Crawled – currently not indexed là trạng thái cho thấy Google đã thu thập dữ liệu trang nhưng chưa thêm trang vào index, khiến nội dung của bạn không xuất hiện trên kết quả tìm kiếm. Đây là một trong những vấn đề SEO kỹ thuật phổ biến, ảnh hưởng trực tiếp đến khả năng hiển thị và lưu lượng truy cập tự nhiên của website. Hiểu rõ nguyên nhân gây ra tình trạng này giúp bạn tối ưu nội dung, cải thiện cấu trúc website, tinh chỉnh liên kết nội bộ và xử lý các yếu tố kỹ thuật cản trở Google index trang. Trong bài viết này, Lenart sẽ hướng dẫn bạn cách nhận diện nguyên nhân, áp dụng quy trình khắc phục hiệu quả và cải thiện tỷ lệ index toàn site giúp website được Google đánh giá cao hơn, tăng trưởng thứ hạng ổn định và bền vững.

1. Cung cấp nội dung chất lượng cao
Các vấn đề liên quan đến nội dung thường là nguyên nhân chính dẫn đến thông báo “Crawled – currently not indexed”. Là chủ sở hữu website, bạn nên đảm bảo rằng mỗi trang đều cung cấp nội dung thực sự hữu ích và chất lượng. Hãy xem nội dung hiện tại có đáp ứng đúng nhu cầu của người dùng hay không, và bổ sung thêm thông tin giá trị nếu cần. Google Search Central cũng đưa ra một danh sách câu hỏi giúp bạn tự đánh giá mức độ chất lượng và giá trị của nội dung.
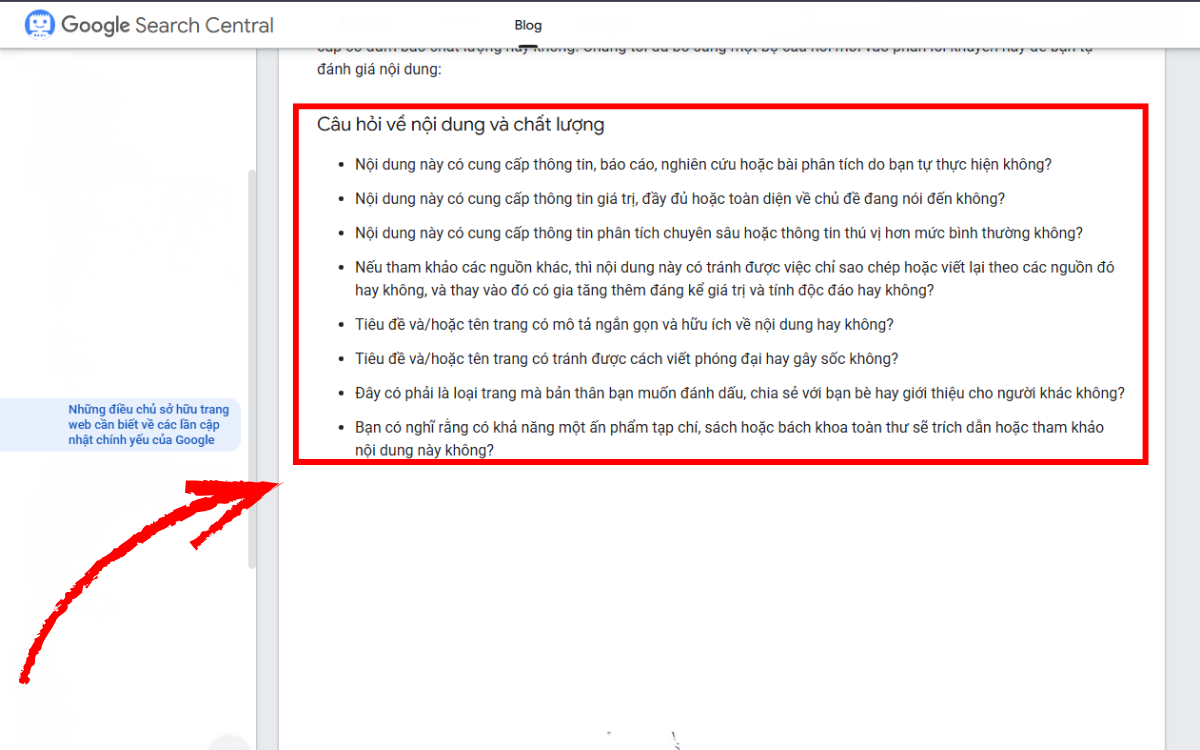
Ngoài ra, bạn có thể tham khảo các mẹo về cách tạo nội dung chất lượng trong Google’s Quality Raters Guidelines. Dù tài liệu này được viết chủ yếu cho đội ngũ đánh giá chất lượng tìm kiếm của Google, các quản trị viên web vẫn có thể dựa vào đó để hiểu rõ hơn cách cải thiện nội dung trên website của mình. Bạn cũng có thể xem thêm bài viết Our Article on the Quality Rater Guidelines để nắm thông tin chi tiết hơn. Một điểm quan trọng khác là việc tối ưu hóa nội dung do người dùng tạo ra trên trang web.
Ví dụ: nếu bạn có một diễn đàn nơi người dùng đặt câu hỏi. Dù có thể sau này sẽ có nhiều câu trả lời hữu ích, nhưng tại thời điểm Google thu thập dữ liệu, câu hỏi đó chưa có phản hồi. Điều này khiến Google dễ đánh giá trang là nội dung chất lượng thấp. Hãy nhớ rằng Google không thể index toàn bộ internet do giới hạn về tài nguyên. Vì vậy, Google buộc phải ưu tiên và loại bỏ những nội dung bị xem là kém chất lượng.
2. Thực hiện kiểm tra thủ công các trang bị ảnh hưởng
Một URL có thể rơi vào trạng thái “Crawled – currently not indexed” nếu trước đây nó từng được index nhưng theo thời gian Google quyết định loại bỏ. Nếu bạn đang tự hỏi vì sao điều này xảy ra, một số lý do phổ biến gồm:
- Trang bị thay thế bởi nội dung chất lượng cao hơn, như Gary Illyes từng chia sẻ trên Twitter.

- Ảnh hưởng từ các bản cập nhật thuật toán, khiến Google đánh giá lại mức độ hữu ích của trang.
- Lỗi từ phía Google, ví dụ như trường hợp Search Engine Land từng bị gỡ khỏi Indexing vì Google nhầm tưởng website bị hack.
Điều quan trọng cần nhớ là: việc một trang đã được index không có nghĩa nó sẽ luôn ở đó. Google có thể thay đổi cách đánh giá nội dung theo thời gian. Trong nhiều trường hợp, nội dung bị gỡ indexing là do thay đổi một phần thông tin chẳng hạn mô tả sản phẩm được chỉnh sửa và phiên bản mới không còn đáp ứng tiêu chuẩn chất lượng của Google. Điều này xảy ra thường xuyên hơn bạn nghĩ.
Hãy kiểm tra lại nội dung của trang, so sánh với các phiên bản trước đó (nếu có), để xác định xem điều gì đã thay đổi và có thể dẫn đến việc bị loại khỏi indexing. Việc theo dõi thường xuyên giúp bạn kịp thời phát hiện vấn đề và cải thiện nội dung khi cần. Để quản lý phạm vi index một cách hiệu quả, bạn có thể sử dụng ZipTie, một nền tảng SEO kỹ thuật chuyên hỗ trợ theo dõi indexing. ZipTie giúp phát hiện độ trễ trong việc indexed và cung cấp báo cáo hàng tuần về số lượng trang bị gỡ indexing, từ đó bạn biết khi nào cần kiểm tra thủ công. Sau khi khắc phục các vấn đề, bạn có thể gửi lại những URL đã được chỉnh sửa lên Google Search Console để Google nhận diện thay đổi nhanh hơn.
3. Chú trọng cấu trúc website và cải thiện liên kết nội bộ
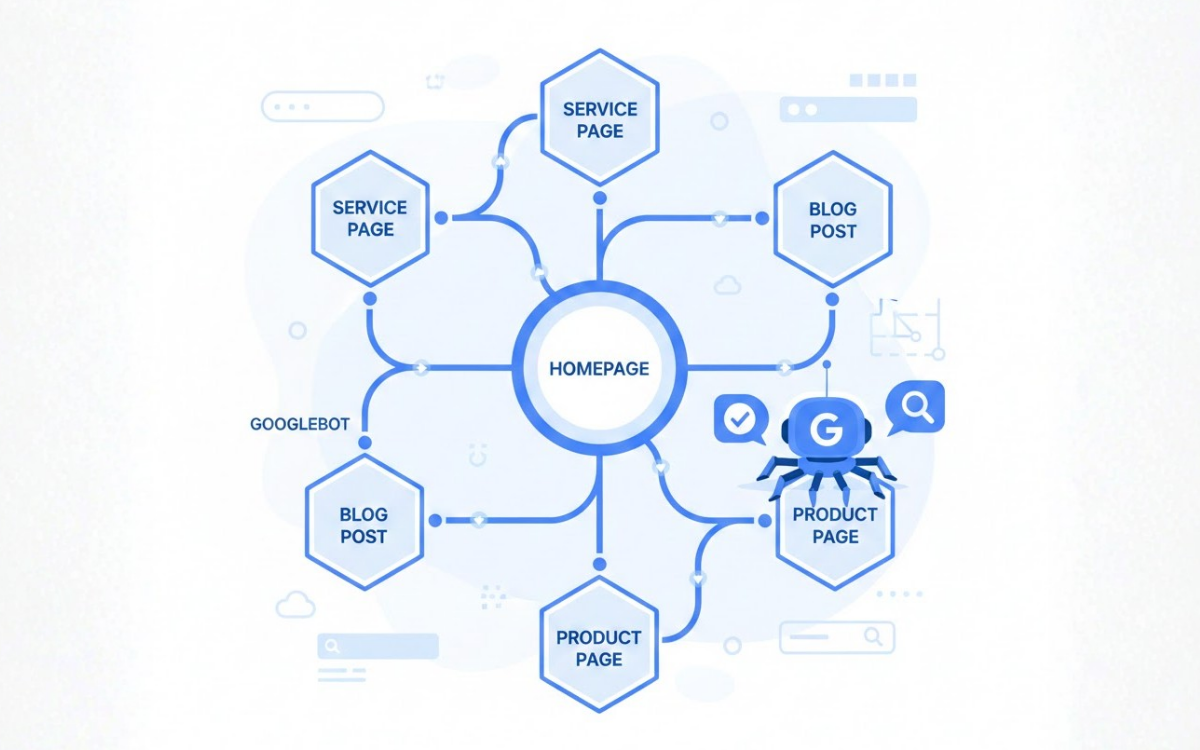
Một lý do khác khiến các trang của bạn rơi vào trạng thái “Crawled – currently not indexed” là cấu trúc website chưa tối ưu. Một website architecture tốt là yếu tố then chốt giúp tăng khả năng trang được index. Nó cho phép bot của công cụ tìm kiếm dễ dàng khám phá nội dung và hiểu rõ mối quan hệ giữa các trang.
Vì vậy, điều quan trọng là bạn cần xây dựng một cấu trúc website hợp lý và đảm bảo rằng mỗi trang bạn muốn Google index đều có liên kết nội bộ trỏ đến. Hãy tưởng tượng bạn có một trang chất lượng cao, nhưng Google chỉ tìm thấy nó thông qua sitemap.
Trong trường hợp đó, Google vẫn có thể truy cập và crawl trang, nhưng vì không có internal link nào trỏ đến, trang sẽ bị đánh giá thấp hơn so với những trang được kết nối chặt chẽ trong website. Việc thiếu tín hiệu ngữ nghĩa và liên kết có thể khiến Google ưu tiên các trang khác và bỏ qua trang này sau khi crawl.
4. Giới hạn nội dung trùng lặp
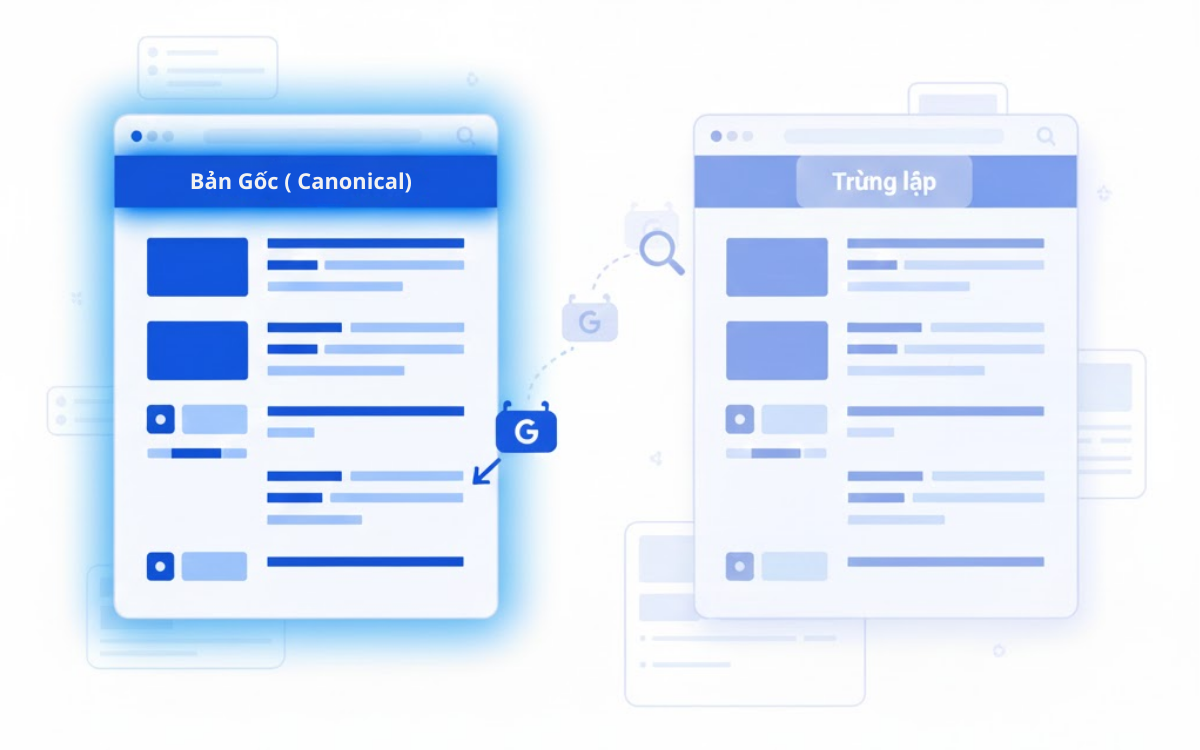
Nội dung trùng lặp là một yếu tố khác có thể khiến Google ngừng indexed các trang của bạn. Vì vậy, bạn cần đảm bảo rằng mỗi trang đều mang tính nguyên bản và khác biệt. Google ưu tiên hiển thị nội dung độc nhất và hữu ích. Khi nhiều trang có nội dung giống hệt hoặc gần giống nhau, Google thường chỉ indexed một phiên bản duy nhất.
Tuy nhiên, trong một số trường hợp, nội dung trùng lặp là điều khó tránh — chẳng hạn như bạn có phiên bản dành cho di động và máy tính bàn. Dù bạn không thể kiểm soát hoàn toàn phiên bản nào sẽ xuất hiện trong kết quả tìm kiếm, bạn vẫn có thể cung cấp tín hiệu rõ ràng cho Google về phiên bản gốc.
Nếu bạn nhận thấy nhiều trang trùng lặp đang được indexed, hãy kiểm tra các yếu tố sau:
- Canonical tags: Những thẻ HTML này báo cho công cụ tìm kiếm biết đâu là phiên bản chính.
- Liên kết nội bộ: Hãy đảm bảo rằng internal links trỏ về phiên bản gốc. Google có thể sử dụng chúng như tín hiệu xác định trang quan trọng.
- XML Sitemap: Chỉ nên đưa phiên bản canonical vào sitemap.
Hãy lưu ý rằng đây chỉ là tín hiệu, không phải quy định bắt buộc, và Google có thể không tuân theo canonical của bạn. Nếu điều đó xảy ra, bạn sẽ thấy trạng thái “Duplicate, Google chose different canonical than user” trong Google Search Console.
Adam Gent, một freelancer SEO, đã chia sẻ một trường hợp thú vị: trang của anh bị đánh dấu “Crawled – currently not indexed” vì Google nghi ngờ đó là nội dung trùng lặp. Chưa rõ lý do tại sao Google chọn trạng thái này thay vì trạng thái dành riêng cho duplicate content — có thể vì Google chưa xác định được tình trạng cuối cùng của trang, hoặc đơn giản là một lỗi báo cáo.
Điều này khiến việc xử lý trở nên khó khăn hơn, bởi “Crawled – currently not indexed” cung cấp ít thông tin hơn so với trạng thái trùng lặp chuyên biệt.
5. Gửi yêu cầu thủ công để Google thu thập lại các URL
Sau khi bạn đã khắc phục toàn bộ các vấn đề ảnh hưởng đến khả năng thu thập dữ liệu, bước tiếp theo là gửi lại trang để Google tiến hành index.
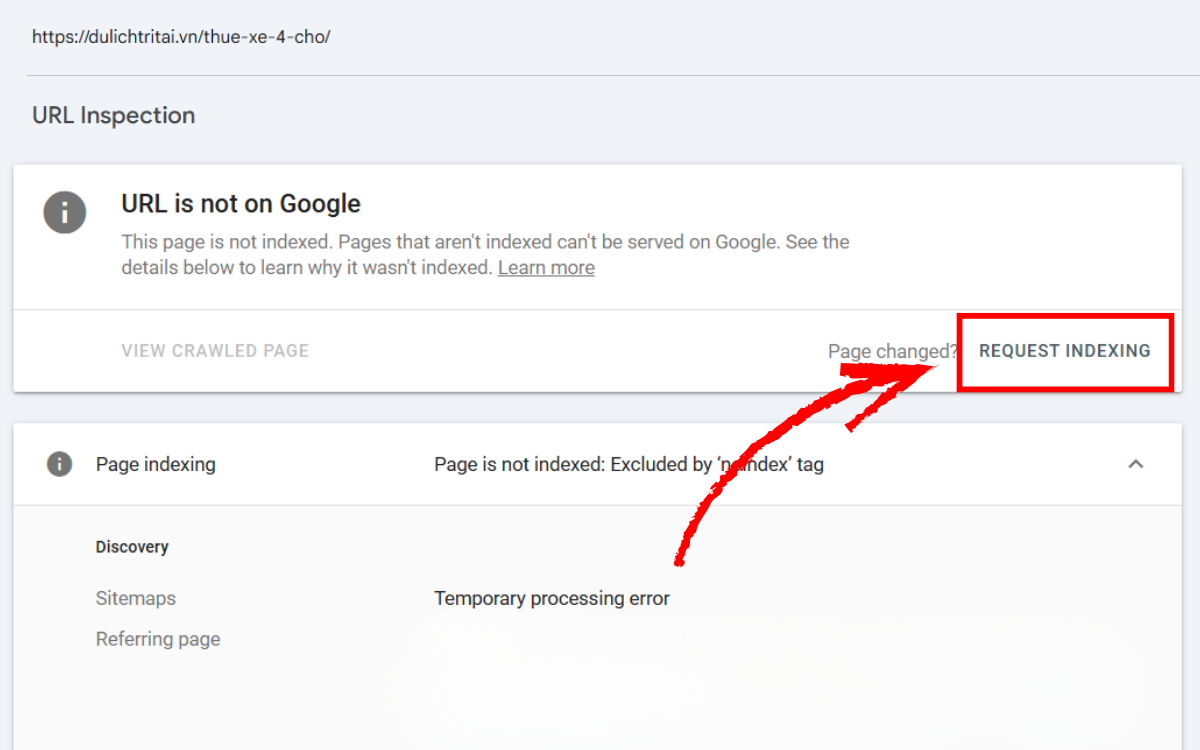
Phương pháp 1: Gửi thủ công qua URL Inspection
Truy cập URL Inspection, nhập URL cần kiểm tra và chọn Request Indexing. Đây là cách nhanh nhất để thông báo cho Google rằng trang của bạn đã sẵn sàng được thu thập lại.
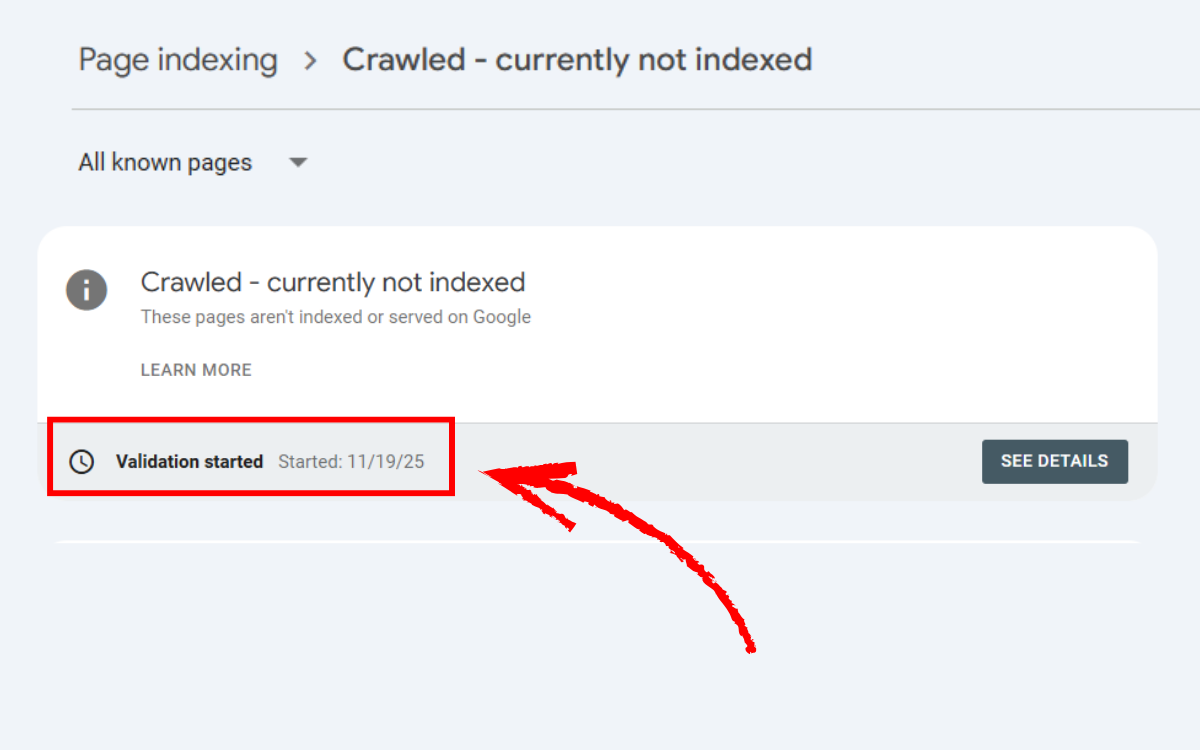
Phương pháp 2: Xử lý hàng loạt qua Indexing → Pages
Đối với các URL nằm trong nhóm “Crawled – Currently Not Indexed”, bạn có thể sử dụng tính năng xác nhận tự động: Đi tới Indexing → Pages, chọn nhóm Crawled – Currently Not Indexed, sau đó chuyển sang All known pages và nhấn Validate Fix. Cách này đặc biệt hữu ích khi bạn có nhiều URL cần Google xem xét lại cùng lúc. Khi Google tiếp nhận yêu cầu, trạng thái validation sẽ được kích hoạt để theo dõi quá trình kiểm tra và index.
6. Sử dụng sitemap.xml tạm thời
Đôi khi, các URL đích của chuyển hướng vẫn xuất hiện trong báo cáo “Crawled – Currently Not Indexed”. Đây không phải là dấu hiệu của lỗi chuyển hướng, mà chủ yếu liên quan đến tần suất Google thu thập dữ liệu (crawl frequency) trên website của bạn. Google có thể đã crawl các URL đích này nhưng chưa đưa chúng vào index, dẫn đến việc chúng tạm thời không xuất hiện trong indexing tìm kiếm.
Một giải pháp hiệu quả là tạo một sitemap.xml tạm thời để thúc đẩy quá trình tái-crawl. Trước tiên, hãy trích xuất tất cả URL trong báo cáo “Crawled – Currently Not Indexed” và đối chiếu chúng với danh sách chuyển hướng đã thiết lập. Việc này có thể thực hiện bằng Excel hoặc Google Sheets để đảm bảo không bỏ sót URL nào.

Sau khi đã lọc và xác định danh sách chính xác, hãy tạo một sitemap mới bằng các công cụ như XML Sitemaps, sau đó tải sitemap này lên Google Search Console. Đây là một cách gửi tín hiệu mạnh mẽ giúp Google ưu tiên thu thập và index lại những URL đang bị trì hoãn.
7. So Sánh Crawled – Currently Not Indexed và “Discovered – Currently Not Indexed
Cả hai trạng thái đều cho thấy trang chưa được indexed, nhưng chúng khác nhau ở cách Google tương tác với URL. Với “Crawled – Currently Not Indexed”, Google đã truy cập và thu thập dữ liệu trang. Ngược lại, với “Discovered – Currently Not Indexed”, Google mới chỉ biết đến URL nhưng chưa crawl trang vì một lý do nào đó.
Sự khác biệt này rất quan trọng để bạn xác định đúng nguyên nhân và chọn hướng xử lý phù hợp từ việc rà soát cấu trúc website, đánh giá chất lượng nội dung, cho đến kiểm tra ngân sách crawl của Google. Nếu cần tìm hiểu sâu hơn, bạn có thể tham khảo bài viết How To Fix “Discovered – Currently Not Indexed” in Google Search Console.
| Trạng thái | Trang được Google phát hiện | Trang được Google truy cập | Trang được indexed |
| “Crawled – Currently Not Indexed” | Yes | Yes | No |
| “Discovered – Currently Not Indexed” | Yes | No | No |
Một số nguyên nhân dẫn đến hai trạng thái này có thể giống nhau, chẳng hạn như nội dung chất lượng thấp hoặc cấu trúc liên kết nội bộ chưa tối ưu. Tuy nhiên, khi gặp trạng thái “Discovered – Currently Not Indexed”, bạn cần xem xét sâu hơn lý do Google không thể hoặc không muốn truy cập trang. Điều này có thể phản ánh các vấn đề lớn hơn, như chất lượng tổng thể của website, giới hạn ngân sách crawl, hoặc máy chủ quá tải khiến Googlebot không thể thu thập dữ liệu.
8. Những câu hỏi thường gặp
Khi quản lý website, bạn có thể gặp phải tình trạng các trang đã được Google thu thập dữ liệu nhưng không được đưa vào indexing tìm kiếm. Điều này ảnh hưởng đến khả năng hiển thị của trang trên công cụ tìm kiếm và gây ra nhiều thắc mắc về nguyên nhân cũng như cách khắc phục. Phần FAQ dưới đây sẽ giúp bạn hiểu rõ hơn về hiện tượng “Crawled but Not Indexed” và cách xử lý hiệu quả.
8.1. “Crawled but Not Indexed” nghĩa là gì?
Thuật ngữ này có nghĩa là Google đã tìm thấy và thu thập dữ liệu trang của bạn, nhưng không đưa trang đó vào indexing tìm kiếm. Do đó, trang sẽ không hiển thị trong kết quả tìm kiếm.
8.2. Vì sao một số trang đã được thu thập dữ liệu (crawled) nhưng không được indexed?
Trang có thể không được indexed do nhiều nguyên nhân, như chất lượng nội dung thấp, nội dung trùng lặp hoặc thiếu liên kết nội bộ, cùng các yếu tố khác.
8.3.Làm sao tôi kiểm tra xem trang của mình có bị crawled but not indexed không?
Bạn có thể sử dụng báo cáo “Coverage” trong Google Search Console hoặc công cụ URL Inspection để kiểm tra chi tiết từng URL.
8.4. Việc có các trang đã crawled nhưng không index gây ảnh hưởng gì?
Điều này có thể làm giảm hiệu quả SEO, báo hiệu cho Google rằng trang thiếu giá trị hoặc không đủ liên quan. Khi trang không được index, nó sẽ không nhận lưu lượng truy cập từ tìm kiếm.
8.5. Làm sao khắc phục các trang đã crawled nhưng chưa được index?
Bạn nên đánh giá lại chất lượng nội dung, kiểm tra cập nhật, tối ưu cấu trúc và liên kết nội bộ, sau đó gửi yêu cầu re-indexing lại.
8.6. Những phương pháp tốt nhất để cải thiện khả năng được index của trang web là gì?
Tạo nội dung độc đáo, duy trì cấu trúc trang rõ ràng, sử dụng liên kết nội bộ hiệu quả, và xử lý các vấn đề liên quan đến nội dung trùng lặp.
8.7. Trang web có thể được crawl lại và index sau này không?
Có thể. Nếu bạn cải thiện nội dung và gửi lại yêu cầu qua URL Inspection Tool, trang hoàn toàn có thể được indexed lại.
8.8. Tốc độ tải trang ảnh hưởng thế nào đến việc index?
Tốc độ tải nhanh giúp cải thiện trải nghiệm người dùng và có thể gián tiếp hỗ trợ quá trình index. Tuy nhiên, chất lượng nội dung vẫn là yếu tố quan trọng nhất.
8.9. Vấn đề nội dung trùng lặp ảnh hưởng đến việc index ra sao?
Nội dung trùng lặp khiến Google chỉ ưu tiên index một phiên bản. Bạn có thể dùng thẻ canonical để chỉ định trang gốc và hạn chế tình trạng này.
8.10. Có công cụ nào hỗ trợ hiểu rõ vấn đề crawl và index không?
Có, Google Search Console và ZipTie.dev là những công cụ cung cấp dữ liệu chi tiết về crawl và index.
8.11. Thin content là gì và liên quan gì đến việc index?
Thin content là trang có nội dung mỏng, thiếu giá trị, khiến khả năng được index giảm đi đáng kể.
8.12. Làm sao tăng khả năng được index cho các trang động (dynamic pages)?
Hãy đảm bảo nội dung chất lượng, kết nối liên kết nội bộ hiệu quả, tối ưu cấu trúc URL, đồng thời hạn chế tham số URL phức tạp.
8.13. Mối quan hệ giữa việc gửi sitemap và việc index là gì?
Sitemap giúp Google phát hiện trang nhanh hơn, nhưng không đảm bảo rằng trang sẽ được index. Sitemap là công cụ hỗ trợ khám phá nội dung, không phải là quyết định cuối cùng.
8.14.Các thay đổi trên trang có thể ảnh hưởng đến trạng thái index không?
Có. Các cải tiến đáng kể trên trang có thể khiến Google xem xét lại và thay đổi trạng thái index, dù không có gì đảm bảo chắc chắn.
9. Lời khuyên cải thiện tình trạng Crawled – Currently Not Indexed
Trạng thái “Crawled – Currently Not Indexed” thường liên quan đến chất lượng trang, nhưng thực tế nó cũng có thể phản ánh nhiều vấn đề khác như kiến trúc website gây nhầm lẫn hoặc nội dung bị trùng lặp. Dưới đây là những điểm quan trọng giúp bạn xử lý hiệu quả tình trạng “Crawled – Currently Not Indexed”:
- Bổ sung nội dung độc đáo và có giá trị cho các trang của bạn. Sau khi hoàn tất, hãy gửi những URL này lên Google Search Console để Google nhanh chóng nhận biết sự thay đổi;
- Kiểm tra lại cấu trúc website và đảm bảo có liên kết nội bộ dẫn đến những trang quan trọng;
- Xác định rõ những trang nào nên được indexed, những trang nào không để giúp Google ưu tiên đánh indexing cho những URL giá trị nhất;
- Áp dụng sitemap.xml tạm thời (đặc biệt hữu ích để giải quyết tình trạng URL mục tiêu từ các chuyển hướng 301 đã được Google indexed nhưng chưa xuất hiện trong indexing chính thức).
Nếu bạn cần hỗ trợ xử lý trạng thái “Crawled – Currently Not Indexed” trên website, dịch vụ SEO kỹ thuật của chúng tôi là lựa chọn phù hợp để đồng hành cùng bạn.
Qua bài viết này, bạn đã hiểu rõ hơn về trạng thái Crawled – Currently Not Indexed và những bước xử lý hiệu quả để cải thiện khả năng index trên Google. LENART tin rằng khi áp dụng đúng hướng dẫn này, bạn sẽ nâng cao chất lượng trang web, tăng cơ hội được Google index và cải thiện thứ hạng bền vững. LENART SEO luôn đồng hành cùng bạn trên hành trình phát triển SEO kỹ thuật chuyên sâu, mang lại hiệu quả lâu dài cho website của bạn.