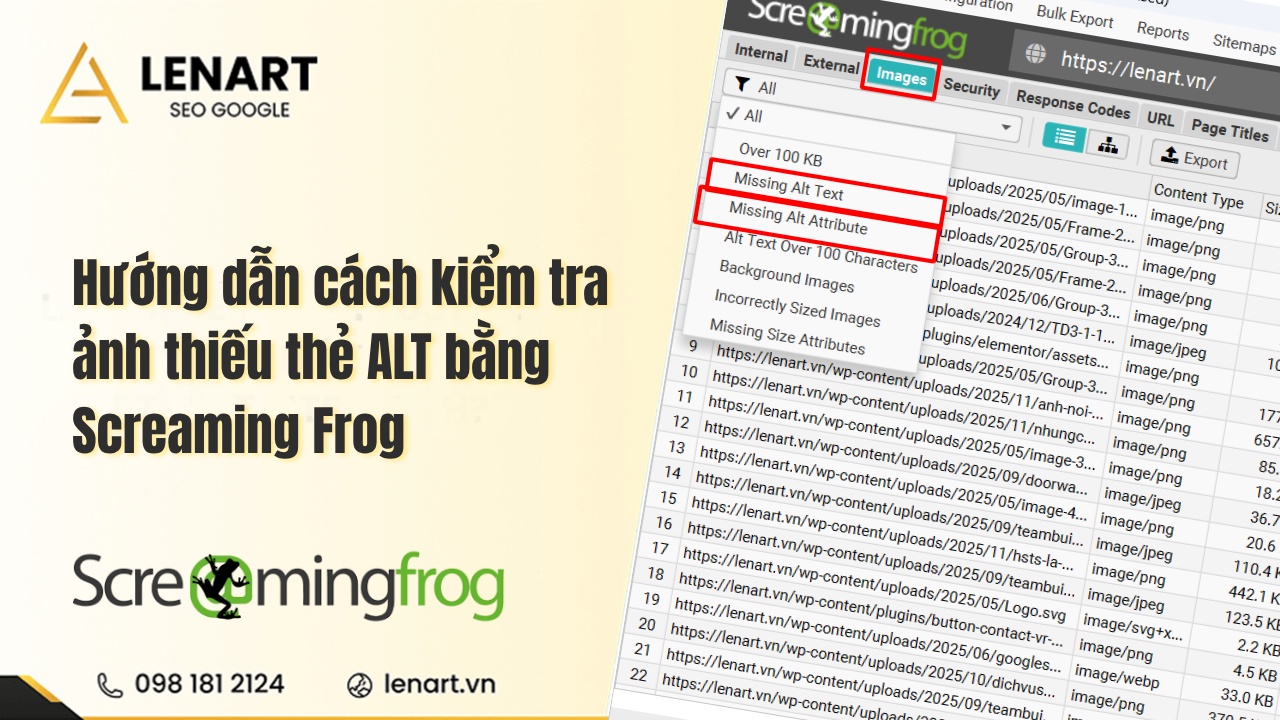
Orphan pages, hay còn gọi là “trang mồ côi”, là những trang tồn tại trên website nhưng không có bất kỳ liên kết nội bộ nào dẫn đến. Chúng có thể là bài viết cũ, sản phẩm hết hàng, trang tạm thời hoặc do CMS sinh ra URL thừa. Việc để các orphan pages tồn tại gây ra nhiều vấn đề khiến người dùng khó tiếp cận thông tin quan trọng, công cụ tìm kiếm khó crawl và index, dẫn tới giảm PageRank, lãng phí crawl budget và làm giảm hiệu quả SEO tổng thể.
Hãy để Công Ty Dịch Vụ SEO Tổng Thể LENART hướng dẫn cách dùng Screaming Frog SEO Spider để phát hiện, phân loại và xử lý orphan pages từ mọi nguồn, bao gồm XML Sitemap, Google Analytics và Google Search Console. Quy trình này giúp doanh nghiệp cải thiện thứ hạng trên Google, tối ưu Internal Link và củng cố Topical Authority, đồng thời quản trị website một cách chuyên nghiệp và hiệu quả.
Hiểu Rõ Orphan Pages Để Tối Ưu Hóa Cấu Trúc Website
Orphan Pages là những trang bị cô lập do thiếu đường dẫn nội bộ từ bất kỳ trang nào khác trên website. Mặc dù công cụ tìm kiếm có thể lập chỉ mục các URL này qua Sitemap hoặc External Link, sự thiếu hụt liên kết nội bộ khiến chúng không nhận được PageRank, làm giảm khả năng xếp hạng và ảnh hưởng tiêu cực đến hiệu suất SEO tổng thể.
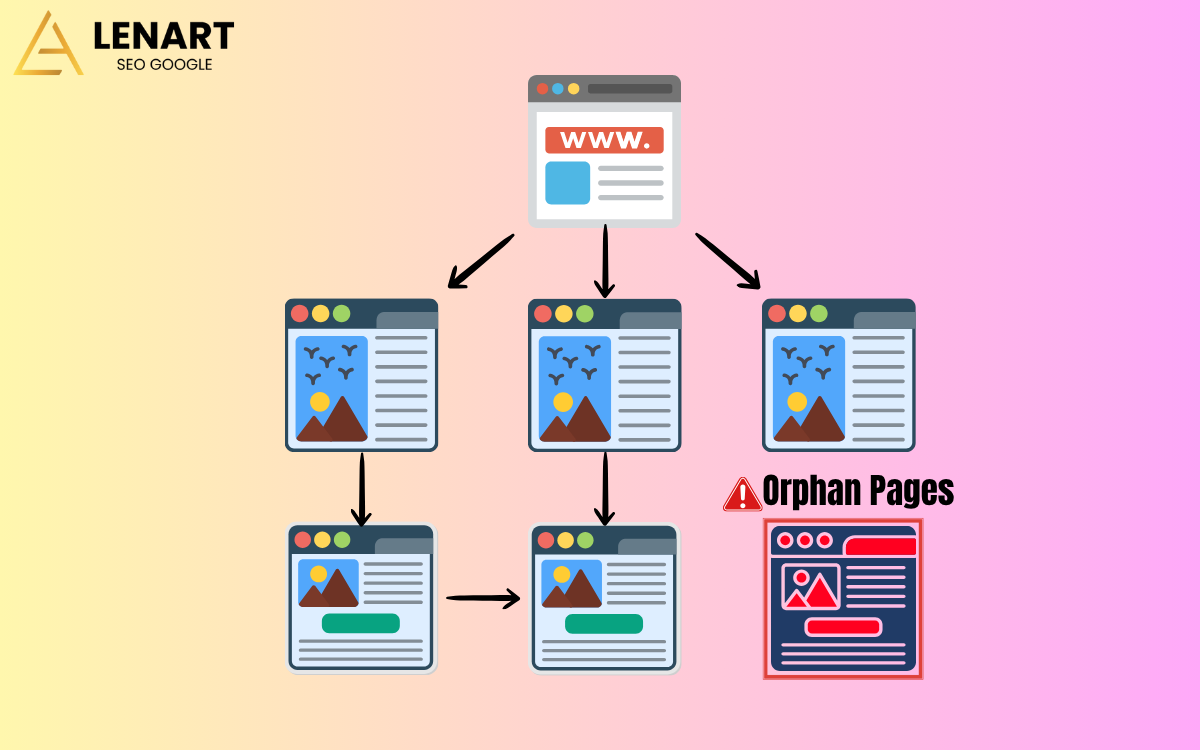
Nguyên nhân phát sinh Orphan Pages
Orphan pages có thể xuất hiện do nhiều lý do:
- Bài viết hoặc sản phẩm cũ chưa được unlink: Trang bài viết lỗi thời hoặc không còn phù hợp nhưng vẫn public.
- CMS tạo URL thừa: Một số template hoặc plugin tự động sinh các URL phụ không được liên kết.
- Sitemap lỗi hoặc chưa cập nhật: Sitemap có các URL không tồn tại trên website hoặc bỏ qua các trang quan trọng.
- Sản phẩm hết hàng nhưng URL vẫn tồn tại: Thường gặp ở website thương mại điện tử, các trang product detail không được Internal Link sang sản phẩm thay thế.
- Page thử nghiệm hoặc tạm thời: Các landing page, test page không được gỡ hoặc Internal Link.
Hiểu rõ nguyên nhân giúp xác định giải pháp xử lý phù hợp, từ re-link các trang quan trọng, redirect URL cũ, đến xóa hoặc noindex các trang không cần thiết.
Tại sao cần tìm Orphan Pages
Việc phát hiện và xử lý các trang mồ côi là bước Technical SEO thiết yếu để tối ưu hóa cấu trúc website, cải thiện Crawl Budget hiệu quả hơn, tăng lượng traffic tự nhiên và nâng cao trải nghiệm người dùng một cách toàn diện.
- Đảm bảo hiệu quả SEO tổng thể: Các trang quan trọng được Internal Link đầy đủ sẽ nhận PageRank và cải thiện thứ hạng.
- Tối ưu crawl budget: Bot tìm kiếm chỉ tập trung quét các trang có giá trị, giúp index nhanh hơn.
- Tăng traffic tự nhiên: Trang được Internal Link tốt sẽ dễ dàng xuất hiện trên SERPs, kéo traffic về website.
- Cải thiện trải nghiệm người dùng: Người dùng dễ tiếp cận nội dung quan trọng, giảm tỷ lệ bounce và tăng engagement.
- Quản trị website chuyên nghiệp: Phát hiện và xử lý orphan pages giúp hệ thống website luôn sạch sẽ, nội dung đồng bộ và dễ bảo trì.
Vai trò của Screaming Frog trong việc phát hiện Orphan Pages
Screaming Frog SEO Spider là công cụ mạnh mẽ để:
- Crawl toàn bộ website, bao gồm Internal Links và URL từ sitemap.
- Kết hợp dữ liệu từ Google Analytics và Google Search Console để phát hiện các trang nhận traffic nhưng không có Internal Link.
- Phân loại các orphan pages theo nguồn (Sitemap, GA, GSC), trạng thái HTTP, crawl depth và các chỉ số SEO quan trọng khác.
- Xuất data chi tiết, tạo danh sách các action cần xử lý cho team Dev và Content.
Sử dụng công cụ này giúp Lenart.vn thực hiện audit orphan pages định kỳ, tối ưu Technical SEO và nâng cao Topical Authority một cách chuyên nghiệp.
Chuẩn bị công cụ và quyền truy cập
Để phát hiện toàn bộ orphan pages trên website, Screaming Frog SEO Spider là công cụ không thể thiếu trong Technical SEO. Để khai thác tối đa sức mạnh của nó, đặc biệt là việc tích hợp API với Google Analytics (GA) và Google Search Console (GSC), bạn cần sử dụng phiên bản có bản quyền (License). Lưu ý rằng phiên bản miễn phí (Lite) bị giới hạn ở 500 URL và không hỗ trợ kết nối API.
- Chức năng chính: Crawl website, phát hiện orphan pages, kiểm tra trạng thái HTTP, phân tích Internal Link, trích xuất dữ liệu SEO kỹ thuật (title, meta description, h1, alt text…).
- Tích hợp API: License cho phép kết nối GA và GSC để phát hiện orphan pages.
Trước khi khởi động quá trình thu thập dữ liệu (crawl), việc kiểm tra kỹ lưỡng các điều kiện tiên quyết là bắt buộc để đảm bảo dữ liệu đầu ra chính xác và toàn diện. Đây là Checklist chuẩn bị cần có:
- Kích hoạt License: Xác nhận Screaming Frog license đã được kích hoạt đầy đủ để sử dụng các tính năng API.
- Thiết lập API Hoàn Chỉnh: Đảm bảo Google Analytics (GA) và Google Search Console (GSC) đã được kết nối và cấp quyền truy cập dữ liệu đầy đủ.
- Tối ưu Sitemap: Kiểm tra lại XML Sitemap đã được cập nhật, đồng thời xác nhận tệp robots.txt không chặn việc crawl sitemap.
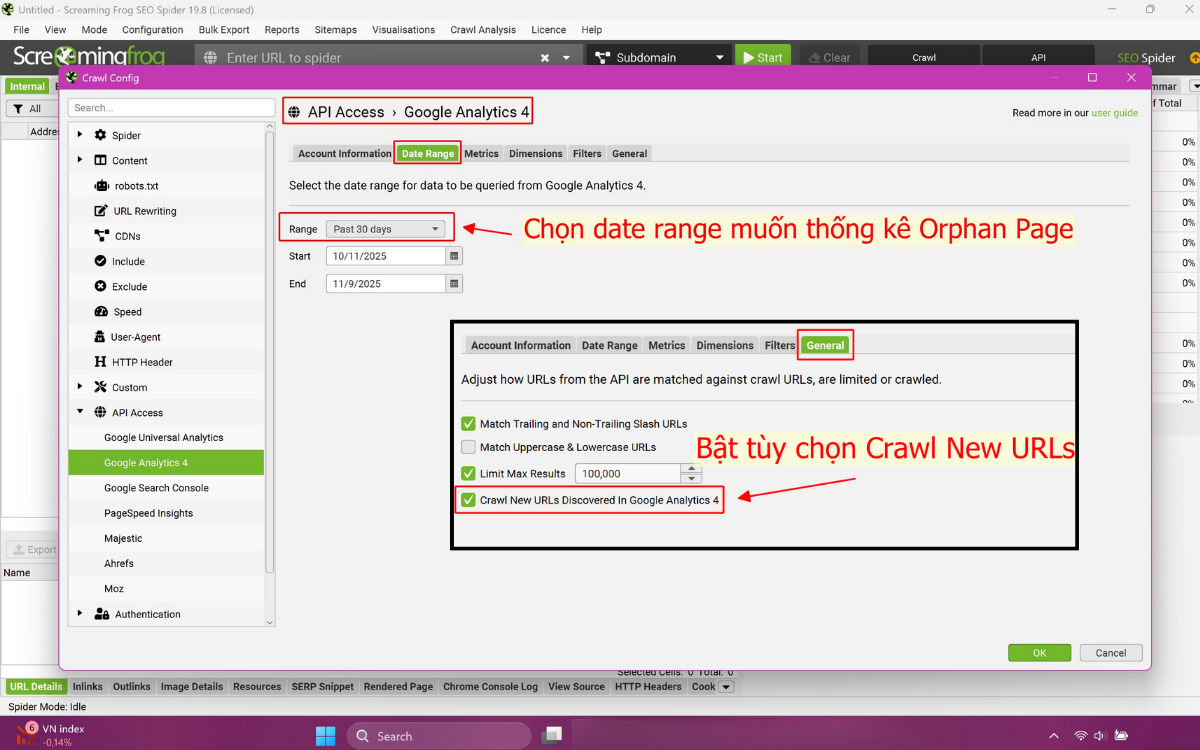
- Cấu hình Chính xác: Lựa chọn Segment GA đúng (thường là Organic Traffic) và bật các tùy chọn crawl new URLs từ cả GA và GSC.
- Chuẩn bị Lưu Trữ: Thiết lập sẵn sàng vị trí lưu trữ dữ liệu xuất (export) ở định dạng CSV/Excel/Sheets để phục vụ cho phân tích sau crawl (post-crawl analysis).
Hoàn tất bước chuẩn bị này, cùng Lenart.vn bắt đầu quá trình crawl toàn diện. Công cụ sẽ thu thập dữ liệu về tất cả các URL hiện có, bao gồm cả những Orphan Pages được phát hiện thông qua Internal Links, Sitemap, GA và GSC, đảm bảo độ chính xác cao nhất để phân loại và xử lý triệt để.
Các Bước Crawl và Phân Loại Orphan Pages Bằng Screaming Frog
Việc crawl và phân loại orphan pages không chỉ giúp phát hiện các URL mồ côi mà còn tối ưu SEO kỹ thuật, PageRank, crawl budget, đồng thời cải thiện trải nghiệm người dùng. Dưới đây là 9 bước chi tiết được tổng hợp từ SEO Lenart:
Bước 1: Crawl Linked XML Sitemaps
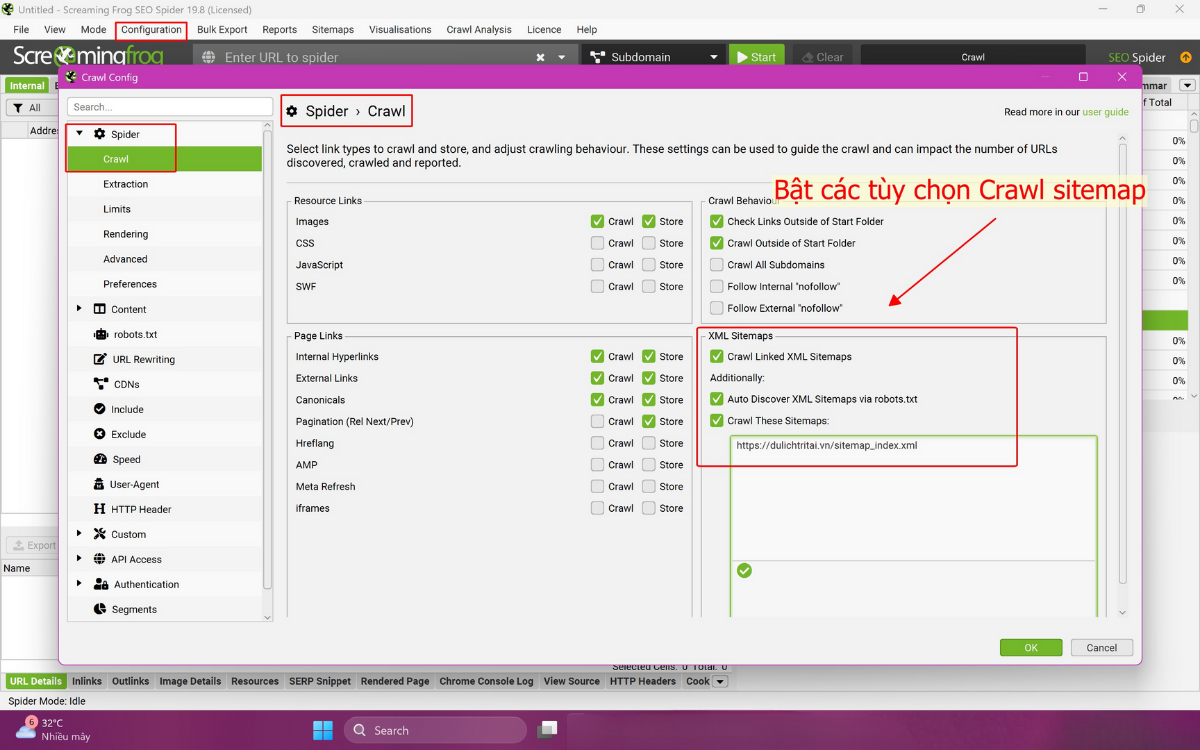
Mục tiêu là tìm kiếm các Orphan Pages mà Google có thể lập chỉ mục nhờ Sitemap, nhưng lại không có Internal Link từ bất kỳ trang nào khác. Tiến hành cấu hình công cụ Screaming Frog để sử dụng dữ liệu từ Sitemap trong quá trình crawl:
- Truy cập Cấu Hình Spider: Vào mục Configuration > Spider > Crawl.
- Kích hoạt Crawl Sitemap: Bật tùy chọn “Crawl Linked XML Sitemap”.
- Nhập/Phát hiện Sitemap: Nhập URL Sitemap cụ thể vào công cụ, hoặc bật chức năng tự động phát hiện (auto-discover) Sitemap thông qua tệp robots.txt.
Bước 2: Kết nối Google Analytics
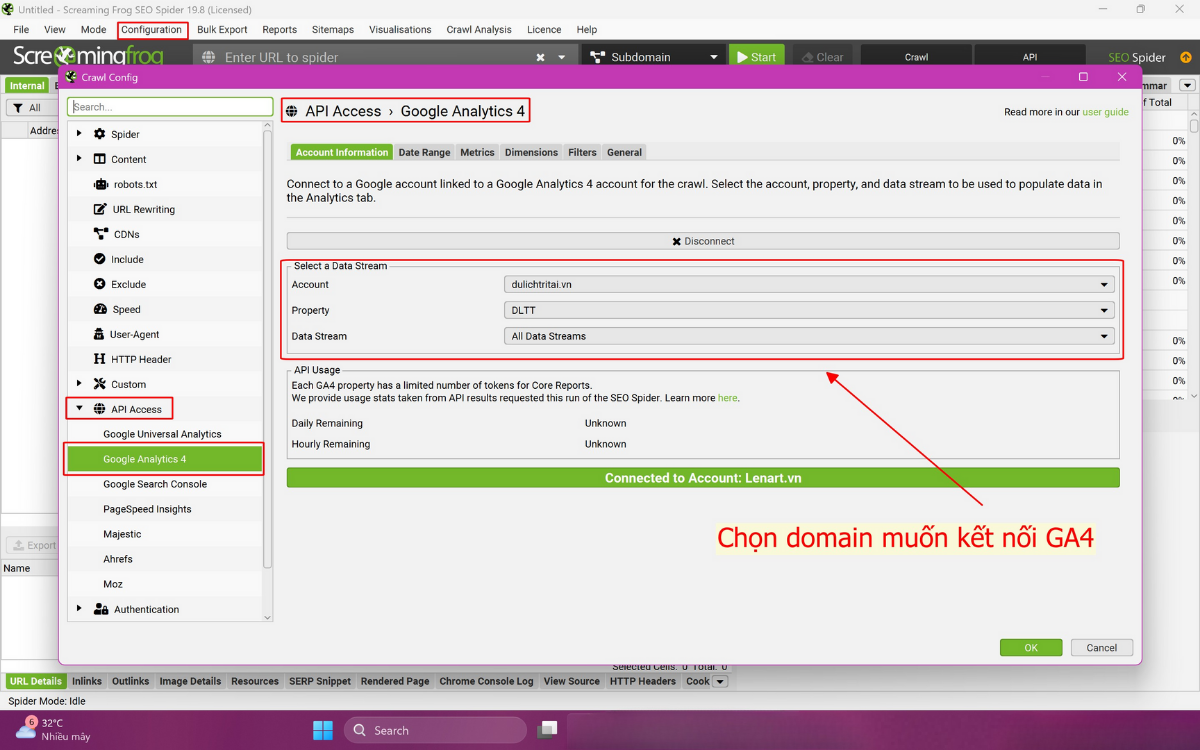
Tiến hành thiết lập kết nối API giữa Screaming Frog và Google Analytics 4 (GA4):
- Vào Configuration > API Access > Google Analytics.
- Nhập property, đảm bảo có quyền truy cập GA property và view của website Lenart.vn.
- Thiết lập date range: ít nhất 1 tháng để có dữ liệu đủ cho phân tích.
- Bật tùy chọn “Crawl New URLs Discovered In Google Analytics” để crawl URL mới phát hiện trong GA.
Bước 3: Kết nối Google Search Console
Mục tiêu chính của việc tích hợp GSC là xác định các Orphan Pages đang có Impressions và Clicks từ kết quả tìm kiếm, nhưng lại thiếu liên kết nội bộ (Internal Link). Đồng thời, lấy dữ liệu hiệu suất về các chỉ số hiệu suất tìm kiếm cốt lõi: Impressions (số lần hiển thị), Clicks (số lần nhấp), CTR (tỷ lệ nhấp) và Average Position (vị trí trung bình) để lên plan.
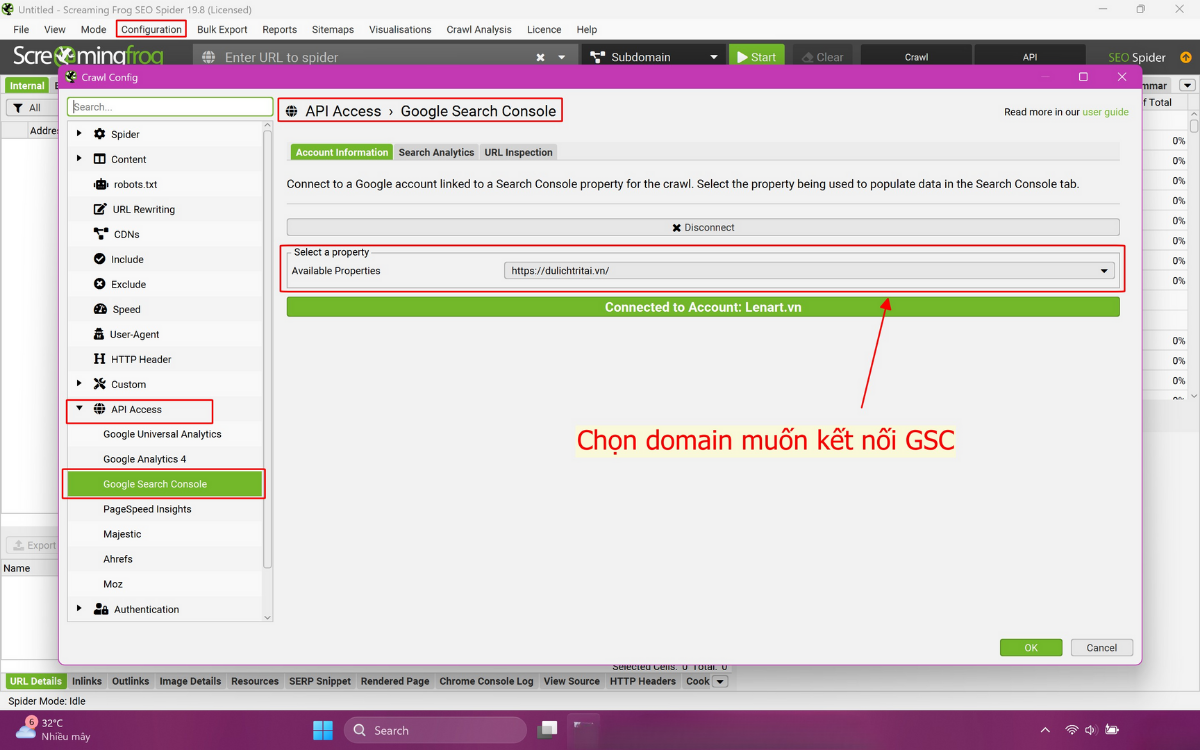
Tiến hành thiết lập API giữa Screaming Frog và Google Search Console:
- Truy cập Cấu Hình API: Vào mục Configuration > API Access > Google Search Console.
- Chọn Property: Lựa chọn chính xác Property của website cần thu thập dữ liệu (crawl). Đảm bảo bạn có quyền truy cập vào Property của website trên Google Search Console.
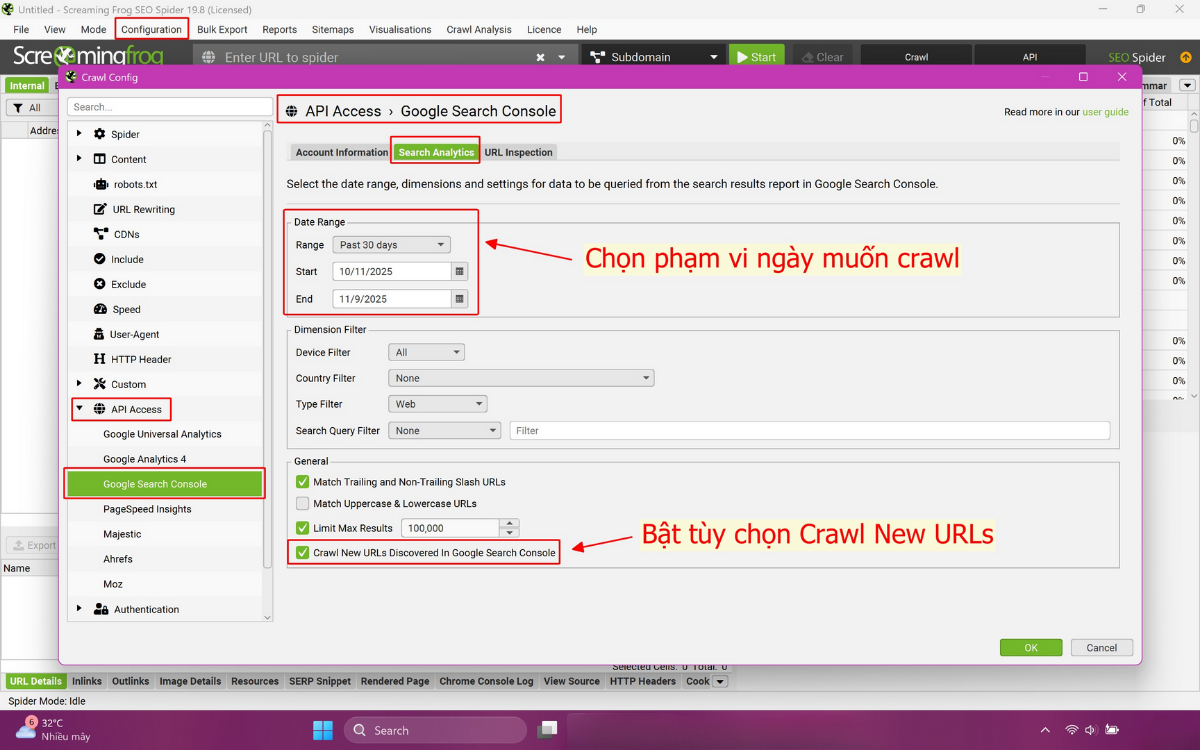
- Thiết lập Phạm Vi Ngày (Date Range): Chọn phạm vi thời gian phân tích tối thiểu 1 tháng để có được bức tranh dữ liệu đầy đủ và đáng tin cậy.
- Tùy chọn Crawl URL Mới: Bật tùy chọn “Crawl New URLs Discovered In Google Search Console” để cho phép công cụ tự động crawl các URL mới được GSC báo cáo.
Bước 4: Crawl Website
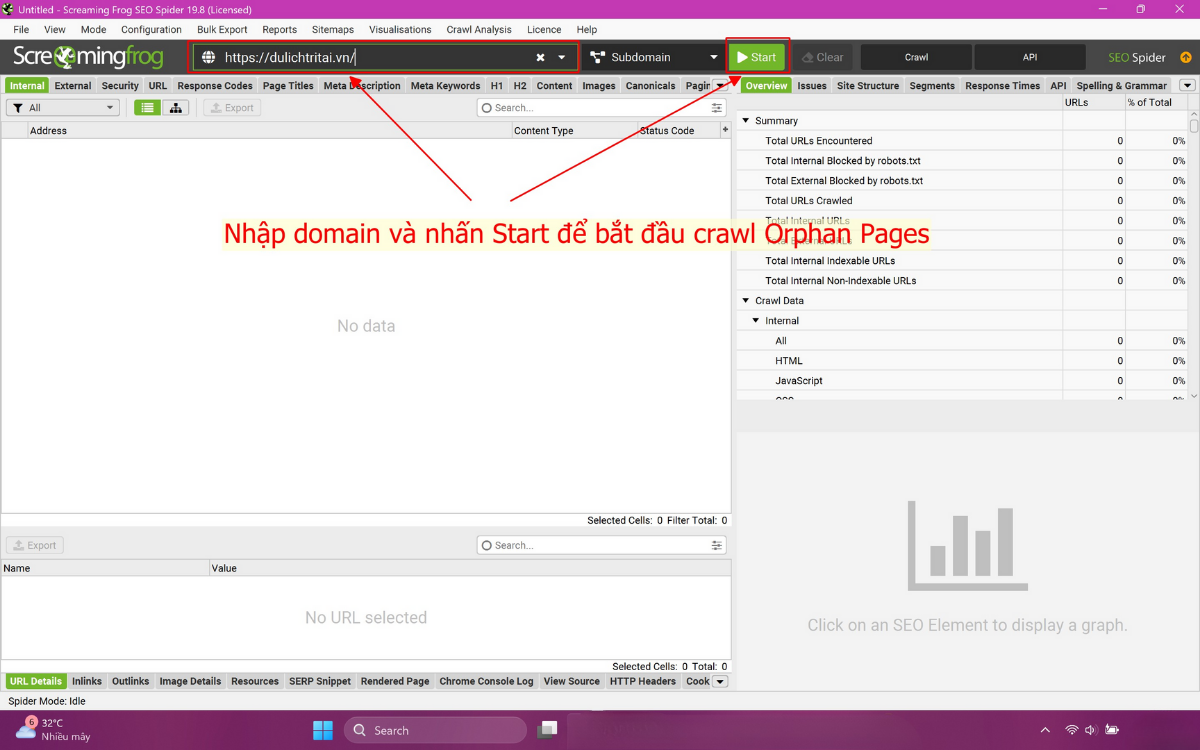
Sau khi đã kết nối API với GA4, GSC, bắt đầu crawl website để tìm orphan pages:
- Nhập URL homepage hoặc domain vào Enter URL to spider → nhấn Start.
- Monitor tiến trình crawl trên tab API và progress bar.
- Screaming Frog sẽ crawl toàn bộ website, Internal Links, sitemap, GA và GSC URL.
Lưu ý: đảm bảo JS và CSS không bị block nếu trang tải hình ảnh hoặc nội dung động.
Bước 5: Chạy Crawl Analysis
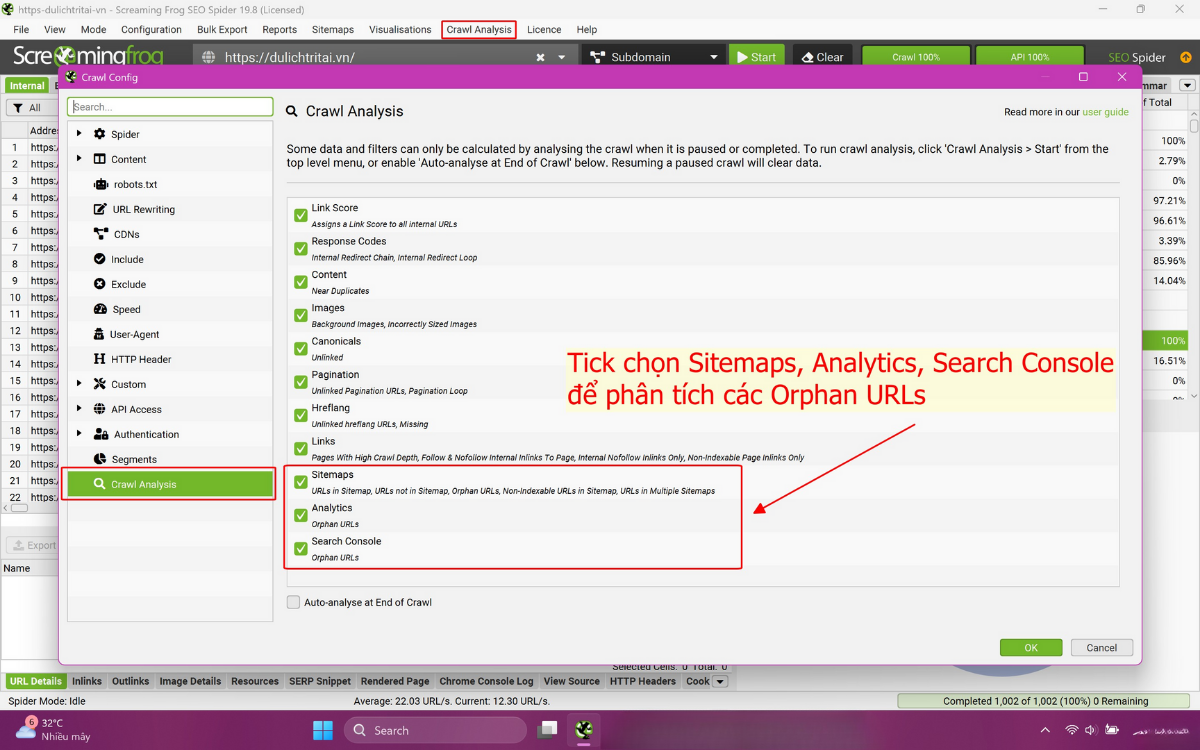
- Sau khi crawl hoàn tất 100% → vào Crawl Analysis > Start.
- Tick Sitemaps, Analytics, Search Console để populate dữ liệu orphan pages.
- Screaming Frog sẽ phân loại các orphan URLs theo nguồn phát hiện.
Bước 6: Phân tích filter Orphan URLs
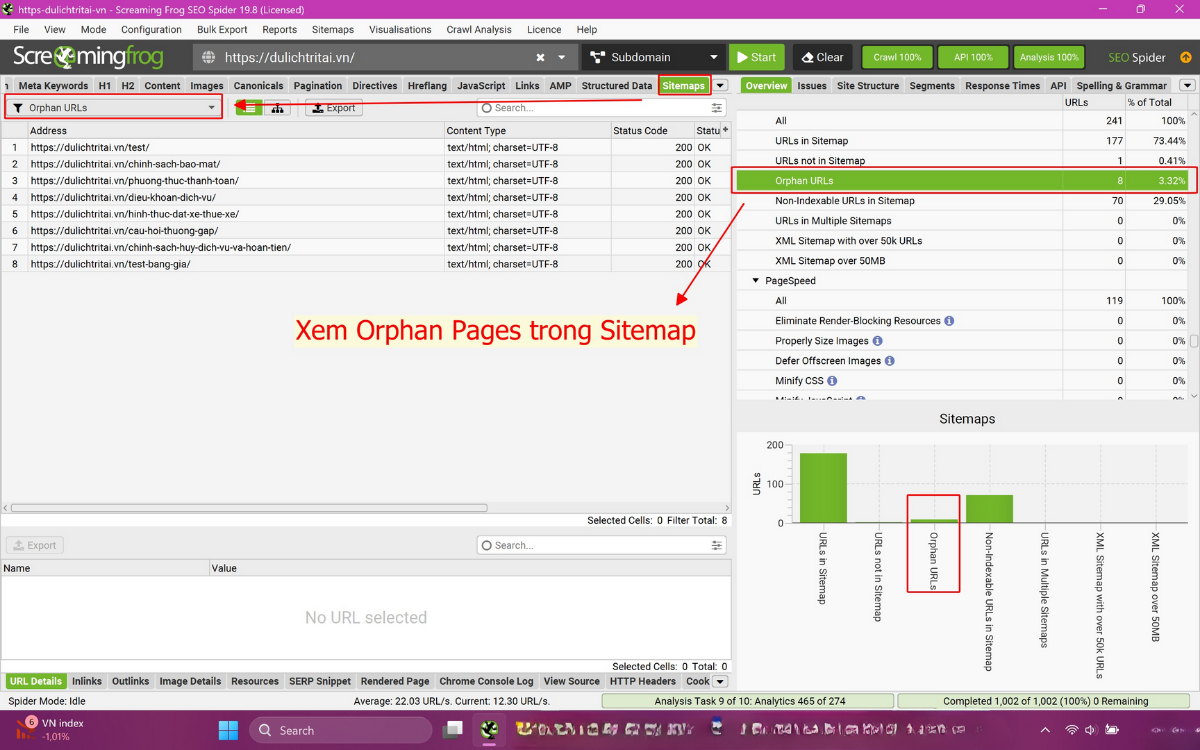
Tab Sitemaps: các URL có trong sitemap nhưng không Internal Link. Ví dụ thực tế: 8 URL từ website Lenart đã test crawl vẫn tồn tại trong sitemap nhưng không được link từ menu hoặc bài viết nào, được Screaming Frog đánh dấu là orphan page.
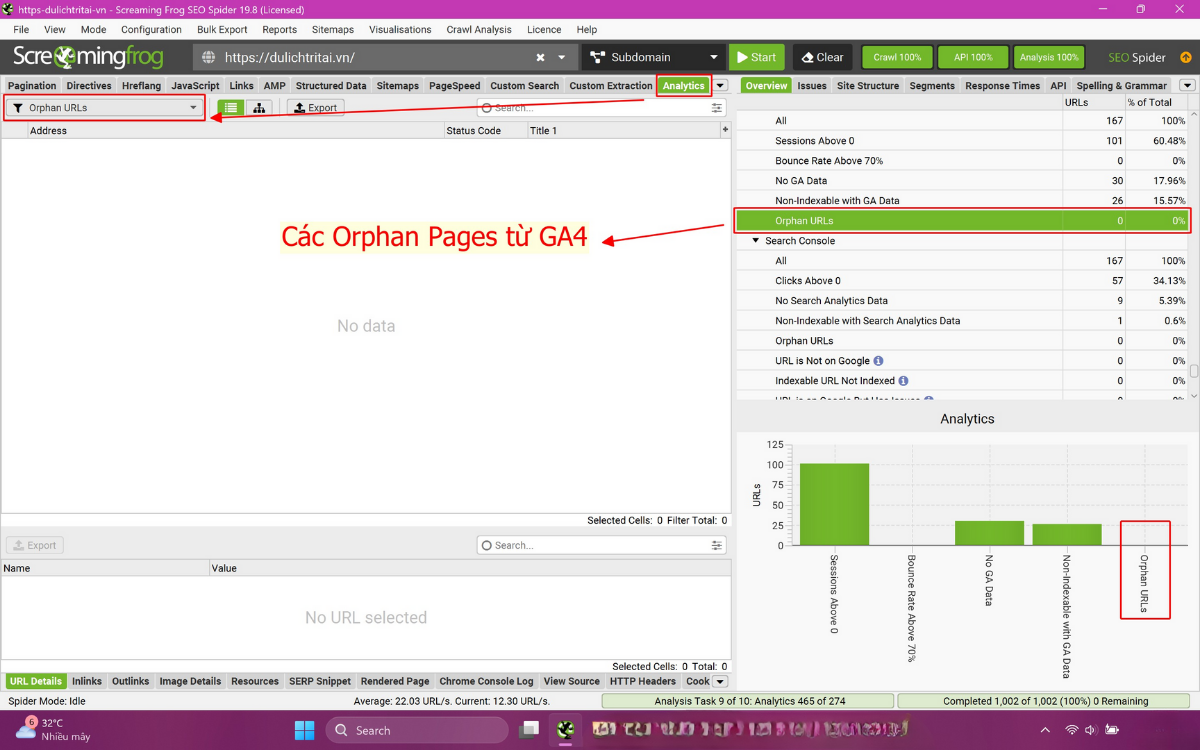
Tab Analytics: các URL nhận organic sessions từ GA nhưng orphan.Ví dụ thực tế: Không có orphan pages nào nhận lược click từ GA4 trong 30 ngày qua.
Tab Search Console: các URL có impressions/clicks nhưng không link nội bộ. Ví dụ thực tế: Không có orphan pages nào nhận lược click hay hiển thị trong 30 ngày gần nhất từ GSC.
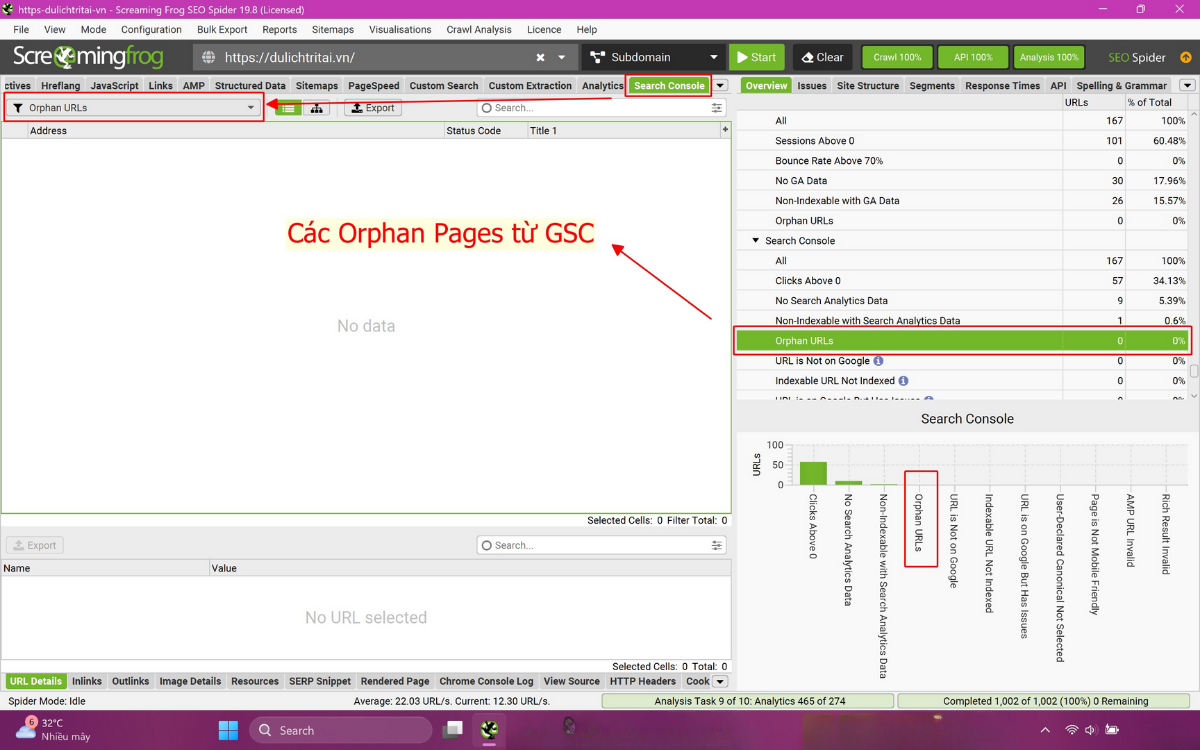
Bước 7: Xác định orphan pages bằng crawl depth
Trong tab Internal, filter các URL có blank crawl depth. Các URL này là orphan page vì không được bot crawl nội bộ tìm thấy từ homepage.
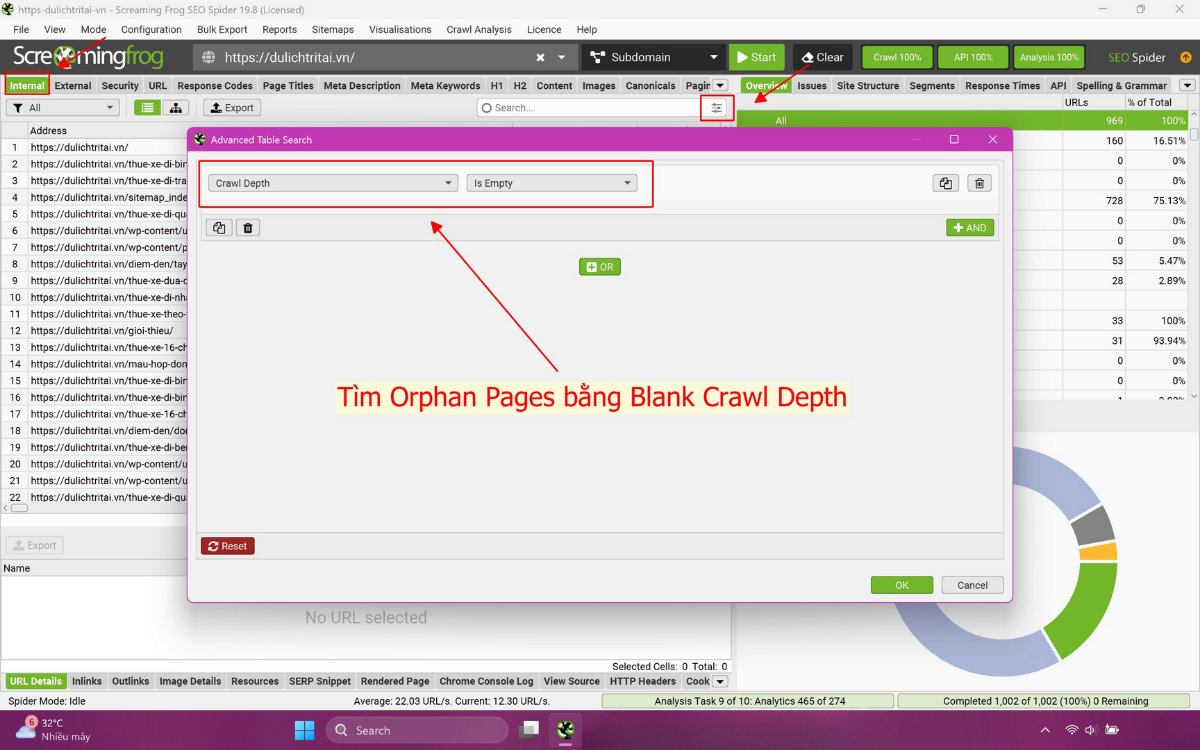
Bước 8: Ưu tiên xử lý các orphan pages
Sau khi đã xác định chính xác các Orphan Pages, bước tiếp theo là áp dụng chiến lược xử lý phù hợp dựa trên giá trị và mục đích của từng trang. Các phương án xử lý chính bao gồm:
- Delete: Đối với các URL bị lỗi (trả về trạng thái 404/410) hoặc các trang có chất lượng thấp, “thin content” (nội dung mỏng, không giá trị) không cần thiết phải lập chỉ mục, bạn nên xóa và loại bỏ chúng.
- Redirect: Nếu URL cũ vẫn nhận được traffic hoặc có liên kết ngoài giá trị, nhưng nội dung đã được thay thế hoặc nâng cấp, hãy thiết lập chuyển hướng 301 sang một trang mới hoặc trang có nội dung tương tự nhất.
- Re-link: Đây là hành động quan trọng nhất. Đối với những Orphan Pages quan trọng, có giá trị SEO và tiềm năng xếp hạng, bạn cần bổ sung Internal Link từ các trang có thẩm quyền (như các Pillar Pages hoặc Menu chính) để truyền PageRank và tái kết nối chúng vào cấu trúc website.
- Noindex: Đối với các trang cần phải tồn tại trên website nhưng không phục vụ mục đích SEO (ví dụ: các trang “Cảm ơn – thank-you pages,” “Chính sách bảo mật – privacy policy”), hãy sử dụng thẻ “noindex” để ngăn Google lập chỉ mục chúng, tránh làm loãng giá trị SEO.
Bước 9: Xuất báo cáo tổng hợp
Bước cuối cùng là tổng hợp dữ liệu để chuyển giao cho các bộ phận liên quan (Content, Development).
- Xuất Báo Cáo Orphan Pages: Truy cập mục Reports > Orphan Pages trong Screaming Frog, sau đó xuất file CSV/GG Sheet chứa tất cả các Orphan Pages được phát hiện từ ba nguồn: Sitemaps, Google Analytics, và Google Search Console.
- Phân Loại Nguồn Dữ Liệu: Đảm bảo cột “Source” trong báo cáo được ghi rõ ràng là GA, GSC hoặc Sitemap.
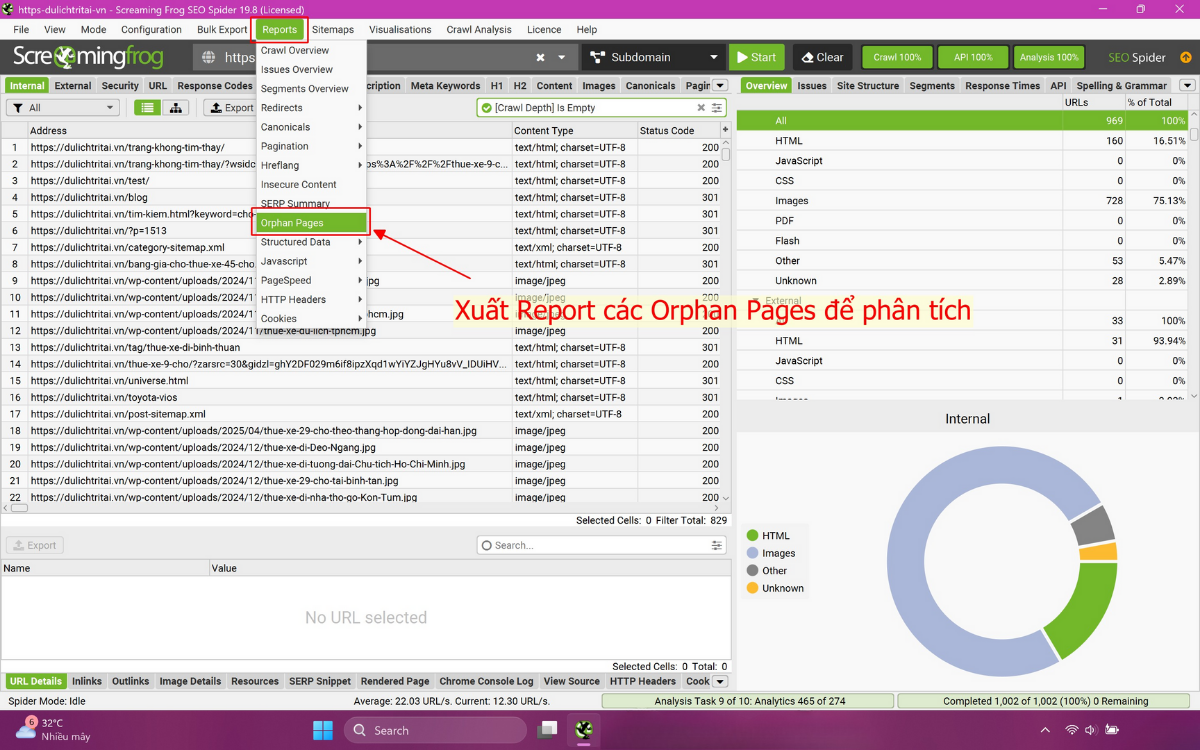
Báo cáo chi tiết này sẽ cung cấp dữ liệu chính xác và đầy đủ, cho phép đội ngũ Content và Development của Lenart thực hiện các hành động xử lý đã được ưu tiên, bao gồm: lập kế hoạch Internal Linking chiến lược, thực hiện các lệnh redirect 301, hoặc tiến hành xóa các trang không cần thiết.
Checklist xử lý Orphan Pages chi tiết theo Lenart.vn
Để xử lý Orphan Pages một cách triệt để và hiệu quả, LENART xây dựng một checklist chi tiết, bao gồm các bước phân loại, ưu tiên và hành động cụ thể cho từng URL. Quy trình này nhằm đảm bảo mọi trang quan trọng đều được liên kết nội bộ (Internal Link) đúng cách, các trang lỗi hoặc kém giá trị được xử lý phù hợp, qua đó tối ưu hóa hiệu suất SEO tổng thể.
Bước 1: Thu thập dữ liệu Orphan Pages
Đây là bước tạo danh sách cơ sở dữ liệu chi tiết, không để sót bất kỳ URL quan trọng nào. Thực hiện xuất báo cáo Orphan Pages từ công cụ Screaming Frog SEO Spider với các trường dữ liệu thiết yếu:
- Source: Ghi rõ URL được phát hiện từ Sitemap, Google Analytics (GA), hay Google Search Console (GSC).
- Status Code: Ghi nhận trạng thái HTTP hiện tại (ví dụ: 200 OK, 301 Redirect, 404 Not Found, 410 Gone).
- Dữ liệu Hiệu suất GA: Thu thập số liệu Organic Sessions (Traffic) từ Google Analytics.
- Dữ liệu Hiệu suất GSC: Thu thập chỉ số Impressions và CTR từ Google Search Console.
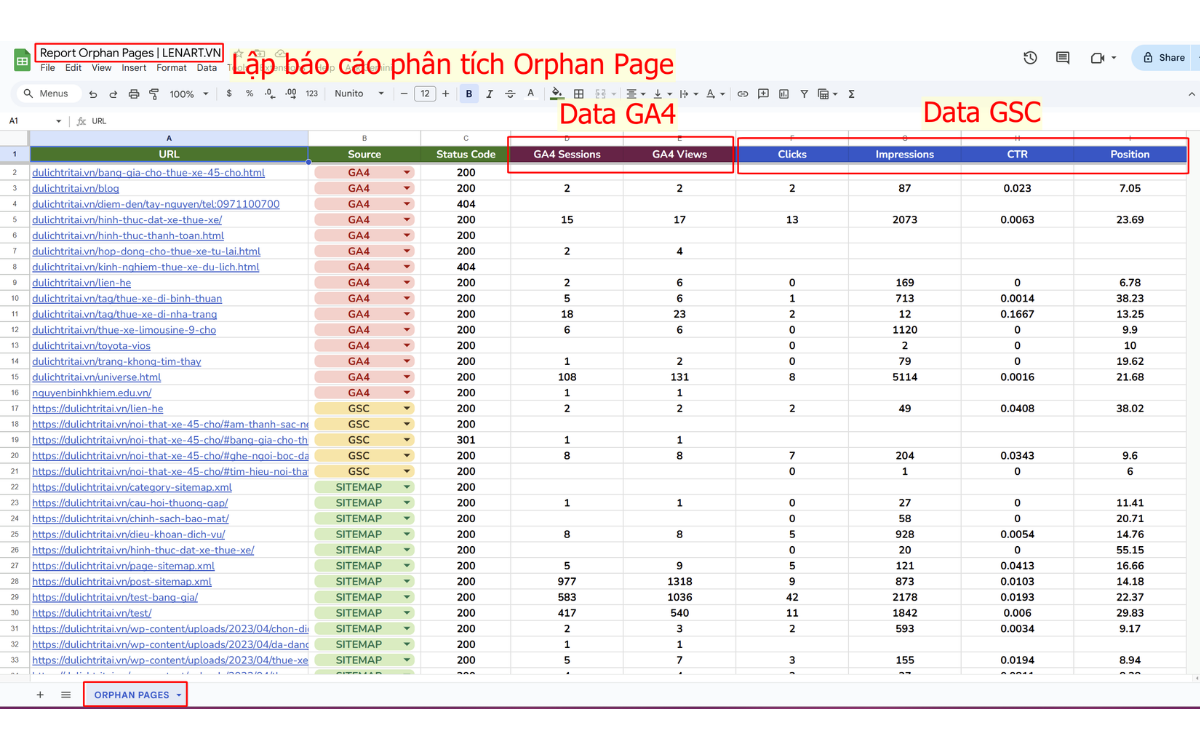
Báo cáo này là nền tảng vững chắc để tiến hành phân loại và đưa ra quyết định hành động trong các bước tiếp theo.
Bước 2: Phân loại orphan pages
Sau khi có dữ liệu tổng hợp, tiến hành phân loại các trang mồ côi thành ba nhóm ưu tiên dựa trên hiệu suất và giá trị chiến lược của chúng:
- High Priority (Quan trọng, có traffic, giá trị SEO):
- Nhận traffic organic >50 sessions/tháng
- Có CTR tốt, impressions từ GSC >100/tháng
- Nội dung quan trọng cho website (pillar page, blog guide, landing page dịch vụ)
- Medium Priority (Có thể SEO, ít traffic):
- Nhận traffic organic <50 sessions/tháng
- Nội dung hỗ trợ, secondary page, case study cũ
- Low Priority (Trang ít giá trị, lỗi hoặc hết hạn):
- 404/410, thin content, test page, old job postings, sản phẩm hết hàng
- Không traffic, không impressions từ GSC
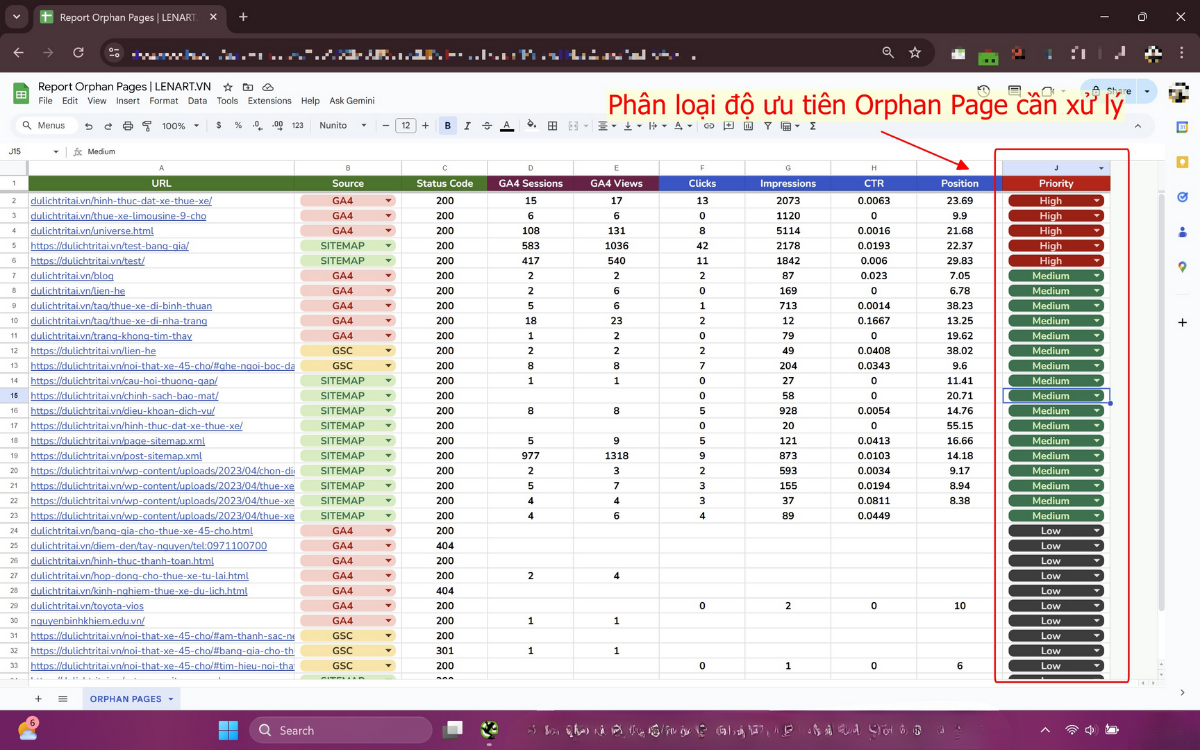
Bước 3: Action cho từng loại
Sau khi đã phân loại các Orphan Pages theo mức độ ưu tiên, bước tiếp theo là xác định hành động cụ thể cho từng nhóm, nhằm đảm bảo mọi trang đều được xử lý tối ưu để cải thiện cấu trúc và hiệu suất SEO tổng thể:
| Priority | Action | Chi tiết |
| High | Re-link | Internal link từ menu, blog hoặc pillar pages. Bổ sung CTA nếu phù hợp. |
| High | Update content | Cập nhật nội dung để cải thiện trải nghiệm và SEO. |
| Medium | Re-link / Noindex | Nếu còn giá trị, re-link vào các page liên quan; nếu không, noindex để tránh index bừa bãi. |
| Low | Redirect / Delete | Redirect sang page tương tự hoặc xóa page. Nếu redirect không phù hợp, sử dụng noindex hoặc xóa hoàn toàn. |
Bước 4: Kiểm tra PageRank & Internal Link
Sau khi thực hiện hành động liên kết lại (re-link) các Orphan Pages quan trọng, cần tiến hành kiểm tra để xác nhận hiệu quả của việc bổ sung Internal Link:
- Kiểm tra Crawl Depth: Sử dụng Screaming Frog để kiểm tra Crawl Depth để đảm bảo các URL này hiện đã được Googlebot tìm thấy thông qua đường dẫn từ Trang Chủ hoặc các Pillar Pages, thay vì bị cô lập.
- Xác nhận Dòng Chảy PageRank: Kiểm tra tab Inlinks trong Screaming Frog để xác nhận rằng trang đã nhận được liên kết nội bộ, qua đó nhận được PageRank (sức mạnh liên kết) và nằm trong cấu trúc thông tin của website.
- Đánh giá Hiệu suất Thực tế: Sau 1–2 tháng, sử dụng GA và GSC để đánh giá sự cải thiện về Traffic (Sessions) và Impressions của các trang đã được re-link.
Bước 5: Lập báo cáo định kỳ
Việc lập báo cáo rõ ràng giúp theo dõi tiến độ và giao tiếp hiệu quả giữa các đội nhóm:
- Xuất Báo Cáo Xử Lý: Xuất báo cáo tổng hợp danh sách các Orphan Pages đã được xử lý xong và danh sách các trang còn tồn đọng cần theo dõi tiếp.
- Ghi chú Trạng thái Hành động: Ghi lại trạng thái hành động cụ thể cho từng URL, ví dụ: Re-linked (đã liên kết lại), Redirected (đã chuyển hướng), Noindexed (đã chặn lập chỉ mục), hoặc Deleted (đã xóa).
Báo cáo này cung cấp dữ liệu minh bạch, giúp team SEO và Development của LENART quản trị website hiệu quả hơn và ngăn chặn sự phát sinh của các Orphan Pages mới.
Bước 6: Đặt lịch kiểm tra định kỳ
Để duy trì cấu trúc website tối ưu, quy trình kiểm tra Orphan Pages của LENART được thực hiện thường xuyên:
- Tần suất Audit: Thiết lập lịch thực hiện audit Orphan Pages định kỳ (thường là 3–6 tháng/lần), tùy thuộc vào quy mô và tốc độ phát triển nội dung của website.
- Kiểm tra Toàn diện: Kiểm tra lại Sitemap, rà soát Internal Links, và dữ liệu từ GA/GSC để nhanh chóng phát hiện các trang mồ côi mới xuất hiện.
- Mục tiêu Cuối cùng: Đảm bảo mọi trang quan trọng luôn được Internal Link đầy đủ, và các trang ít giá trị được xử lý kịp thời để duy trì hiệu suất SEO bền vững.
Quản lý orphan pages là bước thiết yếu trong chiến lược SEO kỹ thuật, giúp Lenart.vn duy trì website gọn gàng, tối ưu PageRank và tăng hiệu quả crawl budget. Việc phát hiện, phân loại và xử lý các trang mồ côi không chỉ nâng cao thứ hạng từ khóa mà còn cải thiện trải nghiệm người dùng và quản trị nội dung chuyên nghiệp. Bằng việc kết hợp Screaming Frog SEO Spider với dữ liệu từ Google Analytics, Google Search Console và XML Sitemap, mọi orphan page đều được kiểm soát và xử lý đúng cách, đảm bảo website luôn vận hành hiệu quả và mang lại giá trị bền vững cho doanh nghiệp.
Tác giả: Minh Châu – Nhân sự Technical SEO LENART