Audit PDF SEO là quá trình kiểm tra và đánh giá toàn diện các file PDF trên website, bao gồm liên kết, metadata, nội dung và khả năng index, nhằm đảm bảo các tài liệu PDF không gây ảnh hưởng tiêu cực đến hiệu suất SEO tổng thể. Đối với nhiều website doanh nghiệp, giáo dục hoặc B2B tại Việt Nam – nơi PDF thường được dùng cho báo giá, tài liệu kỹ thuật hoặc whitepaper – việc audit PDF SEO định kỳ là bước quan trọng nhưng thường bị bỏ qua.
Trên thực tế, các file PDF vẫn có thể được Google crawl, index và hiển thị trên kết quả tìm kiếm tương tự như trang HTML. Trong một số trường hợp, PDF có thể bị chặn crawl ngoài ý muốn, vì vậy bạn nên kết hợp kiểm tra với hướng dẫn kiểm tra robots.txt bằng Screaming Frog. Vì vậy, nếu không được audit và kiểm soát đúng cách, PDF có thể gây ra các vấn đề như broken links, trùng lặp nội dung hoặc phân tán sức mạnh SEO. Với Screaming Frog, bạn có thể crawl và phân tích PDF để trích xuất thuộc tính, nội dung và liên kết, từ đó phục vụ quá trình audit PDF SEO một cách có hệ thống và hiệu quả hơn.

1. Audit Links Trong PDFs
Trong quy trình audit PDF SEO, việc kiểm tra các liên kết bên trong file PDF là một bước quan trọng nhằm đánh giá mức độ ảnh hưởng của tài liệu đến trải nghiệm người dùng cũng như khả năng crawl của công cụ tìm kiếm. Các liên kết bị lỗi (broken links) không chỉ làm gián đoạn hành trình đọc nội dung mà còn ảnh hưởng tiêu cực đến độ tin cậy tổng thể của website dưới góc độ SEO. Đặc biệt, những liên kết trỏ ra ngoài dẫn đến trang không còn tồn tại cần được ưu tiên xử lý sớm, vì chúng tác động trực tiếp đến trải nghiệm người dùng và mức độ uy tín của tài liệu. Về mặt kỹ thuật, công cụ tìm kiếm có thể phát hiện và crawl các liên kết trong PDF tương tự như HTML. Nếu bạn muốn tìm hiểu chi tiết hơn về cách phát hiện và xử lý link lỗi bằng công cụ này, hãy xem thêm hướng dẫn tìm link lỗi bằng Screaming Frog. Tuy nhiên cách triển khai sẽ khác nhau tùy thuộc vào việc bạn crawl toàn bộ website để tìm file PDF hay đã có sẵn danh sách URL của các tài liệu này.
1.1. Crawl Website
Trong chế độ Spider mode thông thường, Screaming Frog sẽ tự động phát hiện các file PDF nếu chúng được liên kết nội bộ. Công cụ sẽ crawl file PDF, sau đó phát hiện và báo cáo các liên kết bên trong đó.
Nhập tên miền vào thanh URL và nhấn Start.
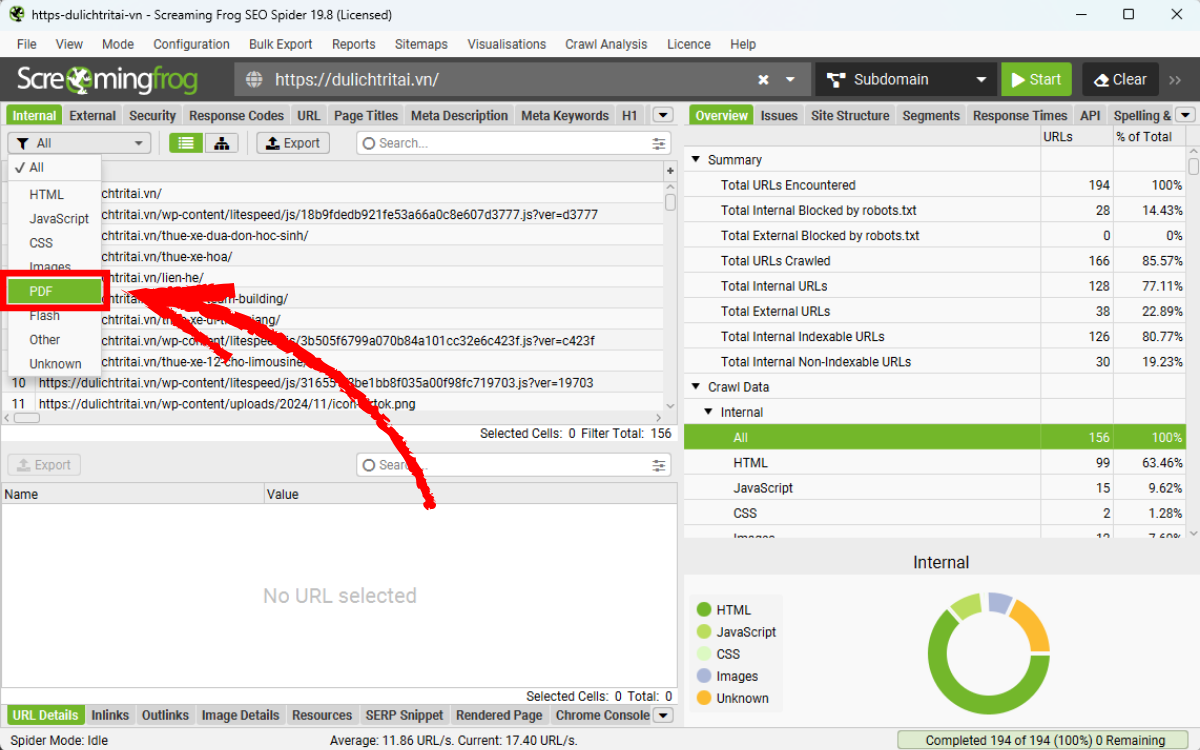
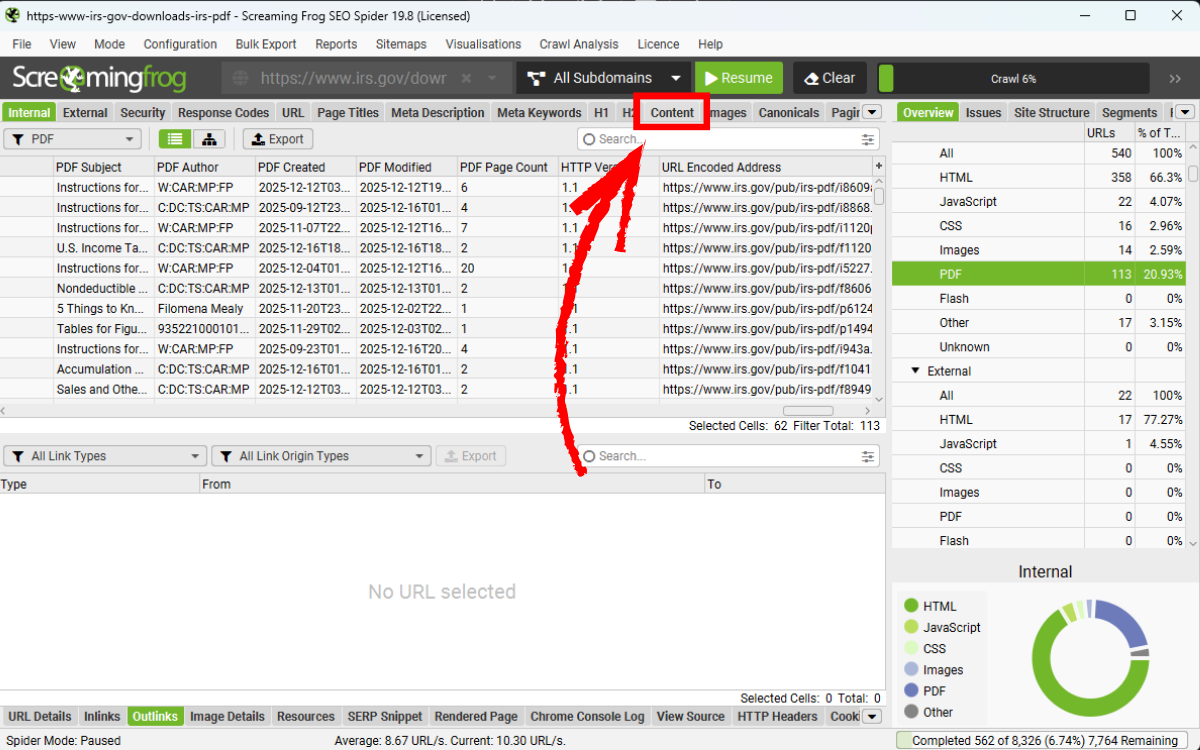
Các file PDF được liên kết sẽ xuất hiện dưới tab Internal với filter PDF.
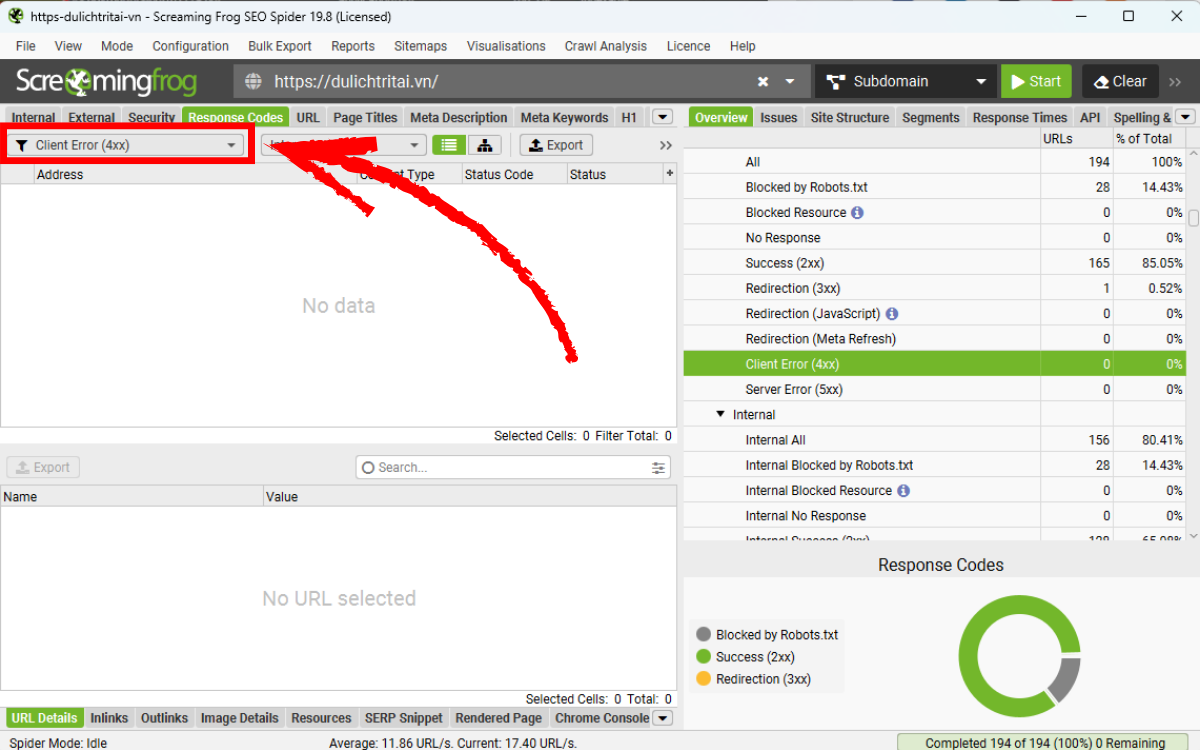
Để kiểm tra broken links trong PDF, bạn hãy xem tab Response Codes và chọn filter Client Error (4xx).
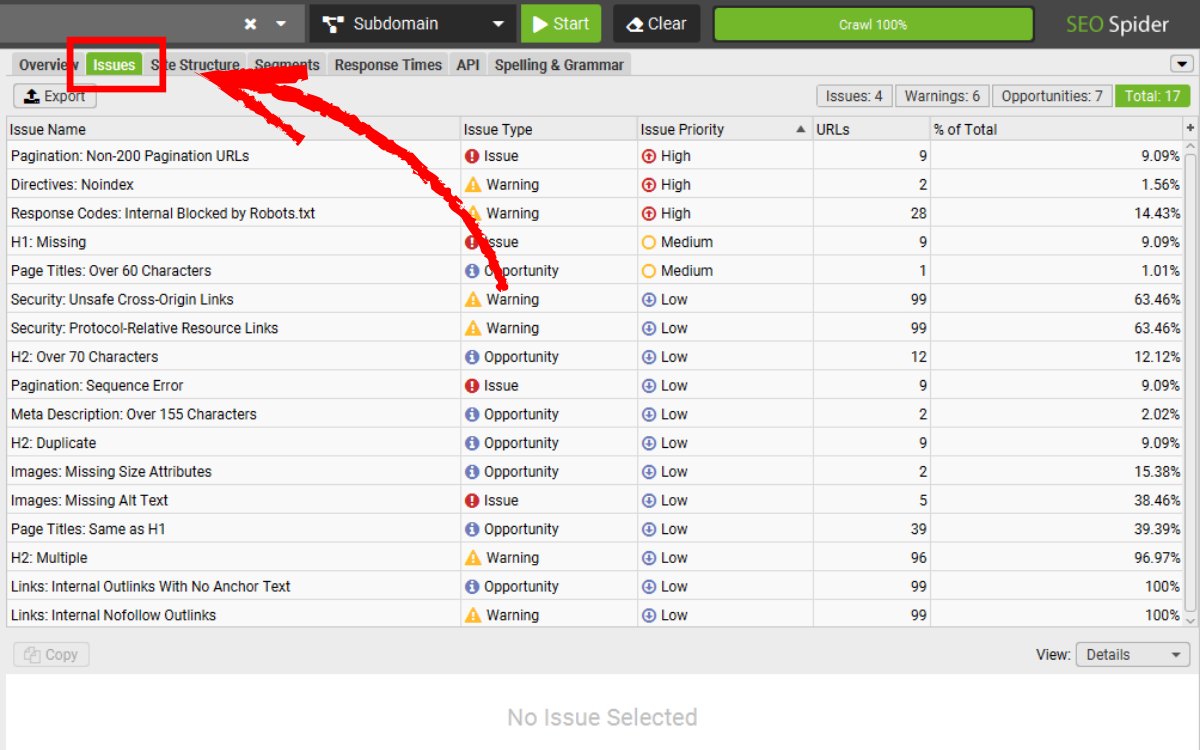
Hoặc bạn có thể sử dụng tab Issues, nơi các lỗi, cảnh báo hoặc cơ hội tối ưu được flagged tự động.
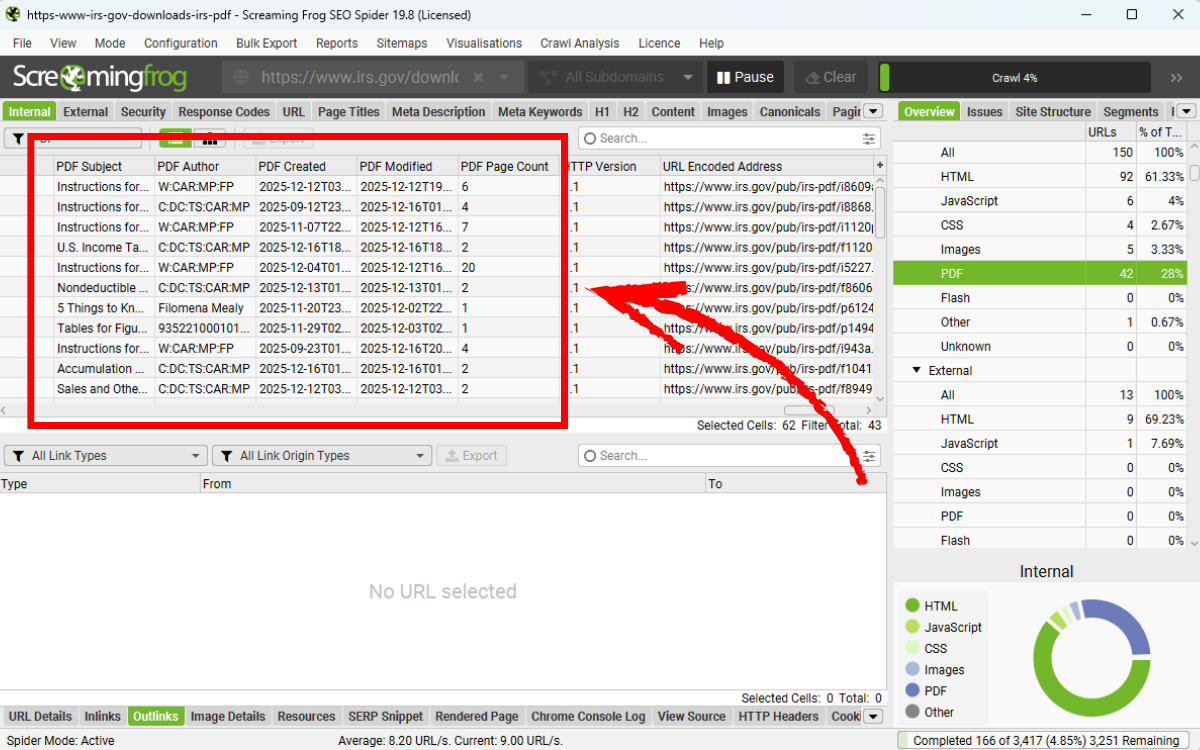
Để xác định nguồn của broken links, hãy kiểm tra tab Inlinks ở phía dưới. Click vào hình để phóng to.
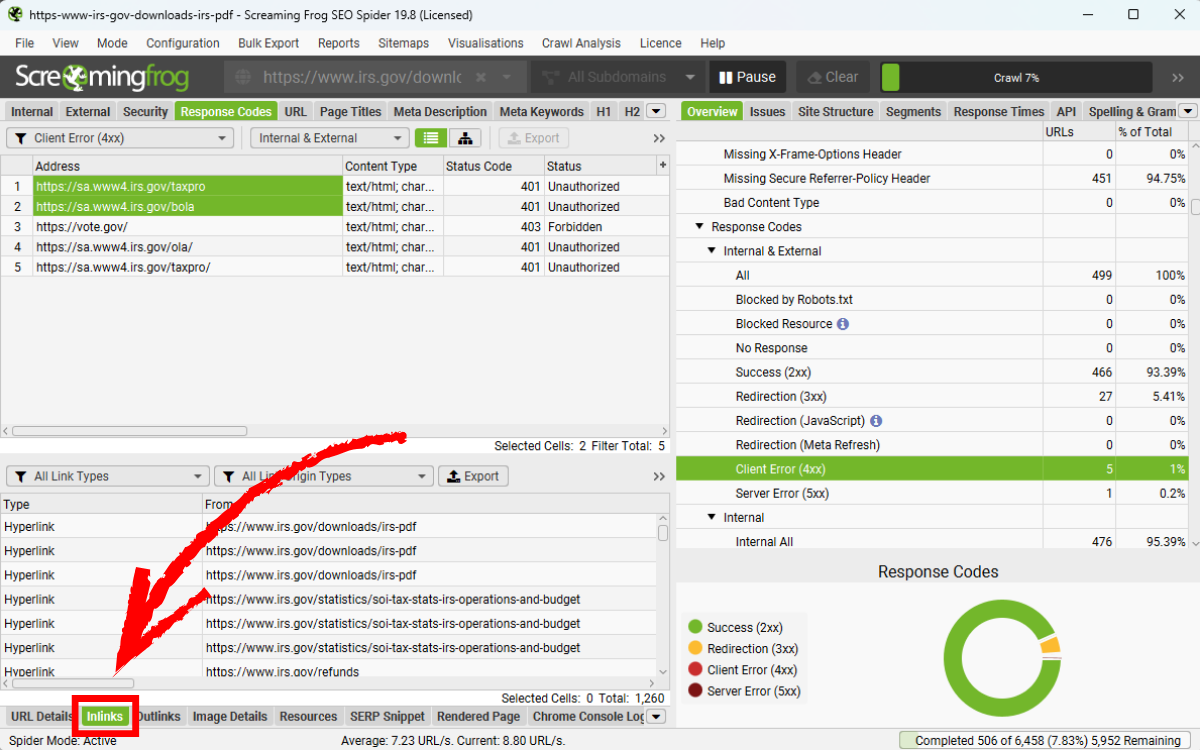
Tab Inlinks sẽ hiển thị loại tệp (type) là PDF đối với các broken links nằm trong file PDF, đi kèm URL của PDF, anchor text và số trang phát hiện lỗi.
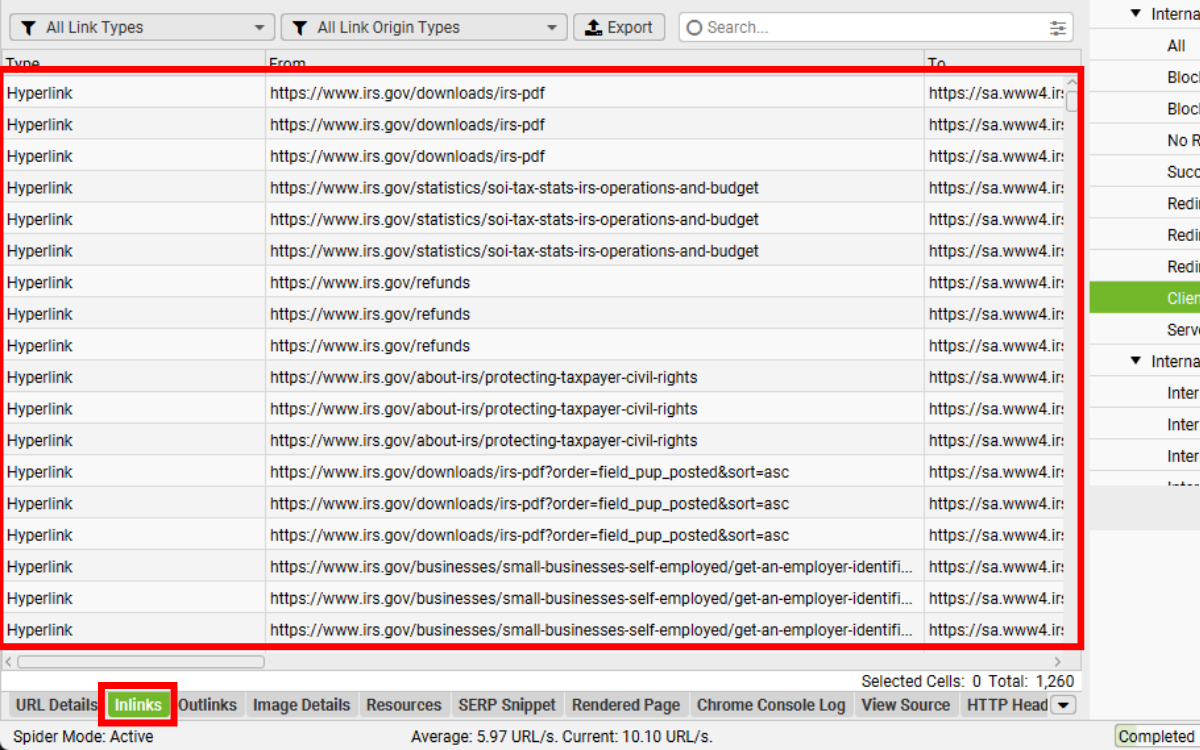
Bạn có thể xuất dữ liệu hàng loạt qua đường dẫn: Bulk Export > Response Codes > Internal & External > Client Error (4xx) Inlinks.
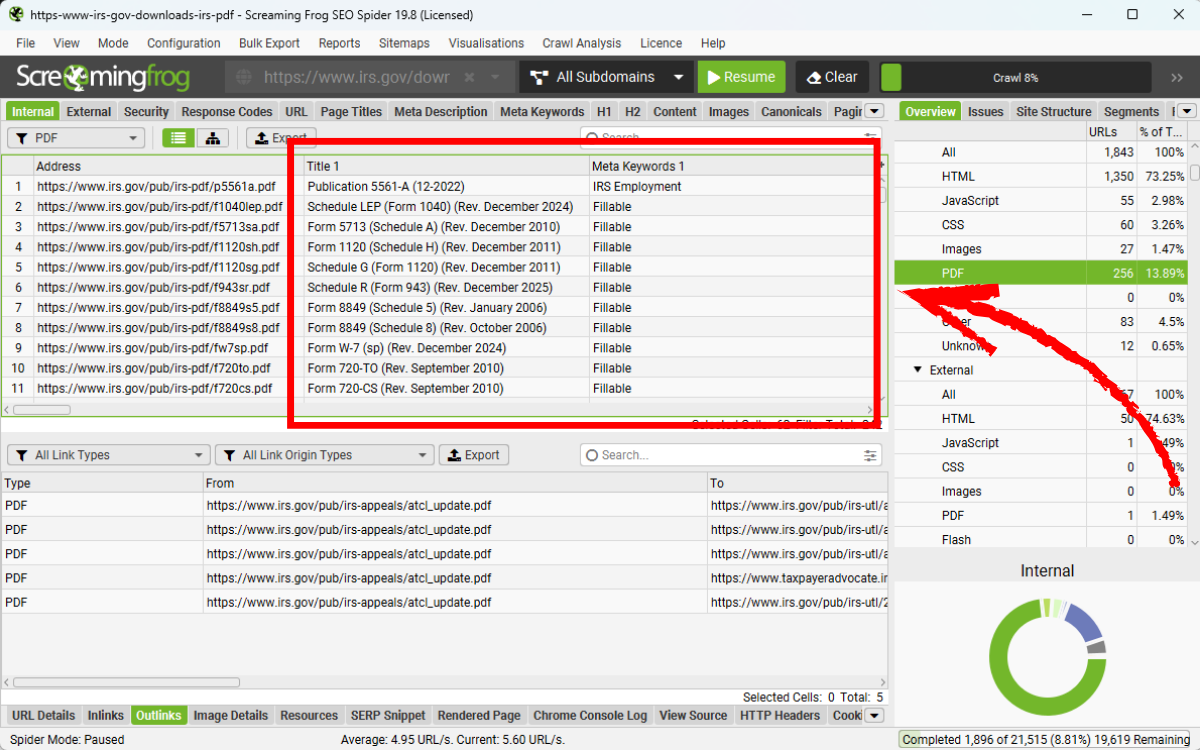
Để xem danh sách tất cả liên kết trong PDF, bạn hãy bôi đen các file PDF trong tab Internal, sau đó chọn tab Outlinks ở phía dưới. Tab này sẽ hiển thị chi tiết các liên kết mà file PDF đó chứa.
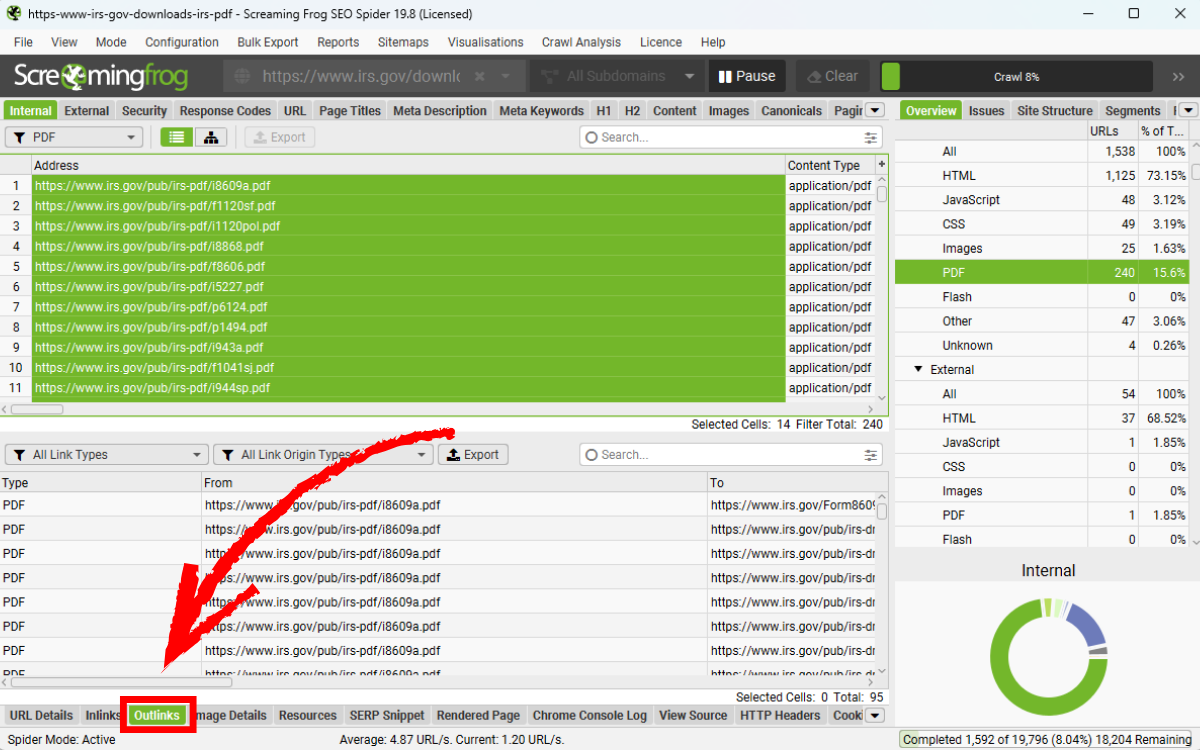
Bạn có thể export dữ liệu này bằng nút Export ở khung phía dưới, chuột phải chọn Export > Outlinks hoặc sử dụng menu Bulk Export.
1.2. Crawl List PDFs
Trong audit PDF SEO, List mode đặc biệt hữu ích khi bạn cần rà soát các file PDF đã tồn tại lâu trên website hoặc được upload rời rạc. Cách tiếp cận này tương tự như phương pháp crawl danh sách URL, cho phép bạn audit từng nhóm tài nguyên một cách chủ động hơn. Nếu bạn muốn crawl danh sách URL PDF có sẵn, hãy chuyển sang chế độ List mode qua Mode > List và dán danh sách vào mục Upload > Paste.
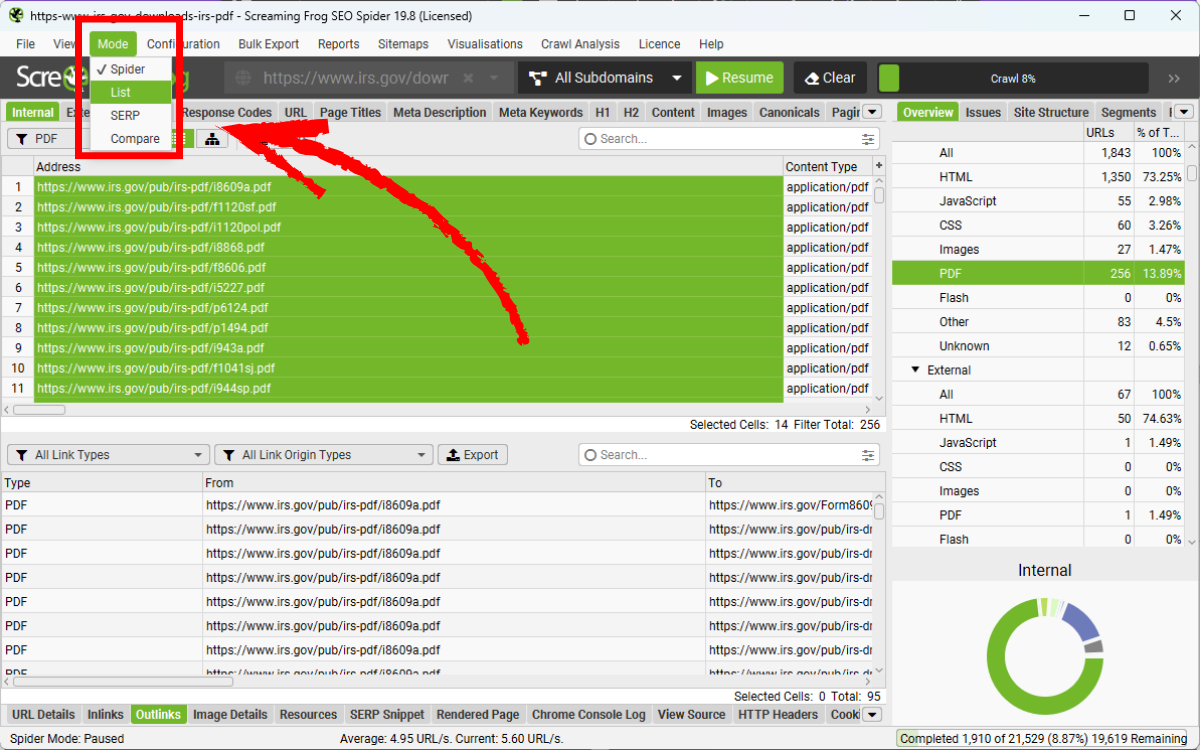
Lưu ý: Chế độ List mode mặc định chỉ crawl các file PDF mà không crawl các liên kết bên trong chúng. Để crawl outlinks trong PDF, bạn cần điều chỉnh cấu hình: Config > Spider > Limits, thay đổi Limit Crawl Depth từ ‘0’ thành ‘1’.
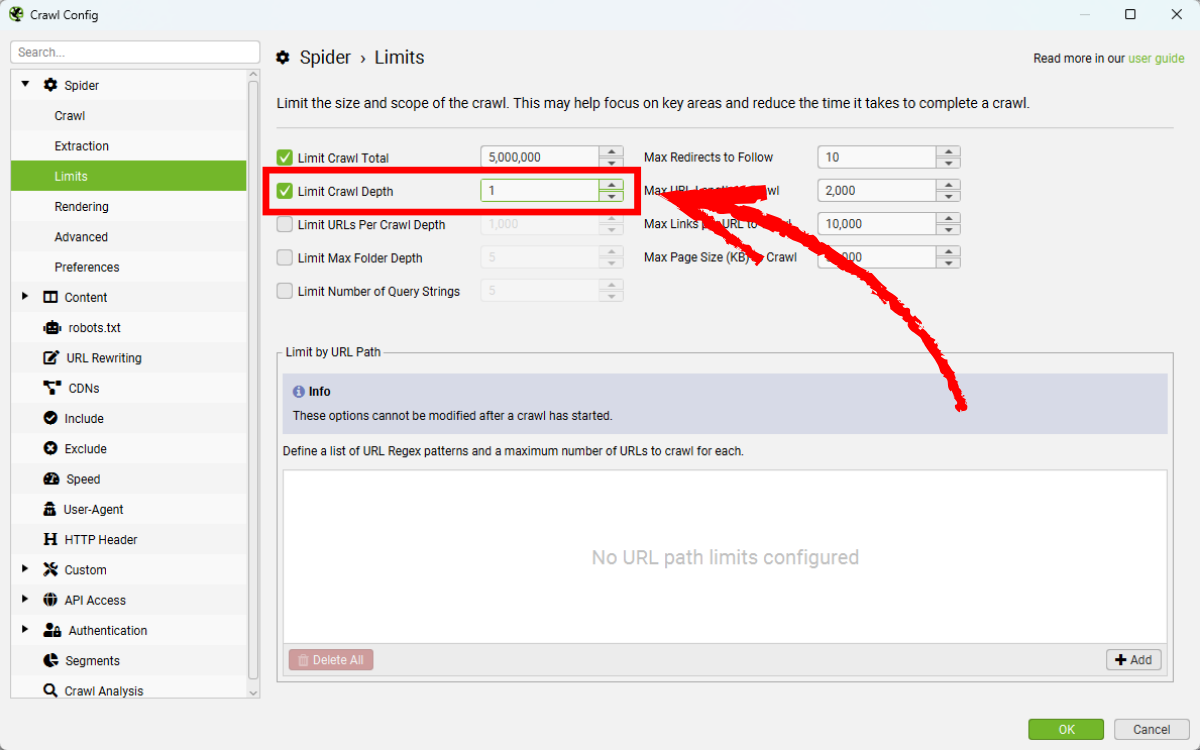
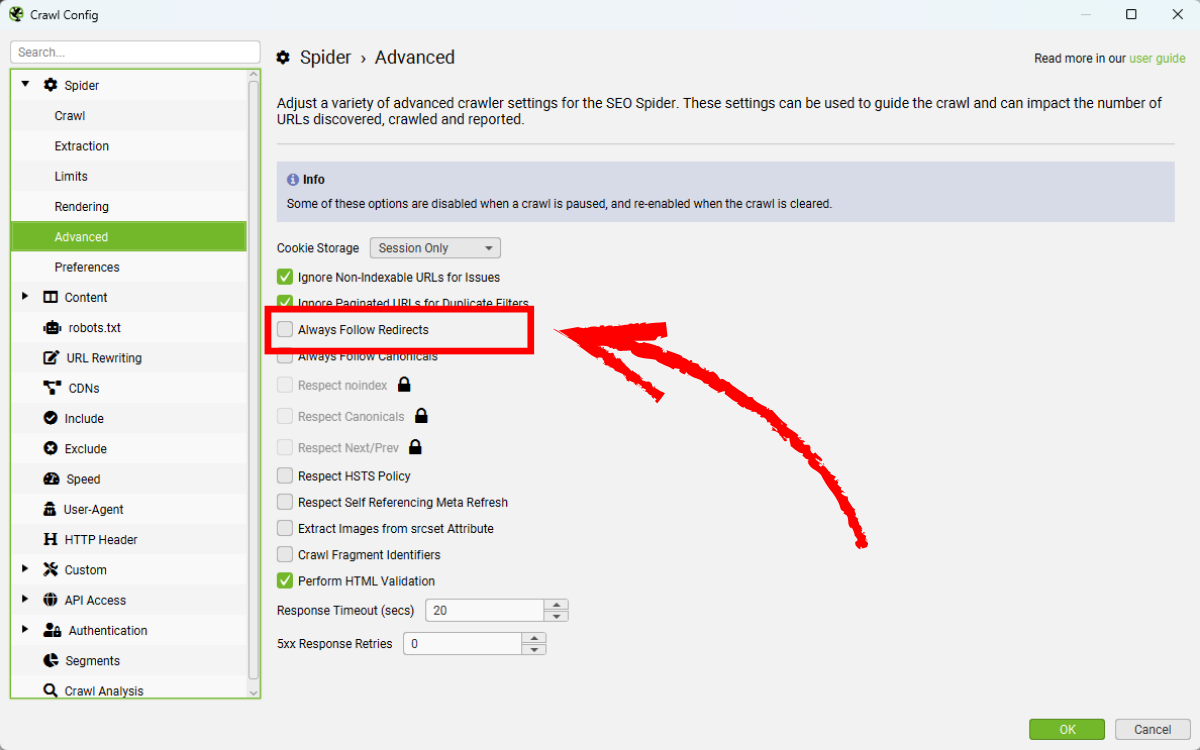
Thiết lập này có nghĩa là khi upload danh sách PDF, công cụ không chỉ crawl file PDF mà còn thu thập cả các liên kết bên trong tệp đó. Nếu outlinks là các liên kết chuyển hướng, bạn hãy bật Always Follow Redirects tại Config > Spider > Advanced để theo dõi đến điểm đích cuối cùng.
1.3. Extract PDF Properties
Bạn có thể xem các thuộc tính của tài liệu PDF bằng cách mở tệp trong Chrome, chọn nút More Actions ở góc trên bên phải và chọn Document Properties.
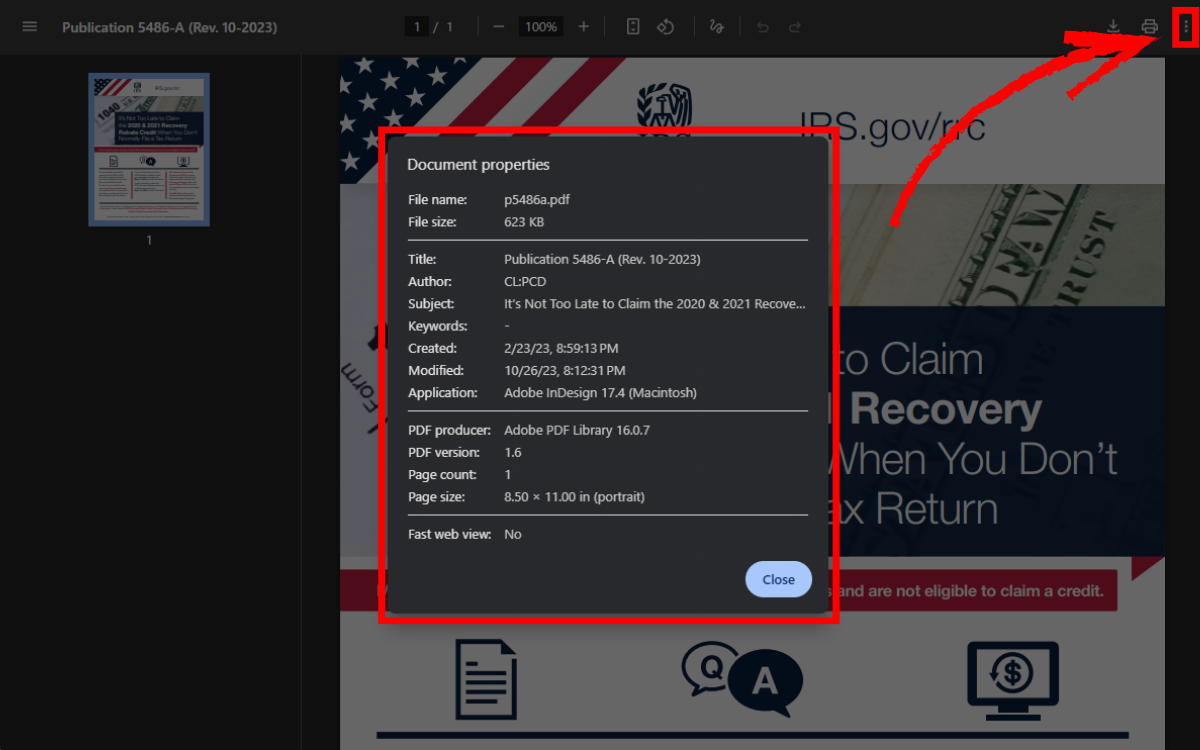
Mặc định, SEO Spider sẽ trích xuất thuộc tính Title và Keywords, sau đó hiển thị tại các cột Title và Meta Keywords trong tab Internal.
Google thường chuyển đổi PDF sang HTML và sử dụng thuộc tính PDF document title làm thẻ title. Trong quá trình audit PDF SEO, các file PDF không có title, title trùng lặp hoặc không mang tính mô tả được xem là lỗi SEO nghiêm trọng, vì có thể gây trùng lặp kết quả tìm kiếm (keyword cannibalization) và làm giảm khả năng hiển thị của tài liệu PDF trên kết quả tìm kiếm. Vì Page Titles ảnh hưởng trực tiếp đến khả năng hiển thị, trong audit PDF SEO bạn cần đặc biệt chú ý đảm bảo PDF Titles phải duy nhất, liên quan và mang tính mô tả tương tự như tiêu đề trang web, đảm bảo PDF Titles phải duy nhất, liên quan và mang tính mô tả tương tự như tiêu đề trang web. Các file PDF có title trùng lặp hoặc quá chung chung thường nên được đánh dấu để chỉnh sửa hoặc cân nhắc noindex nếu không mang lại giá trị SEO rõ ràng.
Google bỏ qua thuộc tính keywords tương tự như thẻ meta keywords, nhưng Bing vẫn parse các thuộc tính này vào bảng HTML để phục vụ xếp hạng (bao gồm title, author, subject, created date). Bạn có thể trích xuất thêm các thuộc tính khác bằng cách bật Extract PDF properties trong Config > Spider > Extraction.
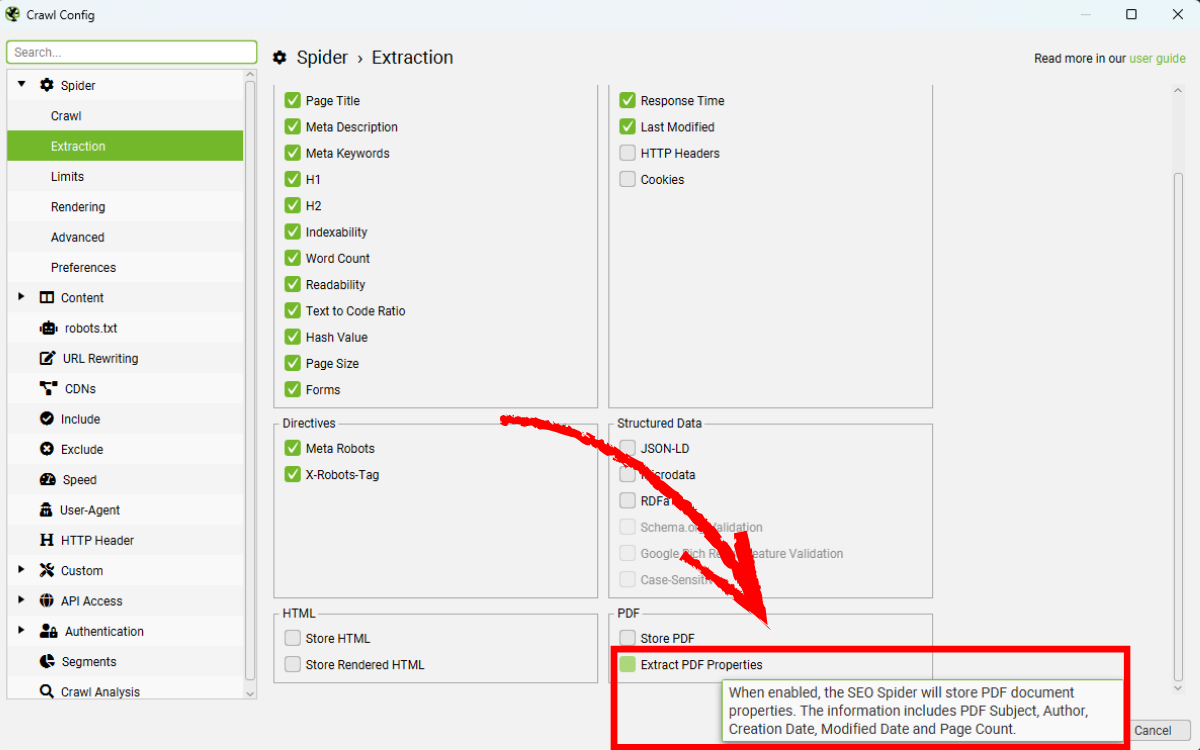
Các thuộc tính bao gồm:
- Subject
- Author
- Creation Date
- Modification Date
- Page Count
Khi kích hoạt, các cột mới sẽ xuất hiện trong tab Internal.
Một số tài liệu SEO cho rằng thuộc tính Subject được các công cụ tìm kiếm dùng làm meta description. Dù chưa có bằng chứng rõ ràng về việc Google sử dụng thuộc tính này, nhưng Bing có thể dùng nội dung của subject property làm meta description vì chúng được parse vào HTML và xử lý như văn bản thông thường.
1.4. Review PDF Content
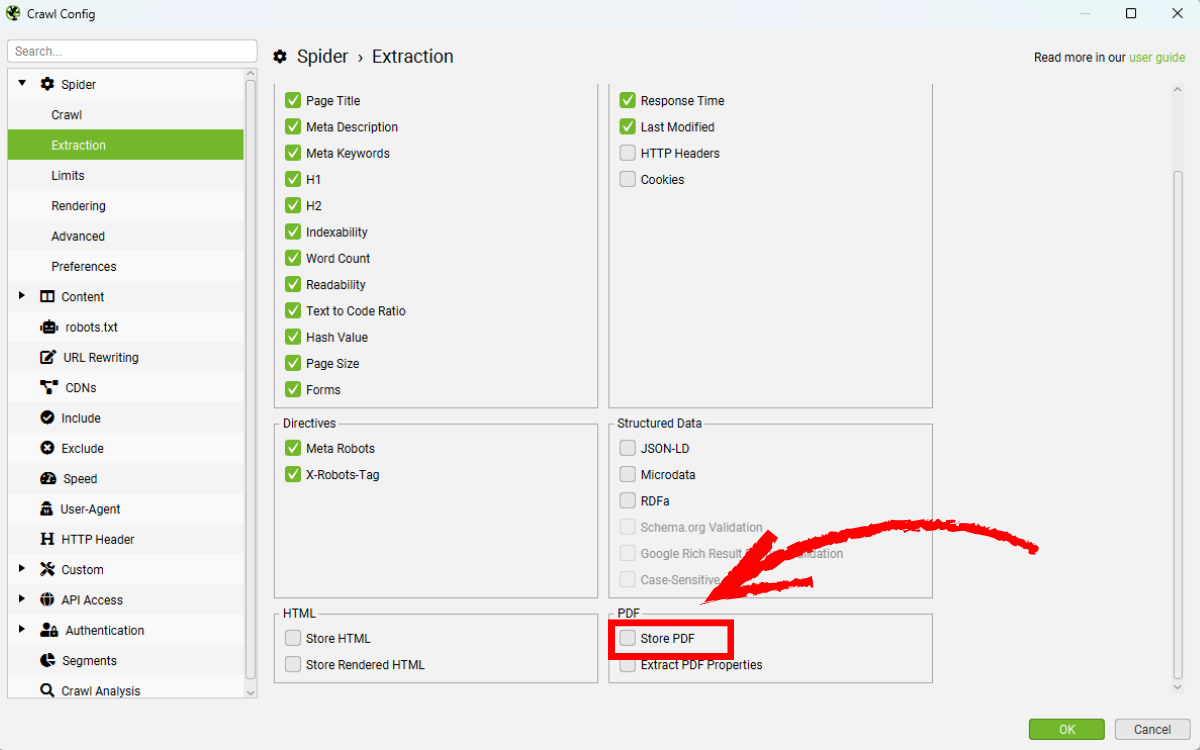
Bạn hãy kích hoạt Store PDF trong Config > Spider > Extraction để công cụ parse và lưu trữ nội dung PDF cùng các chi tiết bổ sung khác.
1.5. Word Count & Readability
Trong audit PDF SEO, các chỉ số word count và readability giúp đánh giá liệu file PDF có đủ giá trị để index hay không. Những tài liệu PDF quá ngắn, thiếu cấu trúc nội dung hoặc có độ dễ đọc thấp thường không mang lại trải nghiệm tốt cho người dùng. Trong audit PDF SEO, các file này nên được đánh dấu để cân nhắc noindex hoặc chuyển đổi sang trang HTML, nhằm tập trung giá trị SEO vào các nội dung mang tính chiến lược hơn.
1.6. Spelling & Grammar
Tương tự như các trang web HTML thông thường, file PDF cũng có thể được kiểm tra lỗi chính tả và ngữ pháp. Để thực hiện, hãy truy cập Config > Content > Spelling & Grammar, sau đó bật cả Spell Check và Grammar Check.
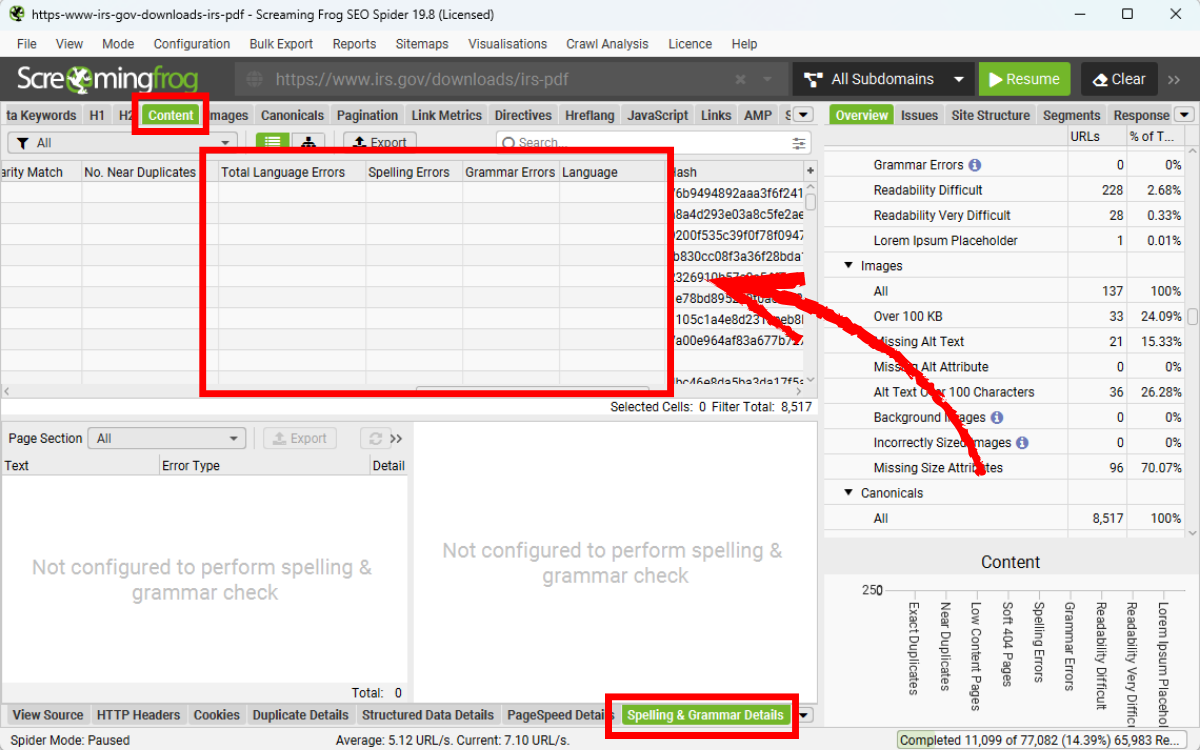
Chi tiết về các lỗi này sẽ hiển thị trong tab Content, tương tự như hướng dẫn trong tutorial Spell & Grammar Check Your Website.
1.7. Custom Search
Vì SEO Spider có thể đọc được nội dung bên trong PDF, bạn có thể áp dụng tính năng Custom Search cho các tệp này. Bạn có thể tìm kiếm bất kỳ đoạn văn bản nào (như tên thương hiệu cũ hoặc số điện thoại) trong cả PDF và trang web.
Hãy đảm bảo đã bật Store PDF trong phần cấu hình Extraction trước khi thiết lập custom search. Truy cập Config > Custom > Search, nhập văn bản cần tìm và chọn Page Text. Bạn có thể xem danh sách các trang chứa đoạn văn bản đó tại tab Custom Search.
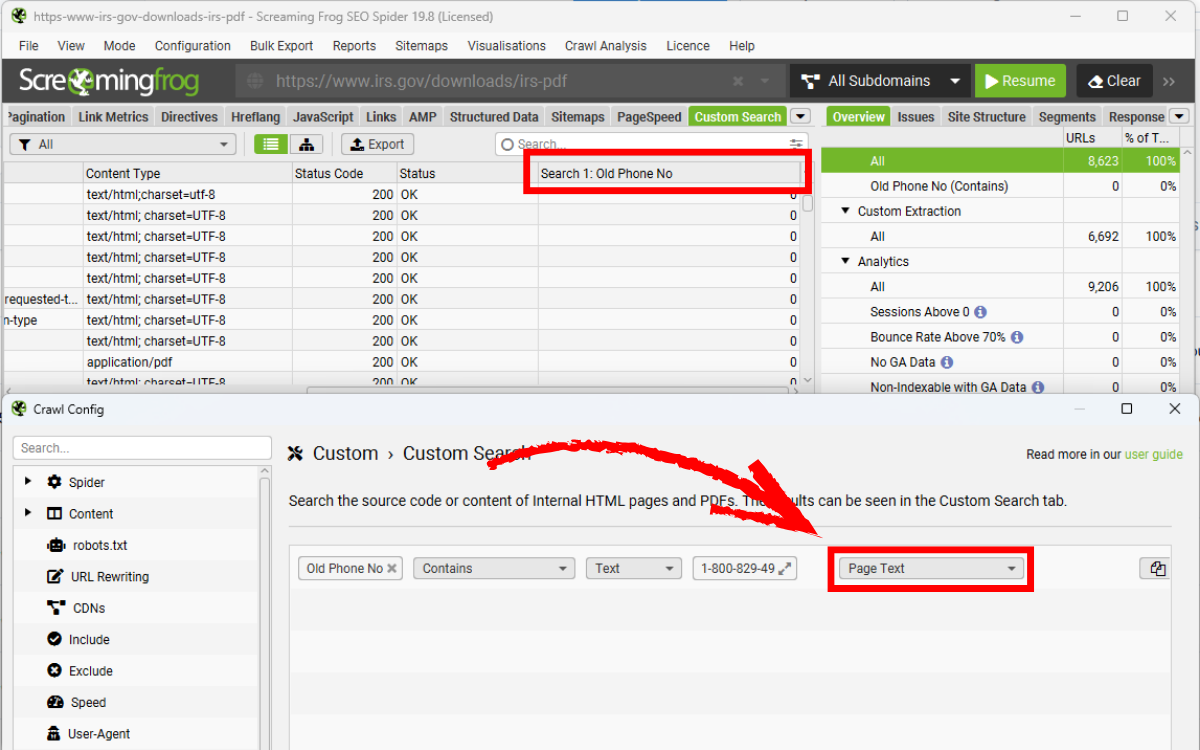
Trong ví dụ trên, file PDF đầu tiên có một lần xuất hiện của số điện thoại.
2. Bulk Save PDFs
Để lưu bản sao của các tệp PDF trong quá trình crawl, bạn hãy bật Store PDF trong mục Extraction, sau đó sử dụng đường dẫn Bulk Export > Web > All PDF Documents.
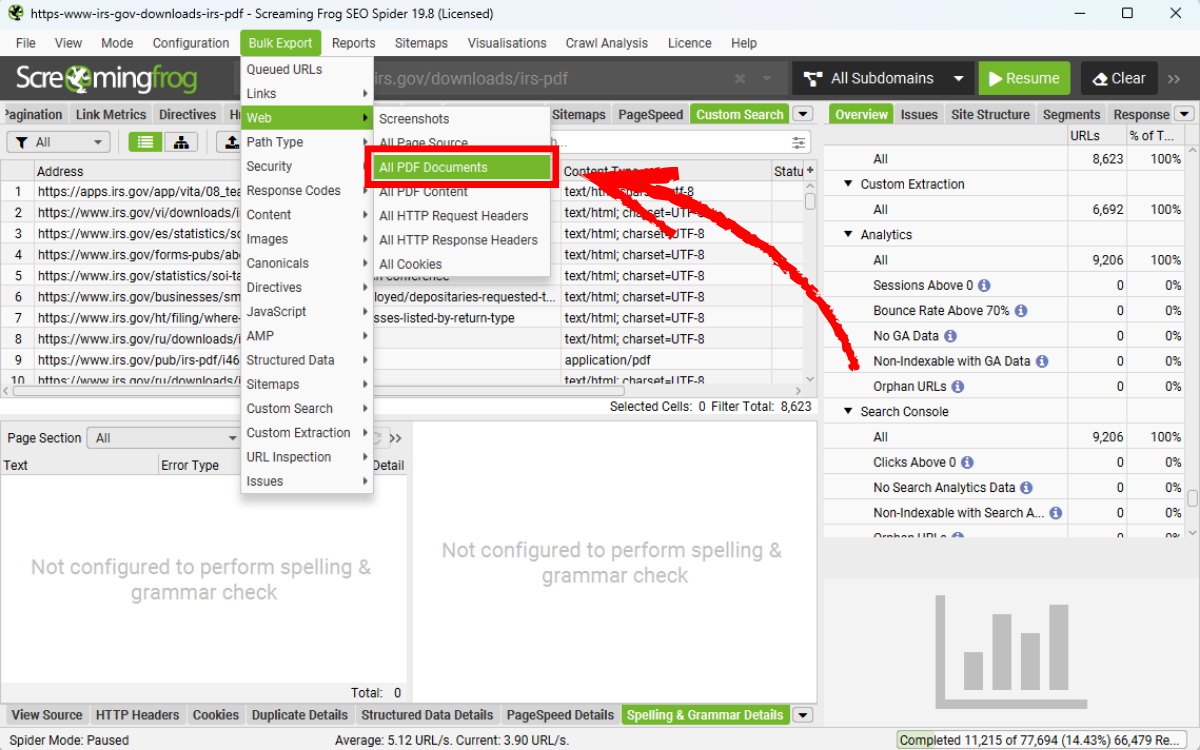
Thao tác này sẽ lưu mọi file PDF đã phát hiện và crawl vào thư mục bạn đã chọn, giúp bạn thuận tiện hơn trong việc rà soát nội dung, đối chiếu phiên bản cũ – mới và phục vụ quá trình audit PDF SEO ở quy mô lớn.
3. Bulk Export PDF Content
SEO Spider hỗ trợ xuất nội dung văn bản thô của PDF dưới dạng tệp .txt. Hãy bật Store PDF trong phần cấu hình Extraction, sau đó chọn Bulk Export > Web > All PDF Content.
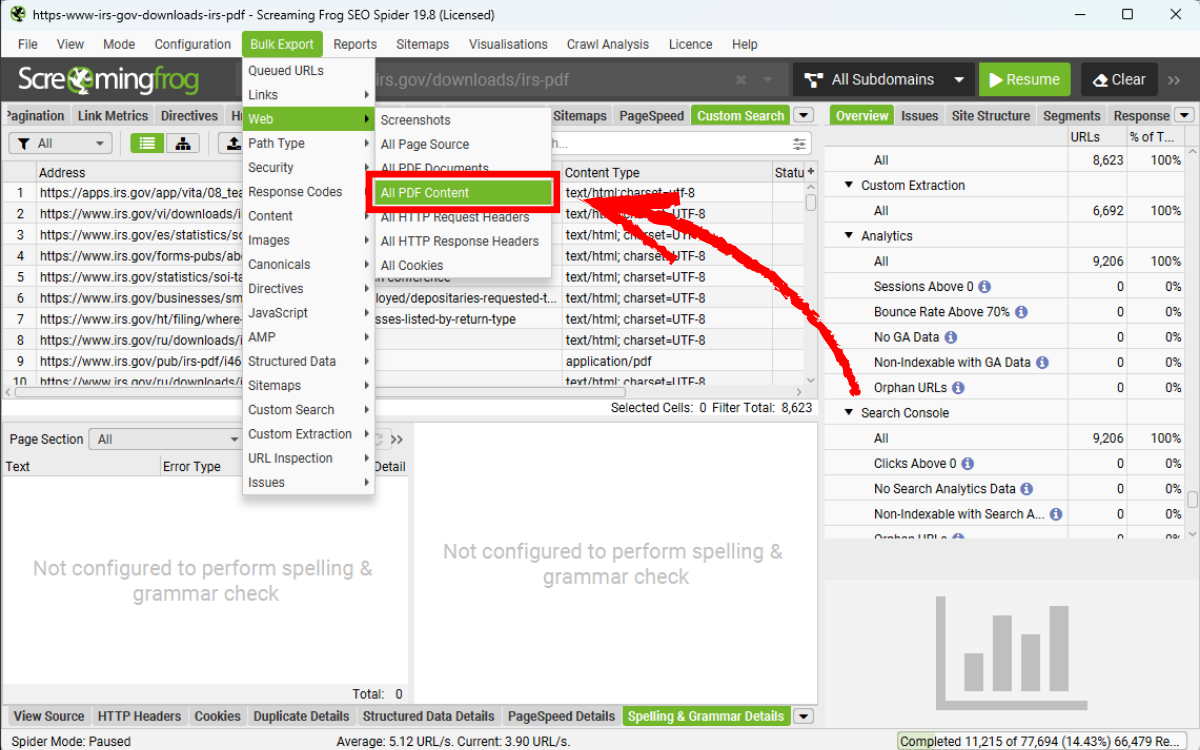
Nội dung của mỗi tệp PDF sẽ được xuất thành một file văn bản riêng biệt tại vị trí bạn đã chọn.
Khi thực hiện audit PDF SEO, bạn nên rà soát nhanh các yếu tố cốt lõi như: file PDF có đang bị index hay không, có tồn tại broken links không; title và metadata có duy nhất và liên quan không; và liệu file PDF đó có rơi vào trạng thái crawled currently not indexed trong Google Search Console hay không. có tồn tại broken links không; title và metadata có duy nhất và liên quan không; nội dung PDF có trùng lặp với trang HTML hay không; và các liên kết nội bộ trỏ tới PDF có thực sự cần thiết trong chiến lược SEO tổng thể hay không.
Thông qua quy trình audit PDF SEO bằng Screaming Frog, bạn có thể đánh giá chính xác vai trò và mức độ ảnh hưởng của từng file PDF đối với hiệu suất SEO tổng thể của website. Dựa trên kết quả audit, bạn nên xác định rõ file PDF nào cần tiếp tục index và tối ưu, file nào nên noindex để tránh gây hại SEO, hoặc trường hợp cần chuyển nội dung PDF sang HTML nhằm cải thiện trải nghiệm người dùng và khả năng hiển thị trên công cụ tìm kiếm. Nhờ quy trình audit PDF SEO, bạn có thể phát hiện sớm các vấn đề tiềm ẩn trong hệ thống tài liệu PDF, từ đó đưa ra quyết định tối ưu phù hợp nhằm bảo vệ và cải thiện hiệu suất SEO tổng thể của website, từ đó đưa ra quyết định tối ưu phù hợp nhằm bảo vệ và cải thiện hiệu suất SEO tổng thể của website. Việc audit PDF định kỳ sẽ giúp website duy trì chất lượng nội dung nhất quán, hạn chế rủi ro SEO và tối ưu trải nghiệm người dùng trong dài hạn. LENART tin rằng hướng dẫn này sẽ giúp bạn khai thác tối đa công cụ, đảm bảo website cung cấp nội dung PDF chất lượng cao và nâng cao hiệu suất SEO tổng thể.









