài hạn, hãy xem việc check trùng lặp nội dung bằng Screaming Frog là bước Technical SEO bắt buộc để website phát triển bền vững.
Tác giả: Minh Châu – Nhân sự Technical SEO LENART









